first commit
This commit is contained in:
parent
2e8736a058
commit
0272dd2d6c
BIN
daliy_note/.DS_Store
vendored
Normal file
BIN
daliy_note/.DS_Store
vendored
Normal file
Binary file not shown.
44
daliy_note/10.12/Prometheus写入victoriaMetrics集群.md
Normal file
44
daliy_note/10.12/Prometheus写入victoriaMetrics集群.md
Normal file
@ -0,0 +1,44 @@
|
||||
将Prometheus数据写入VictoriaMetrics集群与单节点的配置略有不同,因为集群模式需要考虑多节点的协调和数据分片。VictoriaMetrics集群由多个组成部分,比如vminsert、vmstorage和vmselect,确保数据的高可用性和性能。以下是如何配置Prometheus以写入VictoriaMetrics集群的步骤:
|
||||
|
||||
### VictoriaMetrics集群架构
|
||||
|
||||
1. **vminsert**:负责接收数据写入请求,并将数据分发到vmstorage节点。
|
||||
2. **vmstorage**:负责实际的数据存储。
|
||||
3. **vmselect**:负责处理查询请求,从vmstorage中读取数据。
|
||||
|
||||
### 配置Prometheus写入VictoriaMetrics集群
|
||||
|
||||
1. **配置Prometheus Remote Write**:
|
||||
- 在Prometheus的配置文件`prometheus.yml`中,配置`remote_write`以指向vminsert节点。通常,你会有多个vminsert节点用于负载均衡。
|
||||
|
||||
```yaml
|
||||
remote_write:
|
||||
- url: "http://vminsert-1.example.com:8480/insert/0/prometheus/"
|
||||
- url: "http://vminsert-2.example.com:8480/insert/0/prometheus/"
|
||||
# 添加更多的vminsert节点以实现负载均衡和高可用性
|
||||
```
|
||||
|
||||
2. **配置负载均衡(可选)**:
|
||||
- 你可以使用负载均衡器(如Nginx、HAProxy等)来分发到多个vminsert节点,以简化Prometheus的配置和提升集群的可用性。
|
||||
|
||||
3. **确保网络连接**:
|
||||
- 确保Prometheus服务器可以访问到所有配置的vminsert节点,检查网络连接和防火墙设置。
|
||||
|
||||
4. **监控和日志检查**:
|
||||
- 检查Prometheus和VictoriaMetrics集群的日志,确保数据正确写入。如果有错误日志,及时排查和解决。
|
||||
|
||||
### 其他注意事项
|
||||
|
||||
- **数据一致性和分片**:
|
||||
- 在VictoriaMetrics集群中,vminsert会自动处理数据分片和一致性,你无需特别配置。
|
||||
|
||||
- **高可用性**:
|
||||
- 确保每个组件(vminsert、vmstorage、vmselect)都有多个实例,以避免单点故障。
|
||||
|
||||
- **资源配置**:
|
||||
- 监控每个节点的CPU、内存和磁盘使用情况,确保资源充足以处理高负载。
|
||||
|
||||
- **集群管理**:
|
||||
- 定期更新和维护VictoriaMetrics集群,应用安全补丁和新特性。
|
||||
|
||||
通过上述配置,你可以实现将Prometheus的数据高效地写入VictoriaMetrics集群,并充分利用其高性能和高可用性的优势。根据你的具体负载和环境,调整节点数量和配置以实现最佳性能。
|
||||
47
daliy_note/10.12/VictoriaMetrics租户.md
Normal file
47
daliy_note/10.12/VictoriaMetrics租户.md
Normal file
@ -0,0 +1,47 @@
|
||||
在VictoriaMetrics中,多租户支持是通过租户ID来实现的。VictoriaMetrics本身并不需要显式地“添加”或“创建”租户。相反,租户是通过在写入和查询请求中使用不同的租户ID来实现的。这使得租户管理非常灵活和简单。
|
||||
|
||||
### 如何使用多租户功能
|
||||
|
||||
1. **写入数据到指定租户**
|
||||
|
||||
当你将数据写入VictoriaMetrics时,可以通过在请求URL中指定租户ID来区分数据属于哪个租户。例如:
|
||||
|
||||
- 默认租户(ID为0):
|
||||
|
||||
```plaintext
|
||||
http://vminsert.example.com:8480/insert/0/prometheus/
|
||||
```
|
||||
|
||||
- 自定义租户(ID为123):
|
||||
|
||||
```plaintext
|
||||
http://vminsert.example.com:8480/insert/123/prometheus/
|
||||
```
|
||||
|
||||
在这个例子中,`123`是自定义的租户ID。你可以根据需要选择任意整数作为租户ID。
|
||||
|
||||
2. **查询特定租户的数据**
|
||||
|
||||
当查询数据时,也需要在查询请求中指定租户ID,以确保查询的是正确的数据集。对于Prometheus兼容的查询API,你可以这样指定:
|
||||
|
||||
- 查询默认租户的数据:
|
||||
|
||||
```plaintext
|
||||
http://vmselect.example.com:8481/select/0/prometheus/api/v1/query?query=...
|
||||
```
|
||||
|
||||
- 查询租户`123`的数据:
|
||||
|
||||
```plaintext
|
||||
http://vmselect.example.com:8481/select/123/prometheus/api/v1/query?query=...
|
||||
```
|
||||
|
||||
### 重要注意事项
|
||||
|
||||
- **租户ID是逻辑概念**:VictoriaMetrics没有像传统数据库那样的租户“创建”过程。租户ID的使用仅仅是通过在请求中指定不同的ID来实现数据的逻辑隔离。
|
||||
|
||||
- **权限管理**:原生的VictoriaMetrics不包含复杂的权限管理系统。如果需要对租户进行权限或安全管理,通常需要在应用层或者通过其他工具(如反向代理或API网关)来实现。
|
||||
|
||||
- **数据隔离**:使用不同的租户ID确保数据的存储和查询是隔离的,但物理上数据仍然可能存储在同一个数据库集群中。
|
||||
|
||||
通过这种简单的机制,VictoriaMetrics可以轻松地支持多租户环境,而无需复杂的配置和管理。
|
||||
44
daliy_note/10.12/grafana读取VictoriaMetrics集群数据.md
Normal file
44
daliy_note/10.12/grafana读取VictoriaMetrics集群数据.md
Normal file
@ -0,0 +1,44 @@
|
||||
将Prometheus数据写入VictoriaMetrics集群与单节点的配置略有不同,因为集群模式需要考虑多节点的协调和数据分片。VictoriaMetrics集群由多个组成部分,比如vminsert、vmstorage和vmselect,确保数据的高可用性和性能。以下是如何配置Prometheus以写入VictoriaMetrics集群的步骤:
|
||||
|
||||
### VictoriaMetrics集群架构
|
||||
|
||||
1. **vminsert**:负责接收数据写入请求,并将数据分发到vmstorage节点。
|
||||
2. **vmstorage**:负责实际的数据存储。
|
||||
3. **vmselect**:负责处理查询请求,从vmstorage中读取数据。
|
||||
|
||||
### 配置Prometheus写入VictoriaMetrics集群
|
||||
|
||||
1. **配置Prometheus Remote Write**:
|
||||
- 在Prometheus的配置文件`prometheus.yml`中,配置`remote_write`以指向vminsert节点。通常,你会有多个vminsert节点用于负载均衡。
|
||||
|
||||
```yaml
|
||||
remote_write:
|
||||
- url: "http://vminsert-1.example.com:8480/insert/0/prometheus/"
|
||||
- url: "http://vminsert-2.example.com:8480/insert/0/prometheus/"
|
||||
# 添加更多的vminsert节点以实现负载均衡和高可用性
|
||||
```
|
||||
|
||||
2. **配置负载均衡(可选)**:
|
||||
- 你可以使用负载均衡器(如Nginx、HAProxy等)来分发到多个vminsert节点,以简化Prometheus的配置和提升集群的可用性。
|
||||
|
||||
3. **确保网络连接**:
|
||||
- 确保Prometheus服务器可以访问到所有配置的vminsert节点,检查网络连接和防火墙设置。
|
||||
|
||||
4. **监控和日志检查**:
|
||||
- 检查Prometheus和VictoriaMetrics集群的日志,确保数据正确写入。如果有错误日志,及时排查和解决。
|
||||
|
||||
### 其他注意事项
|
||||
|
||||
- **数据一致性和分片**:
|
||||
- 在VictoriaMetrics集群中,vminsert会自动处理数据分片和一致性,你无需特别配置。
|
||||
|
||||
- **高可用性**:
|
||||
- 确保每个组件(vminsert、vmstorage、vmselect)都有多个实例,以避免单点故障。
|
||||
|
||||
- **资源配置**:
|
||||
- 监控每个节点的CPU、内存和磁盘使用情况,确保资源充足以处理高负载。
|
||||
|
||||
- **集群管理**:
|
||||
- 定期更新和维护VictoriaMetrics集群,应用安全补丁和新特性。
|
||||
|
||||
通过上述配置,你可以实现将Prometheus的数据高效地写入VictoriaMetrics集群,并充分利用其高性能和高可用性的优势。根据你的具体负载和环境,调整节点数量和配置以实现最佳性能。
|
||||
49
daliy_note/10.14/linux&&macos查看文件夹大小.md
Normal file
49
daliy_note/10.14/linux&&macos查看文件夹大小.md
Normal file
@ -0,0 +1,49 @@
|
||||
在macOS上,你可以使用`du`命令来统计当前文件夹及其子文件夹的磁盘空间使用情况。这里有几个常用的命令选项可以帮助你实现这一目标:
|
||||
|
||||
### 使用 `du` 命令
|
||||
|
||||
1. **显示当前文件夹及其子文件夹的磁盘使用情况**
|
||||
|
||||
打开“终端”应用程序,然后导航到你想要检查的目录,或者直接在终端中输入以下命令:
|
||||
|
||||
```bash
|
||||
du -h
|
||||
```
|
||||
|
||||
这个命令会递归地显示当前目录及其所有子目录的磁盘使用情况,`-h`选项将结果以人类可读的格式(如KB、MB、GB)显示。
|
||||
|
||||
2. **显示当前文件夹及其子文件夹的总磁盘使用情况**
|
||||
|
||||
如果你只想查看当前目录及其子目录的总磁盘使用情况,而不需要详细的目录列表,可以使用:
|
||||
|
||||
```bash
|
||||
du -sh
|
||||
```
|
||||
|
||||
这里,`-s`选项表示“summary”,即只显示总计的大小。
|
||||
|
||||
3. **显示指定层级的子目录磁盘使用情况**
|
||||
|
||||
如果你想限制显示的目录层级,可以使用`--max-depth`选项。例如:
|
||||
|
||||
```bash
|
||||
du -h --max-depth=1
|
||||
```
|
||||
|
||||
这个命令会显示当前目录下的每个子目录的磁盘使用情况,但不再深入子目录的子目录。
|
||||
|
||||
### 示例
|
||||
|
||||
假设你在终端中导航到某个目录,并运行`du -sh`,输出可能类似于:
|
||||
|
||||
```plaintext
|
||||
1.2G .
|
||||
```
|
||||
|
||||
这表示当前目录及其所有子目录总共占用了1.2GB的磁盘空间。
|
||||
|
||||
### 其他注意事项
|
||||
|
||||
- `du`命令可能需要一些时间来计算特别是对于包含大量文件或大文件的目录。
|
||||
- 权限问题可能会导致`du`无法访问某些目录。在这种情况下,可能需要使用`sudo`来提升权限,例如:`sudo du -sh`。
|
||||
- 如果你对某些特定文件类型的大小感兴趣,可能需要结合其他命令(如`find`)来实现更复杂的过滤和统计。
|
||||
35
daliy_note/10.15/mongo.md
Normal file
35
daliy_note/10.15/mongo.md
Normal file
@ -0,0 +1,35 @@
|
||||
### docker 部署mongoDB
|
||||
|
||||
```bash
|
||||
docker run -itd -p 27017:27017 -e MONGO_INITDB_ROOT_USERNAME=root -e MONGO_INITDB_ROOT_PASSWORD=123456 --name mongo mongo
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 用root用户登录
|
||||
|
||||
- 解决创建用户报错误问题
|
||||
|
||||
Command createUser requires authentication
|
||||
|
||||
```bash
|
||||
docker exec -it mongo bash # 进入到容器的terminal
|
||||
mongosh --username root --password --authenticationDatabase admin # 认证admin账户
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 给database创建用户’
|
||||
|
||||
```bash
|
||||
use cmdb
|
||||
db.createUser({
|
||||
user: "root",
|
||||
pwd: "123456",
|
||||
roles: [
|
||||
{ role: "readWrite", db: "<database_name>" },
|
||||
{ role: "dbAdmin", db: "<database_name>" }
|
||||
]
|
||||
})
|
||||
```
|
||||
|
||||
45
daliy_note/10.24/context.Context.md
Normal file
45
daliy_note/10.24/context.Context.md
Normal file
@ -0,0 +1,45 @@
|
||||
是的,在 Go 语言中,`context.Context` 是一个接口类型,而接口在 Go 中是引用类型。具体来说,`context.Context` 提供了一种管理请求范围内数据、取消信号和超时的方式,是用于处理并发编程中的上下文信息的常用工具。
|
||||
|
||||
### `context.Context` 基础
|
||||
|
||||
- **接口类型**: `context.Context` 是一个接口,这意味着它定义了一组方法,但不包含数据本身。实现 `context.Context` 接口的具体类型如 `context.Background()` 和 `context.TODO()` 都是引用类型。
|
||||
|
||||
- **常用方法**:
|
||||
- `Deadline() (deadline time.Time, ok bool)`: 返回上下文被取消的时间。
|
||||
- `Done() <-chan struct{}`: 返回一个通道,当上下文被取消或到达截止时间时,该通道会被关闭。
|
||||
- `Err() error`: 返回上下文被取消的原因。
|
||||
- `Value(key interface{}) interface{}`: 从上下文中检索与键关联的值。
|
||||
|
||||
### 使用 `context.Context`
|
||||
|
||||
`context.Context` 通常用于管理请求的生命周期,特别是在处理 HTTP 请求、RPC 调用或其他需要在一段时间内传递上下文信息的操作时。
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
"fmt"
|
||||
"time"
|
||||
)
|
||||
|
||||
func main() {
|
||||
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
|
||||
defer cancel()
|
||||
|
||||
select {
|
||||
case <-time.After(1 * time.Second):
|
||||
fmt.Println("operation completed")
|
||||
case <-ctx.Done():
|
||||
fmt.Println("timeout:", ctx.Err())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 传递和取消
|
||||
|
||||
- **传递引用**: 因为 `context.Context` 是引用类型,所以通常将它作为第一个参数传递给需要上下文信息的函数。这是因为引用类型允许在多个函数间共享同一个上下文实例。
|
||||
|
||||
- **取消操作**: 通过使用例如 `context.WithCancel` 和 `context.WithTimeout` 等函数,可以生成一个可取消的上下文,并在操作完成或超时时调用取消函数。
|
||||
|
||||
总之,`context.Context` 的设计使其适合用于并发编程中传递请求范围内的信息和取消信号,并且由于它是引用类型,传递它时不会产生额外的复制开销。
|
||||
66
daliy_note/10.24/vim打开文件乱码.md
Normal file
66
daliy_note/10.24/vim打开文件乱码.md
Normal file
@ -0,0 +1,66 @@
|
||||
当你使用 Vim 打开文件时遇到乱码问题,通常是由于文件编码和 Vim 的默认编码不匹配造成的。以下是一些常见的解决方案:
|
||||
|
||||
### 1. 检查文件的实际编码
|
||||
|
||||
首先,你需要知道文件的实际编码是什么。你可以使用以下命令来检查文件的编码:
|
||||
|
||||
#### 在 Linux 或 macOS 上
|
||||
|
||||
```bash
|
||||
file -i filename
|
||||
```
|
||||
|
||||
这将输出文件的 MIME 类型和编码,比如 `text/plain; charset=utf-8`。
|
||||
|
||||
### 2. 设置 Vim 的编码
|
||||
|
||||
一旦知道了文件的实际编码,你可以在 Vim 中设置相应的编码来正确显示文件内容。
|
||||
|
||||
#### 在 Vim 中设置编码
|
||||
|
||||
打开 Vim 后,输入以下命令来设置文件的编码:
|
||||
|
||||
```vim
|
||||
:e ++enc=<encoding>
|
||||
```
|
||||
|
||||
例如,如果文件是以 UTF-8 编码的,你可以输入:
|
||||
|
||||
```vim
|
||||
:e ++enc=utf-8
|
||||
```
|
||||
|
||||
### 3. 修改 Vim 配置文件
|
||||
|
||||
如果你经常遇到编码问题,可以考虑修改 Vim 的配置文件(通常是 `~/.vimrc`)来设置默认编码。
|
||||
|
||||
在 `~/.vimrc` 中添加以下行,可以设置 Vim 的默认编码为 UTF-8:
|
||||
|
||||
```vim
|
||||
set encoding=utf-8
|
||||
set fileencodings=utf-8,gbk,latin1
|
||||
```
|
||||
|
||||
这样,Vim 会优先尝试使用 UTF-8 打开文件,如果不匹配则尝试 GBK 和 Latin1。
|
||||
|
||||
### 4. 使用 iconv 转换文件编码
|
||||
|
||||
如果文件编码不常见,或者你需要将文件转换为另一种编码,可以使用 `iconv` 工具。
|
||||
|
||||
#### 转换文件编码
|
||||
|
||||
```bash
|
||||
iconv -f <source-encoding> -t <target-encoding> <input-file> -o <output-file>
|
||||
```
|
||||
|
||||
例如,将一个 GBK 编码的文件转换为 UTF-8:
|
||||
|
||||
```bash
|
||||
iconv -f gbk -t utf-8 input.txt -o output.txt
|
||||
```
|
||||
|
||||
### 5. 确保终端支持相应编码
|
||||
|
||||
有时候问题可能出在终端模拟器上。确保你的终端设置为支持文件的编码,特别是 UTF-8,这是大多数现代终端模拟器的默认设置。
|
||||
|
||||
通过以上步骤,你应该能够解决 Vim 打开文件时的乱码问题。如果问题仍然存在,可能需要确认文件本身是否损坏或尝试其他工具来检查文件内容。
|
||||
42
daliy_note/10.24/waitgroup.md
Normal file
42
daliy_note/10.24/waitgroup.md
Normal file
@ -0,0 +1,42 @@
|
||||
在 Go 语言中,你可以传递 `sync.WaitGroup` 的指针。这在并发编程中是一个常见的模式,因为 `sync.WaitGroup` 的方法(如 `Add`、`Done` 和 `Wait`)会修改 `WaitGroup` 的内部状态,所以通常需要通过指针传递以避免复制。
|
||||
|
||||
使用 `sync.WaitGroup` 时,通过指针传递的典型用法如下:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"sync"
|
||||
)
|
||||
|
||||
func worker(id int, wg *sync.WaitGroup) {
|
||||
defer wg.Done() // 确保在 goroutine 完成时调用 Done
|
||||
fmt.Printf("Worker %d starting\n", id)
|
||||
// 模拟工作
|
||||
fmt.Printf("Worker %d done\n", id)
|
||||
}
|
||||
|
||||
func main() {
|
||||
var wg sync.WaitGroup
|
||||
|
||||
for i := 1; i <= 5; i++ {
|
||||
wg.Add(1) // 增加 WaitGroup 的计数器
|
||||
go worker(i, &wg) // 传递 WaitGroup 的指针
|
||||
}
|
||||
|
||||
wg.Wait() // 等待所有 goroutine 完成
|
||||
fmt.Println("All workers done")
|
||||
}
|
||||
```
|
||||
|
||||
### 说明
|
||||
|
||||
- **指针传递**: `worker` 函数接收一个 `*sync.WaitGroup` 类型的参数。这样,所有的 goroutine 都共享同一个 `WaitGroup` 实例,可以正确地递增和递减计数器。
|
||||
|
||||
- **Add、Done 和 Wait**:
|
||||
- `Add(n int)`: 增加等待计数器的值。
|
||||
- `Done()`: 减少等待计数器的值(通常在 goroutine 完成时调用)。
|
||||
- `Wait()`: 阻塞直到等待计数器归零。
|
||||
|
||||
通过这种方式,可以确保主函数会等待所有启动的 goroutine 完成其任务。传递 `sync.WaitGroup` 的指针是 Go 中并发编程的一种惯用方法,确保在多个 goroutine 中正确地共享和管理等待组的状态。
|
||||
6
daliy_note/10.29/git.md
Normal file
6
daliy_note/10.29/git.md
Normal file
@ -0,0 +1,6 @@
|
||||
### git 获取当前分支名
|
||||
|
||||
```bash
|
||||
git branch --show-current
|
||||
```
|
||||
|
||||
8
daliy_note/10.8/linux查看所有硬件设备型号.md
Normal file
8
daliy_note/10.8/linux查看所有硬件设备型号.md
Normal file
@ -0,0 +1,8 @@
|
||||
### lshw
|
||||
|
||||
```bash
|
||||
sudo apt install lshw
|
||||
lshw
|
||||
lshw -short
|
||||
```
|
||||
|
||||
231
daliy_note/10.9/kubernetes admission webhook.md
Normal file
231
daliy_note/10.9/kubernetes admission webhook.md
Normal file
@ -0,0 +1,231 @@
|
||||
`AdmissionWebhook` 是 Kubernetes 中的一种动态准入控制器,用于在请求进入 Kubernetes API 服务器时对其进行修改或验证。准入控制器是 Kubernetes 安全模型的一部分,负责拦截请求并对其进行特定的检查或修改,以确保集群的安全性和策略的一致性。
|
||||
|
||||
### AdmissionWebhook 的作用
|
||||
|
||||
1. **验证(Validating Webhooks)**:
|
||||
- 这些 Webhook 在资源被创建、更新或删除之前对请求进行检查,以确保请求符合某些策略或规则。
|
||||
- 如果验证失败,请求将被拒绝,并返回给用户一个错误信息。
|
||||
|
||||
2. **变更(Mutating Webhooks)**:
|
||||
- 这些 Webhook 可以在请求到达 API 服务器时修改请求对象。
|
||||
- 例如,可以自动填充某些字段,或者根据预定义的规则调整资源配置。
|
||||
|
||||
### 使用场景
|
||||
|
||||
- **策略实施**:确保所有部署的应用程序都符合公司或组织的安全和合规策略。例如,确保所有 Pod 都具有指定的标签或资源限制。
|
||||
- **自动化变更**:自动为资源添加或修改某些属性,例如为每个 Pod 添加一个特定的环境变量。
|
||||
- **资源验证**:在资源被持久化之前,对其进行额外的验证,以防止错误配置。
|
||||
- **审计和日志**:记录和监控特定请求,以帮助进行审计和故障排查。
|
||||
|
||||
### 工作原理
|
||||
|
||||
1. **注册 Webhook**:
|
||||
- 使用 `MutatingWebhookConfiguration` 和 `ValidatingWebhookConfiguration` 资源在 Kubernetes 中注册 Webhook。
|
||||
|
||||
2. **处理请求**:
|
||||
- 当一个请求到达 Kubernetes API 服务器时,配置的 Webhook 会被调用。
|
||||
- Webhook 服务接收到请求对象,执行逻辑并返回一个响应,指示是否允许、拒绝或修改请求。
|
||||
|
||||
3. **响应处理**:
|
||||
- 对于 Mutating Webhook,API 服务器将根据 Webhook 的响应修改请求对象。
|
||||
- 对于 Validating Webhook,API 服务器将检查 Webhook 的响应以决定是否执行请求。
|
||||
|
||||
### 实现示例
|
||||
|
||||
要实现一个 AdmissionWebhook,通常需要以下步骤:
|
||||
|
||||
1. **编写 Webhook 服务器**:
|
||||
- 使用编程语言(例如 Go)编写一个 HTTP 服务器,能够处理 Kubernetes 的 AdmissionReview 请求。
|
||||
|
||||
2. **部署 Webhook 服务**:
|
||||
- 将 Webhook 服务器作为一个 Pod 部署到 Kubernetes 集群中。
|
||||
|
||||
3. **创建 Webhook 配置**:
|
||||
- 编写并应用 `MutatingWebhookConfiguration` 或 `ValidatingWebhookConfiguration`,指向你的 Webhook 服务。
|
||||
|
||||
### 注意事项
|
||||
|
||||
- **安全性**:确保 Webhook 服务的安全性,使用 TLS 进行通信,确保只有经过身份验证的请求才能访问。
|
||||
- **性能影响**:Webhook 会影响 API 请求的延迟,因为请求需要经过 Webhook 的处理。尽量优化 Webhook 的处理逻辑以减少开销。
|
||||
- **故障处理**:设计 Webhook 时需要考虑故障处理,确保 Webhook 不会因为某些错误而导致集群无法正常工作。
|
||||
|
||||
通过使用 AdmissionWebhook,Kubernetes 提供了一个强大的机制来实施自定义策略和自动化配置,帮助运维人员更好地管理和控制集群行为。
|
||||
|
||||
|
||||
|
||||
### 举例
|
||||
|
||||
当然!下面是一个简单的示例,展示如何实现一个 Kubernetes Admission Webhook。这个示例将创建一个简单的 Mutating Admission Webhook,它会在每个 Pod 创建之前向其中添加一个环境变量。
|
||||
|
||||
### 步骤 1: 编写 Webhook 服务器
|
||||
|
||||
我们将用 Go 编写一个简单的 HTTP 服务器,作为我们的 Webhook 服务。
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"net/http"
|
||||
"log"
|
||||
|
||||
admissionv1 "k8s.io/api/admission/v1"
|
||||
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
|
||||
corev1 "k8s.io/api/core/v1"
|
||||
)
|
||||
|
||||
func handleAdmission(w http.ResponseWriter, r *http.Request) {
|
||||
var admissionReviewReq admissionv1.AdmissionReview
|
||||
if err := json.NewDecoder(r.Body).Decode(&admissionReviewReq); err != nil {
|
||||
log.Printf("Could not decode request: %v", err)
|
||||
http.Error(w, "Bad request", http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
podResource := metav1.GroupVersionResource{Group: "", Version: "v1", Resource: "pods"}
|
||||
if admissionReviewReq.Request.Resource != podResource {
|
||||
log.Printf("Expect resource to be %s", podResource)
|
||||
http.Error(w, "Bad request", http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
raw := admissionReviewReq.Request.Object.Raw
|
||||
pod := corev1.Pod{}
|
||||
if err := json.Unmarshal(raw, &pod); err != nil {
|
||||
log.Printf("Could not unmarshal raw object: %v", err)
|
||||
http.Error(w, "Bad request", http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
// 添加环境变量
|
||||
env := corev1.EnvVar{Name: "ADDED_BY_WEBHOOK", Value: "true"}
|
||||
pod.Spec.Containers[0].Env = append(pod.Spec.Containers[0].Env, env)
|
||||
|
||||
// 创建补丁操作
|
||||
patchBytes, err := json.Marshal([]map[string]interface{}{
|
||||
{"op": "add", "path": "/spec/containers/0/env", "value": pod.Spec.Containers[0].Env},
|
||||
})
|
||||
if err != nil {
|
||||
log.Printf("Could not marshal patch: %v", err)
|
||||
http.Error(w, "Bad request", http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
admissionReviewResponse := admissionv1.AdmissionReview{
|
||||
Response: &admissionv1.AdmissionResponse{
|
||||
UID: admissionReviewReq.Request.UID,
|
||||
Allowed: true,
|
||||
Patch: patchBytes,
|
||||
PatchType: func() *admissionv1.PatchType {
|
||||
pt := admissionv1.PatchTypeJSONPatch
|
||||
return &pt
|
||||
}(),
|
||||
},
|
||||
}
|
||||
|
||||
respBytes, err := json.Marshal(admissionReviewResponse)
|
||||
if err != nil {
|
||||
log.Printf("Could not marshal response: %v", err)
|
||||
http.Error(w, "Bad request", http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
w.Header().Set("Content-Type", "application/json")
|
||||
w.Write(respBytes)
|
||||
}
|
||||
|
||||
func main() {
|
||||
http.HandleFunc("/mutate", handleAdmission)
|
||||
log.Println("Starting server on :8080")
|
||||
if err := http.ListenAndServeTLS(":8080", "/path/to/tls.crt", "/path/to/tls.key", nil); err != nil {
|
||||
log.Fatalf("Failed to start server: %v", err)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 步骤 2: 部署 Webhook 服务
|
||||
|
||||
1. **编译和打包服务**:
|
||||
- 将上述代码编译为二进制文件,创建一个 Docker 镜像,并将其推送到容器镜像仓库。
|
||||
|
||||
2. **创建 Kubernetes Deployment 和 Service**:
|
||||
编写一个 YAML 文件,将 Webhook 服务部署到 Kubernetes 集群中。
|
||||
|
||||
```yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: webhook-server
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: webhook-server
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: webhook-server
|
||||
spec:
|
||||
containers:
|
||||
- name: webhook-server
|
||||
image: <your-docker-image>
|
||||
ports:
|
||||
- containerPort: 8080
|
||||
volumeMounts:
|
||||
- name: webhook-certs
|
||||
mountPath: "/etc/webhook/certs"
|
||||
readOnly: true
|
||||
volumes:
|
||||
- name: webhook-certs
|
||||
secret:
|
||||
secretName: webhook-certs
|
||||
---
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: webhook-server
|
||||
spec:
|
||||
ports:
|
||||
- port: 443
|
||||
targetPort: 8080
|
||||
selector:
|
||||
app: webhook-server
|
||||
```
|
||||
|
||||
### 步骤 3: 创建 Webhook 配置
|
||||
|
||||
1. **创建 TLS 证书**:
|
||||
- 为 Webhook 服务创建 TLS 证书,并将其存储在 Kubernetes Secret 中。
|
||||
|
||||
2. **创建 `MutatingWebhookConfiguration`**:
|
||||
编写一个 YAML 文件,为 Kubernetes 注册 Webhook。
|
||||
|
||||
```yaml
|
||||
apiVersion: admissionregistration.k8s.io/v1
|
||||
kind: MutatingWebhookConfiguration
|
||||
metadata:
|
||||
name: pod-mutator
|
||||
webhooks:
|
||||
- name: pod-mutator.example.com
|
||||
clientConfig:
|
||||
service:
|
||||
name: webhook-server
|
||||
namespace: default
|
||||
path: "/mutate"
|
||||
caBundle: <base64-encoded-ca-cert>
|
||||
rules:
|
||||
- operations: ["CREATE"]
|
||||
apiGroups: [""]
|
||||
apiVersions: ["v1"]
|
||||
resources: ["pods"]
|
||||
admissionReviewVersions: ["v1"]
|
||||
sideEffects: None
|
||||
```
|
||||
|
||||
### 注意事项
|
||||
|
||||
- 确保 Webhook 服务的 TLS 证书正确配置,并与 `MutatingWebhookConfiguration` 中的 `caBundle` 匹配。
|
||||
- 此示例只是一个简单的实现,生产环境中需要考虑安全性、性能优化和错误处理等方面。
|
||||
- `caBundle` 应该是你的 CA 证书的 base64 编码。
|
||||
|
||||
通过上述步骤,你可以实现一个简单的 Admission Webhook,它在 Pod 创建时自动添加一个环境变量。这个示例可以作为实现更复杂逻辑的起点。
|
||||
48
daliy_note/11.12/泛域名证书自签发.md
Normal file
48
daliy_note/11.12/泛域名证书自签发.md
Normal file
@ -0,0 +1,48 @@
|
||||
### 一、自签证书
|
||||
|
||||
- 生成CA Key证书
|
||||
|
||||
```bash
|
||||
openssl genrsa 2048 > ca-key.pem
|
||||
```
|
||||
|
||||
- 生成CA Cert证书
|
||||
|
||||
```bash
|
||||
openssl req -new -x509 -nodes -days 3650 -key ca-key.pem -out ca-cert.pem -subj=/C=CN/ST=Beijing/L=Beijing/O=ExampleO/OU=ExampleOU/CN=ExampleRootCA/emailAddress=admin@example.com
|
||||
```
|
||||
|
||||
- 生成server证书签发请求和server private key证书;在此命令中修改CN(Common Name)用来创建域名证书请求
|
||||
|
||||
```bash
|
||||
openssl req -newkey rsa:2048 -nodes -days 3650 -keyout server-key.pem -out server-req.pem -subj=/C=CN/ST=Beijing/L=Beijing/O=ExampleO/OU=ExampleOU/CN=*.example.com/emailAddress=admin@example.com
|
||||
```
|
||||
|
||||
- 签发server证书请求,生成server cert证书;注意修改subjectAltName的值
|
||||
|
||||
```bash
|
||||
openssl x509 -req -extfile <(printf "subjectAltName=DNS:*.example.com") -days 3650 -CAcreateserial -in server-req.pem -out server-cert.pem -CA ca-cert.pem -CAkey ca-key.pem
|
||||
```
|
||||
|
||||
### 二、生成证书报错
|
||||
|
||||
``` bash
|
||||
Can't load ./.rnd into RNG 10504:error:2406F079:random number generator:RAND_load_file:Cannot open file:crypto\rand\randfile.c:98:Filename=./.rnd
|
||||
```
|
||||
|
||||
- 解决方案
|
||||
|
||||
```bash
|
||||
cd /root(你当前所使用的用户)
|
||||
openssl rand -writerand .rnd
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 三、Chrome On MacOS 信任证书
|
||||
|
||||
> https://segmentfault.com/a/1190000012394467
|
||||
|
||||
- chrome控制台,安全tab,查看证书
|
||||
- 查看证书详细信息,导出下载证书
|
||||
- 双击打开下载的证书,选择始终信任
|
||||
1
daliy_note/11.14/mongodb索引.md
Normal file
1
daliy_note/11.14/mongodb索引.md
Normal file
@ -0,0 +1 @@
|
||||
https://blog.51cto.com/u_16099356/11608804
|
||||
6
daliy_note/11.4/docker查看无法运行的镜像内的文件.md
Normal file
6
daliy_note/11.4/docker查看无法运行的镜像内的文件.md
Normal file
@ -0,0 +1,6 @@
|
||||
```bash
|
||||
docker run --rm -it --entrypoint sh manager
|
||||
```
|
||||
|
||||
|
||||
|
||||
208
daliy_note/11.4/kakfa-docker-compose.md
Normal file
208
daliy_note/11.4/kakfa-docker-compose.md
Normal file
@ -0,0 +1,208 @@
|
||||
### 创建各种文件目录
|
||||
|
||||
```bash
|
||||
mkdir -p /tmp/kafka/broker{1..3}/{data,logs}
|
||||
mkdir -p /tmp/zookeeper/zookeeper/{data,datalog,logs,conf}
|
||||
```
|
||||
|
||||
### zookeeper配置文件
|
||||
|
||||
- vi /tmp/zookeeper/zookeeper/conf/zoo.cfg
|
||||
|
||||
```yaml
|
||||
# The number of milliseconds of each tick
|
||||
tickTime=2000
|
||||
# The number of ticks that the initial
|
||||
# synchronization phase can take
|
||||
initLimit=10
|
||||
# The number of ticks that can pass between
|
||||
# sending a request and getting an acknowledgement
|
||||
syncLimit=5
|
||||
# the directory where the snapshot is stored.
|
||||
# do not use /tmp for storage, /tmp here is just
|
||||
# example sakes.
|
||||
dataDir=/data
|
||||
dataLogDir=/datalog
|
||||
# the port at which the clients will connect
|
||||
clientPort=2181
|
||||
# the maximum number of client connections.
|
||||
# increase this if you need to handle more clients
|
||||
#maxClientCnxns=60
|
||||
#
|
||||
# Be sure to read the maintenance section of the
|
||||
# administrator guide before turning on autopurge.
|
||||
#
|
||||
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
|
||||
#
|
||||
# The number of snapshots to retain in dataDir
|
||||
autopurge.snapRetainCount=3
|
||||
# Purge task interval in hours
|
||||
# Set to "0" to disable auto purge feature
|
||||
autopurge.purgeInterval=1
|
||||
```
|
||||
|
||||
- vi /tmp/zookeeper/zookeeper/conf/log4j.properties
|
||||
|
||||
```yaml
|
||||
# Define some default values that can be overridden by system properties
|
||||
zookeeper.root.logger=INFO, CONSOLE
|
||||
zookeeper.console.threshold=INFO
|
||||
zookeeper.log.dir=/logs
|
||||
zookeeper.log.file=zookeeper.log
|
||||
zookeeper.log.threshold=DEBUG
|
||||
zookeeper.tracelog.dir=.
|
||||
zookeeper.tracelog.file=zookeeper_trace.log
|
||||
|
||||
#
|
||||
# ZooKeeper Logging Configuration
|
||||
#
|
||||
|
||||
# Format is "<default threshold> (, <appender>)+
|
||||
|
||||
# DEFAULT: console appender only
|
||||
log4j.rootLogger=${zookeeper.root.logger}
|
||||
|
||||
# Example with rolling log file
|
||||
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
|
||||
|
||||
# Example with rolling log file and tracing
|
||||
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
|
||||
|
||||
#
|
||||
# Log INFO level and above messages to the console
|
||||
#
|
||||
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
|
||||
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
|
||||
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
|
||||
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
|
||||
|
||||
#
|
||||
# Add ROLLINGFILE to rootLogger to get log file output
|
||||
# Log DEBUG level and above messages to a log file
|
||||
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
|
||||
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
|
||||
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
|
||||
|
||||
# Max log file size of 10MB
|
||||
log4j.appender.ROLLINGFILE.MaxFileSize=10MB
|
||||
# uncomment the next line to limit number of backup files
|
||||
log4j.appender.ROLLINGFILE.MaxBackupIndex=10
|
||||
|
||||
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
|
||||
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
|
||||
|
||||
|
||||
#
|
||||
# Add TRACEFILE to rootLogger to get log file output
|
||||
# Log DEBUG level and above messages to a log file
|
||||
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
|
||||
log4j.appender.TRACEFILE.Threshold=TRACE
|
||||
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
|
||||
|
||||
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
|
||||
### Notice we are including log4j's NDC here (%x)
|
||||
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
|
||||
```
|
||||
|
||||
|
||||
|
||||
### docker-compose 配置文件
|
||||
|
||||
- vi docker-compose.yaml
|
||||
|
||||
```yaml
|
||||
version: '2'
|
||||
services:
|
||||
zookeeper:
|
||||
container_name: zookeeper
|
||||
image: wurstmeister/zookeeper:v1
|
||||
pull_policy: never
|
||||
restart: unless-stopped
|
||||
hostname: zoo1
|
||||
volumes:
|
||||
- "/tmp/zookeeper/zookeeper/data:/data"
|
||||
- "/tmp/zookeeper/zookeeper/datalog:/datalog"
|
||||
- "/tmp/zookeeper/zookeeper/logs:/logs"
|
||||
- "/tmp/zookeeper/zookeeper/conf:/opt/zookeeper-3.4.13/conf"
|
||||
ports:
|
||||
- "2181:2181"
|
||||
networks:
|
||||
- kafka
|
||||
kafka1:
|
||||
container_name: kafka1
|
||||
image: wurstmeister/kafka:v1
|
||||
pull_policy: never
|
||||
ports:
|
||||
- "8002:9092"
|
||||
environment:
|
||||
KAFKA_ADVERTISED_HOST_NAME: 10.25.76.114 ## 修改:宿主机IP
|
||||
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://10.25.76.114:8002 ## 修改:宿主机IP
|
||||
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
|
||||
KAFKA_ADVERTISED_PORT: 8002
|
||||
KAFKA_BROKER_ID: 1
|
||||
KAFKA_LOG_DIRS: /kafka/data
|
||||
volumes:
|
||||
- /tmp/kafka/broker1/logs:/opt/kafka/logs
|
||||
- /tmp/kafka/broker1/data:/kafka/data
|
||||
depends_on:
|
||||
- zookeeper
|
||||
networks:
|
||||
- kafka
|
||||
kafka2:
|
||||
container_name: kafka2
|
||||
image: wurstmeister/kafka:v1
|
||||
pull_policy: never
|
||||
ports:
|
||||
- "8003:9092"
|
||||
environment:
|
||||
KAFKA_ADVERTISED_HOST_NAME: 10.25.76.114 ## 修改:宿主机IP
|
||||
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://10.25.76.114:8003 ## 修改:宿主机IP
|
||||
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
|
||||
KAFKA_ADVERTISED_PORT: 8003
|
||||
KAFKA_BROKER_ID: 2
|
||||
KAFKA_LOG_DIRS: /kafka/data
|
||||
volumes:
|
||||
- /tmp/kafka/broker2/logs:/opt/kafka/logs
|
||||
- /tmp/kafka/broker2/data:/kafka/data
|
||||
depends_on:
|
||||
- zookeeper
|
||||
networks:
|
||||
- kafka
|
||||
kafka3:
|
||||
container_name: kafka3
|
||||
image: wurstmeister/kafka:v1
|
||||
pull_policy: never
|
||||
ports:
|
||||
- "8004:9092"
|
||||
environment:
|
||||
KAFKA_ADVERTISED_HOST_NAME: 10.25.76.114 ## 修改:宿主机IP
|
||||
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://10.25.76.114:8004 ## 修改:宿主机IP
|
||||
KAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"
|
||||
KAFKA_ADVERTISED_PORT: 8004
|
||||
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
|
||||
KAFKA_MIN_INSYNC_REPLICAS: 2
|
||||
KAFKA_BROKER_ID: 3
|
||||
KAFKA_LOG_DIRS: /kafka/data
|
||||
volumes:
|
||||
- /tmp/kafka/broker3/logs:/opt/kafka/logs
|
||||
- /tmp/kafka/broker3/data:/kafka/data
|
||||
depends_on:
|
||||
- zookeeper
|
||||
networks:
|
||||
- kafka
|
||||
kafka-ui:
|
||||
image: provectuslabs/kafka-ui:v1
|
||||
pull_policy: never
|
||||
environment:
|
||||
DYNAMIC_CONFIG_ENABLED: 'true'
|
||||
ports:
|
||||
- "8001:8080" ## 暴露端口
|
||||
networks:
|
||||
- kafka
|
||||
depends_on:
|
||||
- zookeeper
|
||||
networks:
|
||||
kafka:
|
||||
driver: bridge
|
||||
```
|
||||
|
||||
12
daliy_note/11.5/go-alpine缺lib库.md
Normal file
12
daliy_note/11.5/go-alpine缺lib库.md
Normal file
@ -0,0 +1,12 @@
|
||||
### 解决方案一 安装依赖库
|
||||
|
||||
```bash
|
||||
apk add libc6-compat
|
||||
```
|
||||
|
||||
### 关闭CGO
|
||||
|
||||
```bash
|
||||
CGO_ENABLE=0 go build
|
||||
```
|
||||
|
||||
10
daliy_note/11.6/安装python2.md
Normal file
10
daliy_note/11.6/安装python2.md
Normal file
@ -0,0 +1,10 @@
|
||||
### mac 安装
|
||||
|
||||
```bash
|
||||
brew install pyenv
|
||||
pyenv install 2.7.18
|
||||
export PATH="$(pyenv root)/shims:${PATH}"
|
||||
pyenv global 2.7.18
|
||||
python --version
|
||||
```
|
||||
|
||||
11
daliy_note/11.8/ssh异常解决.md
Normal file
11
daliy_note/11.8/ssh异常解决.md
Normal file
@ -0,0 +1,11 @@
|
||||
### ssh 报错 no key alg
|
||||
|
||||
> 低版本ssh 连接 高版本
|
||||
|
||||
- ssh -Q kex 查看服务器支持的加密算法
|
||||
- sshd -T |grep kex 查看当前配置
|
||||
- 修改ssh配置文件 sudo vim /etc/ssh/sshd_config
|
||||
- 末尾加入 KexAlgorithms=+diffie-hellman-group1-sha1
|
||||
- 末尾加入 HostKeyAlgorithms +ssh-rsa
|
||||
|
||||
- 重启ssh 服务 service sshd restart
|
||||
0
daliy_note/8月归档/8.21/8.21.md
Normal file
0
daliy_note/8月归档/8.21/8.21.md
Normal file
175
daliy_note/8月归档/8.21/as-a-service.md
Normal file
175
daliy_note/8月归档/8.21/as-a-service.md
Normal file
@ -0,0 +1,175 @@
|
||||
### IaaS(Infrastructure as a Service,基础设施即服务)
|
||||
|
||||
**IaaS** 是最基本的云计算服务模型,提供虚拟化的计算资源,包括服务器、存储和网络资源。用户可以根据需要配置和管理这些资源。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **灵活性**:用户可以根据需要动态调整计算资源。
|
||||
- **控制力**:用户拥有对操作系统、存储和网络等基础设施的控制权。
|
||||
- **成本效益**:按使用量付费,避免了前期资本支出。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Amazon Web Services (AWS) EC2**
|
||||
- **Microsoft Azure Virtual Machines**
|
||||
- **Google Cloud Compute Engine**
|
||||
|
||||
### PaaS(Platform as a Service,平台即服务)
|
||||
|
||||
**PaaS** 提供一个开发和部署应用程序的平台,使开发者可以专注于代码和应用程序本身,而无需管理底层的基础设施。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **简化开发**:提供开发工具、数据库、操作系统等,简化了开发流程。
|
||||
- **自动化管理**:自动处理基础设施管理(如扩展、备份、安全性等)。
|
||||
- **协作支持**:通常支持团队协作,简化了开发、测试和部署过程。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Google App Engine**
|
||||
- **Microsoft Azure App Services**
|
||||
- **Heroku**
|
||||
|
||||
### SaaS(Software as a Service,软件即服务)
|
||||
|
||||
**SaaS** 提供通过互联网访问的软件应用程序,通常是基于订阅模式。用户无需安装、配置或管理软件,只需使用浏览器或客户端访问。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **易于使用**:无需安装和维护,用户可以直接使用。
|
||||
- **按需付费**:通常基于订阅模式,按用户数量或使用量付费。
|
||||
- **自动更新**:软件提供商负责维护和更新,确保用户始终使用最新版本。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Google Workspace(如 Gmail、Google Docs)**
|
||||
- **Microsoft Office 365**
|
||||
- **Salesforce**
|
||||
|
||||
### MaaS(Monitoring as a Service,监控即服务)
|
||||
|
||||
**MaaS** 是一种专注于监控和管理 IT 基础设施和应用程序性能的服务模型。它提供远程监控、告警和报告功能,帮助组织确保其系统的健康和性能。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **远程监控**:通过云平台远程监控基础设施和应用程序。
|
||||
- **实时告警**:提供实时告警和通知,帮助快速响应问题。
|
||||
- **报告和分析**:提供详细的性能报告和分析,帮助优化系统。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **New Relic**
|
||||
- **Datadog**
|
||||
- **Amazon CloudWatch**
|
||||
|
||||
### BaaS(Backend as a Service,后端即服务)
|
||||
|
||||
**BaaS** 提供全面的后端服务,帮助开发者快速构建和管理应用程序的后端功能,如数据库、身份验证、推送通知等。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **快速开发**:简化后端开发,专注于前端和业务逻辑。
|
||||
- **可扩展性**:自动处理扩展和负载平衡。
|
||||
- **安全性**:提供内置的安全功能。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Firebase**
|
||||
- **AWS Amplify**
|
||||
- **Parse**
|
||||
|
||||
### DaaS(Desktop as a Service,桌面即服务)
|
||||
|
||||
**DaaS** 提供虚拟桌面环境,使用户可以通过互联网访问和使用桌面操作系统及应用程序。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **灵活性**:用户可以从任何设备访问虚拟桌面。
|
||||
- **简化管理**:集中管理桌面环境,简化 IT 管理任务。
|
||||
- **安全性**:提供数据隔离和安全访问控制。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Amazon WorkSpaces**
|
||||
- **Microsoft Windows Virtual Desktop**
|
||||
- **Citrix Virtual Apps and Desktops**
|
||||
|
||||
### DBaaS(Database as a Service,数据库即服务)
|
||||
|
||||
**DBaaS** 提供托管的数据库服务,用户可以按需创建、管理和扩展数据库,而无需担心底层基础设施。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **自动化管理**:自动处理数据库的备份、恢复、升级和扩展。
|
||||
- **高可用性**:提供内置的高可用性和容灾功能。
|
||||
- **按需付费**:根据使用量付费,避免了前期资本支出。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Amazon RDS**
|
||||
- **Google Cloud SQL**
|
||||
- **Microsoft Azure SQL Database**
|
||||
|
||||
### FaaS(Function as a Service,函数即服务)
|
||||
|
||||
**FaaS** 是一种事件驱动的计算服务,允许开发者上传并执行代码函数,而无需管理服务器。通常被称为 “无服务器计算”。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **无服务器**:无需管理底层服务器,专注于业务逻辑。
|
||||
- **按需执行**:按函数调用次数和执行时间付费。
|
||||
- **自动扩展**:根据负载自动扩展和收缩。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **AWS Lambda**
|
||||
- **Google Cloud Functions**
|
||||
- **Microsoft Azure Functions**
|
||||
|
||||
### NaaS(Network as a Service,网络即服务)
|
||||
|
||||
**NaaS** 提供基于云的网络服务,使用户可以按需配置和管理网络资源,如虚拟专用网(VPN)、负载均衡和防火墙。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **按需配置**:灵活配置网络资源,满足不同需求。
|
||||
- **可扩展性**:根据需求自动扩展网络容量。
|
||||
- **安全性**:提供内置的网络安全功能。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Amazon VPC**
|
||||
- **Microsoft Azure Virtual Network**
|
||||
- **Google Cloud Virtual Private Cloud (VPC)**
|
||||
|
||||
### STaaS(Storage as a Service,存储即服务)
|
||||
|
||||
**STaaS** 提供基于云的存储服务,使用户可以按需存储和管理数据,通常提供对象存储、块存储和文件存储等类型。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **按需存储**:根据数据量付费,灵活扩展存储容量。
|
||||
- **高可用性**:提供高可用性和容灾功能。
|
||||
- **数据安全**:提供加密和访问控制,确保数据安全。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **Amazon S3**
|
||||
- **Google Cloud Storage**
|
||||
- **Microsoft Azure Blob Storage**
|
||||
|
||||
### AIaaS(Artificial Intelligence as a Service,人工智能即服务)
|
||||
|
||||
**AIaaS** 提供基于云的人工智能服务,使用户可以按需访问和使用 AI 模型和工具,如机器学习、自然语言处理和计算机视觉等。
|
||||
|
||||
**特点**:
|
||||
|
||||
- **即用型 AI**:无需开发复杂的 AI 模型,直接使用现成的服务。
|
||||
- **可扩展性**:根据需求自动扩展计算资源。
|
||||
- **集成性**:易于集成到现有应用程序和工作流程中。
|
||||
|
||||
**示例**:
|
||||
|
||||
- **IBM Watson**
|
||||
- **Google AI Platform**
|
||||
- **Microsoft Azure AI**
|
||||
237
daliy_note/8月归档/8.21/servlet.md
Normal file
237
daliy_note/8月归档/8.21/servlet.md
Normal file
@ -0,0 +1,237 @@
|
||||
Servlet 容器是一个用于管理和执行 Java Servlet、JSP(JavaServer Pages)和其他基于 Java 的 web 组件的运行时环境。它是 Java EE(企业版)规范的一部分,负责处理客户端请求、管理 servlet 生命周期、提供网络服务和其他运行时环境支持。
|
||||
|
||||
### Servlet 容器的功能
|
||||
|
||||
1. **请求处理**:
|
||||
- 接收客户端(通常是浏览器)发送的 HTTP 请求,并根据 URL 路径将请求分发到相应的 servlet 进行处理。
|
||||
- 处理 HTTP 请求和响应,包括 GET、POST、PUT、DELETE 等方法。
|
||||
2. **Servlet 生命周期管理**:
|
||||
- 管理 servlet 的生命周期,包括加载、初始化、处理请求、销毁等。
|
||||
- 调用 servlet 的 init() 方法进行初始化,service() 方法处理请求,destroy() 方法进行销毁。
|
||||
3. **会话管理**:
|
||||
- 提供会话管理功能,通过 cookies 或 URL 重写来跟踪用户会话。
|
||||
- 维护会话状态,确保多次请求之间的数据一致性。
|
||||
4. **安全性**:
|
||||
- 提供认证和授权机制,确保只有授权用户才能访问受保护的资源。
|
||||
- 支持基于角色的访问控制(RBAC)。
|
||||
5. **并发处理**:
|
||||
- 处理多个客户端请求的并发性,确保高效的资源使用和响应时间。
|
||||
- 提供线程管理和同步机制,确保数据一致性和线程安全。
|
||||
6. **资源管理**:
|
||||
- 管理静态资源(如 HTML、CSS、JavaScript 文件)和动态资源(如 servlet、JSP 页面)。
|
||||
- 提供资源的加载和缓存功能,优化性能。
|
||||
7. **日志记录和监控**:
|
||||
- 提供日志记录功能,记录请求、响应和错误信息,便于调试和监控。
|
||||
- 支持监控和管理工具,帮助管理员监控服务器性能和健康状态。
|
||||
|
||||
### 常见的 Servlet 容器
|
||||
|
||||
1. **Apache Tomcat**:
|
||||
- 开源的 Servlet 容器,广泛用于开发和部署 Java web 应用。
|
||||
- 支持 Servlet、JSP 和 WebSocket 等规范。
|
||||
2. **Jetty**:
|
||||
- 轻量级、高性能的 Servlet 容器,适用于嵌入式系统和微服务架构。
|
||||
- 支持 HTTP/2、WebSocket 等现代协议。
|
||||
3. **GlassFish**:
|
||||
- 完整的 Java EE 应用服务器,支持所有 Java EE 规范。
|
||||
- 提供企业级功能,如事务管理、消息驱动 Bean 和 JCA 连接器等。
|
||||
4. **WildFly(原 JBoss AS)**:
|
||||
- 另一个完整的 Java EE 应用服务器,支持所有 Java EE 规范。
|
||||
- 提供高性能和高可用性的企业级功能。
|
||||
5. **IBM WebSphere**:
|
||||
- 企业级 Java EE 应用服务器,提供高可靠性和高性能。
|
||||
- 支持广泛的企业功能和集成能力。
|
||||
6. **Oracle WebLogic**:
|
||||
- 企业级 Java EE 应用服务器,提供高可用性和可扩展性。
|
||||
- 支持广泛的企业功能和集成能力。
|
||||
|
||||
### Servlet 容器的工作原理
|
||||
|
||||
1. **启动**:
|
||||
- Servlet 容器启动时,读取配置文件(如 `web.xml` 或注解配置),加载和初始化所有配置的 servlet 和其他组件。
|
||||
2. **请求处理**:
|
||||
- 当客户端发送请求时,Servlet 容器接收请求并解析 URL 路径,将请求分发到相应的 servlet。
|
||||
- 调用 servlet 的 service() 方法,根据请求方法(GET、POST 等)调用 doGet() 或 doPost() 等具体方法处理请求。
|
||||
3. **响应生成**:
|
||||
- Servlet 处理请求后,生成响应(如 HTML、JSON 数据)并通过 HttpServletResponse 对象发送回客户端。
|
||||
4. **会话管理**:
|
||||
- Servlet 容器维护会话状态,通过 cookies 或 URL 重写跟踪用户会话。
|
||||
- 提供 HttpSession 对象,允许 servlet 存储和检索会话数据。
|
||||
5. **销毁**:
|
||||
- 在应用程序关闭或 servlet 需要卸载时,Servlet 容器调用 servlet 的 destroy() 方法进行清理工作。
|
||||
|
||||
### 总结
|
||||
|
||||
Servlet 容器是 Java web 应用程序的核心组件,提供了请求处理、生命周期管理、会话管理、安全性、并发处理、资源管理和日志记录等功能。常见的 Servlet 容器包括 Apache Tomcat、Jetty、GlassFish、WildFly、IBM WebSphere 和 Oracle WebLogic 等。了解 Servlet 容器的工作原理和功能,有助于开发和部署高效、可靠的 Java web 应用程序。
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
部分方法
|
||||
|
||||
### `HttpServletRequest` 对象的主要用途
|
||||
|
||||
1. **获取请求参数**:
|
||||
|
||||
- 使用 `getParameter(String name)` 方法获取单个请求参数的值。
|
||||
- 使用 `getParameterValues(String name)` 方法获取具有相同名称的多个请求参数的值(返回字符串数组)。
|
||||
- 使用 `getParameterMap()` 方法获取所有请求参数的键值对(返回 `Map<String, String[]>`)。
|
||||
|
||||
```
|
||||
String username = request.getParameter("username");
|
||||
String[] hobbies = request.getParameterValues("hobbies");
|
||||
Map<String, String[]> parameterMap = request.getParameterMap();
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. **获取请求头信息**:
|
||||
|
||||
- 使用 `getHeader(String name)` 方法获取指定请求头的值。
|
||||
- 使用 `getHeaders(String name)` 方法获取具有相同名称的多个请求头的值(返回 `Enumeration<String>`)。
|
||||
- 使用 `getHeaderNames()` 方法获取所有请求头的名称(返回 `Enumeration<String>`)。
|
||||
|
||||
```
|
||||
String userAgent = request.getHeader("User-Agent");
|
||||
Enumeration<String> headerNames = request.getHeaderNames();
|
||||
```
|
||||
|
||||
|
||||
|
||||
3. **获取请求路径和 URL 信息**:
|
||||
|
||||
- 使用 `getRequestURI()` 方法获取请求的 URI 部分。
|
||||
- 使用 `getRequestURL()` 方法获取请求的完整 URL。
|
||||
- 使用 `getContextPath()` 方法获取应用程序的上下文路径。
|
||||
- 使用 `getServletPath()` 方法获取 servlet 的路径。
|
||||
|
||||
```
|
||||
String uri = request.getRequestURI();
|
||||
StringBuffer url = request.getRequestURL();
|
||||
String contextPath = request.getContextPath();
|
||||
String servletPath = request.getServletPath();
|
||||
```
|
||||
|
||||
|
||||
|
||||
4. **获取请求方法**:
|
||||
|
||||
- 使用 `getMethod()` 方法获取请求的方法(如 GET、POST、PUT、DELETE 等)。
|
||||
|
||||
```
|
||||
String method = request.getMethod();
|
||||
```
|
||||
|
||||
|
||||
|
||||
5. **获取请求体数据**:
|
||||
|
||||
- 使用 `getReader()` 方法获取 `BufferedReader` 对象,从而读取请求体的数据(用于处理文本数据)。
|
||||
- 使用 `getInputStream()` 方法获取 `ServletInputStream` 对象,从而读取请求体的数据(用于处理二进制数据)。
|
||||
|
||||
```
|
||||
BufferedReader reader = request.getReader();
|
||||
// 或
|
||||
ServletInputStream inputStream = request.getInputStream();
|
||||
```
|
||||
|
||||
|
||||
|
||||
6. **会话管理**:
|
||||
|
||||
- 使用 `getSession()` 方法获取当前会话(如果不存在则创建一个新的会话)。
|
||||
- 使用 `getSession(boolean create)` 方法获取当前会话(根据 `create` 参数决定是否创建新的会话)。
|
||||
|
||||
```
|
||||
HttpSession session = request.getSession();
|
||||
```
|
||||
|
||||
|
||||
|
||||
7. **处理请求属性**:
|
||||
|
||||
- 使用 `getAttribute(String name)` 方法获取请求属性。
|
||||
- 使用 `setAttribute(String name, Object o)` 方法设置请求属性。
|
||||
- 使用 `removeAttribute(String name)` 方法移除请求属性。
|
||||
|
||||
```
|
||||
Object attr = request.getAttribute("attrName");
|
||||
request.setAttribute("attrName", someObject);
|
||||
request.removeAttribute("attrName");
|
||||
```
|
||||
|
||||
|
||||
|
||||
8. **其他有用的方法**:
|
||||
|
||||
- `getRemoteAddr()`:获取客户端的 IP 地址。
|
||||
- `getRemoteHost()`:获取客户端的主机名。
|
||||
- `getCookies()`:获取请求中的所有 cookies(返回 `Cookie[]`)。
|
||||
- `getLocale()`:获取客户端的首选语言环境。
|
||||
- `getQueryString()`:获取请求的查询字符串。
|
||||
|
||||
```
|
||||
String remoteAddr = request.getRemoteAddr();
|
||||
String remoteHost = request.getRemoteHost();
|
||||
Cookie[] cookies = request.getCookies();
|
||||
Locale locale = request.getLocale();
|
||||
String queryString = request.getQueryString();
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 示例代码
|
||||
|
||||
下面是一个简单的示例 servlet,展示如何使用 `HttpServletRequest` 对象获取请求信息:
|
||||
|
||||
```
|
||||
import javax.servlet.ServletException;
|
||||
import javax.servlet.annotation.WebServlet;
|
||||
import javax.servlet.http.HttpServlet;
|
||||
import javax.servlet.http.HttpServletRequest;
|
||||
import javax.servlet.http.HttpServletResponse;
|
||||
import java.io.IOException;
|
||||
import java.io.PrintWriter;
|
||||
|
||||
@WebServlet("/example")
|
||||
public class ExampleServlet extends HttpServlet {
|
||||
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
|
||||
response.setContentType("text/html");
|
||||
PrintWriter out = response.getWriter();
|
||||
|
||||
// 获取请求参数
|
||||
String username = request.getParameter("username");
|
||||
|
||||
// 获取请求头
|
||||
String userAgent = request.getHeader("User-Agent");
|
||||
|
||||
// 获取请求路径和 URL
|
||||
String uri = request.getRequestURI();
|
||||
StringBuffer url = request.getRequestURL();
|
||||
|
||||
// 获取请求方法
|
||||
String method = request.getMethod();
|
||||
|
||||
// 获取客户端 IP 地址
|
||||
String remoteAddr = request.getRemoteAddr();
|
||||
|
||||
// 输出信息到响应
|
||||
out.println("<html><body>");
|
||||
out.println("<h1>Request Information</h1>");
|
||||
out.println("<p>Username: " + username + "</p>");
|
||||
out.println("<p>User-Agent: " + userAgent + "</p>");
|
||||
out.println("<p>Request URI: " + uri + "</p>");
|
||||
out.println("<p>Request URL: " + url.toString() + "</p>");
|
||||
out.println("<p>Request Method: " + method + "</p>");
|
||||
out.println("<p>Client IP: " + remoteAddr + "</p>");
|
||||
out.println("</body></html>");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 总结
|
||||
|
||||
`HttpServletRequest` 对象是处理客户端 HTTP 请求的关键对象。它提供了各种方法来访问请求参数、请求头、请求路径、会话信息和请求体数据等。通过正确使用 `HttpServletRequest` 对象,开发者可以有效地处理和响应客户端请求,构建功能丰富的 web 应用程序。
|
||||
1
daliy_note/8月归档/8.22/8.22.md
Normal file
1
daliy_note/8月归档/8.22/8.22.md
Normal file
@ -0,0 +1 @@
|
||||
SOP 是 Standard Operating Procedure(标准操作程序)的缩写。SOP 是指一组详细的、书面的指示,旨在帮助执行某些操作或任务,以确保一致性、效率和质量。SOP 常用于各种行业和领域,包括制造业、医疗保健、信息技术、制药、食品服务和政府机构等。
|
||||
0
daliy_note/8月归档/8.22/alertmanager.md
Normal file
0
daliy_note/8月归档/8.22/alertmanager.md
Normal file
182
daliy_note/8月归档/8.22/golang-runtime.md
Normal file
182
daliy_note/8月归档/8.22/golang-runtime.md
Normal file
@ -0,0 +1,182 @@
|
||||
`runtime.SetBlockProfileRate` 是 Go 语言中的一个函数,用于控制阻塞操作的采样和分析。阻塞操作包括通道操作、锁的获取和等待等,这些操作可能会影响程序的性能和并发性。
|
||||
|
||||
## 用途
|
||||
|
||||
`runtime.SetBlockProfileRate` 的主要用途是开启和控制阻塞操作的采样,以便于对程序的性能进行分析和优化。通过设置采样率,可以捕获阻塞操作的样本,并生成阻塞分析报告(block profile)。这些报告可以帮助你识别和诊断程序中的性能瓶颈。
|
||||
|
||||
## 函数签名
|
||||
|
||||
```
|
||||
func SetBlockProfileRate(rate int)
|
||||
```
|
||||
|
||||
|
||||
|
||||
- `rate`: 设置采样的阻塞事件数。当 `rate` 为正数时,每发生 `rate` 次阻塞事件,会采样一次。当 `rate` 为零时,禁用阻塞分析。
|
||||
|
||||
## 示例
|
||||
|
||||
以下是一个简单的示例,展示了如何使用 `runtime.SetBlockProfileRate` 进行阻塞分析:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
"runtime"
|
||||
"runtime/pprof"
|
||||
"os"
|
||||
"time"
|
||||
)
|
||||
|
||||
func main() {
|
||||
// 设置阻塞分析的采样率,这里设置为 1 表示每次阻塞都会采样
|
||||
runtime.SetBlockProfileRate(1)
|
||||
|
||||
// 创建一个通道用于测试阻塞操作
|
||||
ch := make(chan bool)
|
||||
|
||||
// 启动一个 goroutine 并阻塞在接收操作上
|
||||
go func() {
|
||||
<-ch
|
||||
}()
|
||||
|
||||
// 等待一段时间以产生一些阻塞事件
|
||||
time.Sleep(2 * time.Second)
|
||||
|
||||
// 停止阻塞分析
|
||||
runtime.SetBlockProfileRate(0)
|
||||
|
||||
// 创建一个文件保存阻塞分析报告
|
||||
f, err := os.Create("block_profile.out")
|
||||
if err != nil {
|
||||
log.Fatal("could not create block profile: ", err)
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
// 写入阻塞分析报告
|
||||
if err := pprof.Lookup("block").WriteTo(f, 0); err != nil {
|
||||
log.Fatal("could not write block profile: ", err)
|
||||
}
|
||||
|
||||
log.Println("Block profile saved to block_profile.out")
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 运行示例
|
||||
|
||||
1. 运行上述代码。
|
||||
2. 生成的阻塞分析报告会保存在当前目录下的 `block_profile.out` 文件中。
|
||||
3. 使用 `go tool pprof` 工具查看分析报告:
|
||||
|
||||
```
|
||||
go tool pprof block_profile.out
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 `pprof` 交互模式下,你可以使用命令如 `top`、`list` 等来查看阻塞事件的详细信息。
|
||||
|
||||
## 总结
|
||||
|
||||
`runtime.SetBlockProfileRate` 是一个强大的工具,能够帮助开发者分析和优化 Go 程序中的阻塞操作。通过调整采样率和生成阻塞分析报告,你可以更好地理解程序的性能瓶颈,并做出相应的优化。
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
`runtime.SetMutexProfileFraction` 是 Go 语言中的一个函数,用于控制互斥锁(mutex)竞争事件的采样和分析。互斥锁竞争发生在多个 Goroutine 争用同一个锁的情况下,这可能会影响程序的并发性能。
|
||||
|
||||
## 用途
|
||||
|
||||
`runtime.SetMutexProfileFraction` 的主要用途是开启和控制互斥锁竞争事件的采样,以便于对程序的锁竞争情况进行分析和优化。通过设置采样率,可以捕获锁竞争事件的样本,并生成互斥锁竞争分析报告(mutex profile)。这些报告可以帮助你识别和诊断程序中的锁竞争瓶颈。
|
||||
|
||||
## 函数签名
|
||||
|
||||
```
|
||||
func SetMutexProfileFraction(rate int) int
|
||||
```
|
||||
|
||||
|
||||
|
||||
- `rate`: 设置采样的互斥锁竞争事件数。当 `rate` 为正数时,每发生 `rate` 次竞争事件,会采样一次。当 `rate` 为零时,禁用互斥锁竞争分析。
|
||||
- 返回值:返回先前设置的采样率。
|
||||
|
||||
## 示例
|
||||
|
||||
以下是一个简单的示例,展示了如何使用 `runtime.SetMutexProfileFraction` 进行互斥锁竞争分析:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
"os"
|
||||
"runtime"
|
||||
"runtime/pprof"
|
||||
"sync"
|
||||
"time"
|
||||
)
|
||||
|
||||
func main() {
|
||||
// 设置互斥锁竞争分析的采样率,这里设置为 1 表示每次竞争都会采样
|
||||
prevRate := runtime.SetMutexProfileFraction(1)
|
||||
log.Printf("Previous mutex profile rate: %d\n", prevRate)
|
||||
|
||||
// 创建一个互斥锁用于测试竞争操作
|
||||
var mu sync.Mutex
|
||||
|
||||
// 启动多个 goroutine 并竞争获取锁
|
||||
for i := 0; i < 10; i++ {
|
||||
go func(i int) {
|
||||
for j := 0; j < 1000; j++ {
|
||||
mu.Lock()
|
||||
time.Sleep(10 * time.Millisecond) // 模拟一些工作
|
||||
mu.Unlock()
|
||||
}
|
||||
}(i)
|
||||
}
|
||||
|
||||
// 等待一段时间以产生一些竞争事件
|
||||
time.Sleep(5 * time.Second)
|
||||
|
||||
// 停止互斥锁竞争分析
|
||||
runtime.SetMutexProfileFraction(0)
|
||||
|
||||
// 创建一个文件保存互斥锁竞争分析报告
|
||||
f, err := os.Create("mutex_profile.out")
|
||||
if err != nil {
|
||||
log.Fatal("could not create mutex profile: ", err)
|
||||
}
|
||||
defer f.Close()
|
||||
|
||||
// 写入互斥锁竞争分析报告
|
||||
if err := pprof.Lookup("mutex").WriteTo(f, 0); err != nil {
|
||||
log.Fatal("could not write mutex profile: ", err)
|
||||
}
|
||||
|
||||
log.Println("Mutex profile saved to mutex_profile.out")
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 运行示例
|
||||
|
||||
1. 运行上述代码。
|
||||
2. 生成的互斥锁竞争分析报告会保存在当前目录下的 `mutex_profile.out` 文件中。
|
||||
3. 使用 `go tool pprof` 工具查看分析报告:
|
||||
|
||||
```
|
||||
go tool pprof mutex_profile.out
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 `pprof` 交互模式下,你可以使用命令如 `top`、`list` 等来查看互斥锁竞争事件的详细信息。
|
||||
|
||||
## 总结
|
||||
|
||||
`runtime.SetMutexProfileFraction` 是一个有用的工具,能够帮助开发者分析和优化 Go 程序中的互斥锁竞争情况。通过调整采样率和生成互斥锁竞争分析报告,你可以更好地理解程序的锁竞争瓶颈,并做出相应的优化。
|
||||
90
daliy_note/8月归档/8.22/linux$.md
Normal file
90
daliy_note/8月归档/8.22/linux$.md
Normal file
@ -0,0 +1,90 @@
|
||||
在 Linux 上,通过命令行执行命令时,命令的退出状态码(exit status)存储在特殊的环境变量 `$?` 中。退出状态码为 0 表示命令成功执行,非 0 表示命令执行失败。
|
||||
|
||||
如果你希望在执行命令后查看其退出状态码,可以使用如下方法:
|
||||
|
||||
1. **执行命令**:
|
||||
|
||||
```
|
||||
your_command_here
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. **查看退出状态码**:
|
||||
|
||||
```
|
||||
echo $?
|
||||
```
|
||||
|
||||
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
ls /some/directory
|
||||
echo $?
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果目录存在且命令成功,`echo $?` 将输出 `0`。如果目录不存在或发生错误,`echo $?` 将输出一个非零值,例如 `2`。
|
||||
|
||||
### 示例
|
||||
|
||||
假设你运行以下命令来列出一个不存在的目录:
|
||||
|
||||
```
|
||||
ls /nonexistent_directory
|
||||
```
|
||||
|
||||
|
||||
|
||||
然后你可以查看退出状态码:
|
||||
|
||||
```
|
||||
echo $?
|
||||
```
|
||||
|
||||
|
||||
|
||||
假设目录 `/nonexistent_directory` 不存在,`ls` 命令将失败,`echo $?` 输出:
|
||||
|
||||
```
|
||||
2
|
||||
```
|
||||
|
||||
|
||||
|
||||
这表明 `ls` 命令未成功执行。
|
||||
|
||||
### 常见的退出状态码
|
||||
|
||||
- `0`:命令成功执行。
|
||||
- `1`:一般性错误,例如权限问题。
|
||||
- `2`:误用命令内建功能。
|
||||
- `127`:命令未找到。
|
||||
|
||||
### 示例脚本
|
||||
|
||||
你可以将这些命令放入一个脚本中,以便更方便地查看退出状态码:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
your_command_here
|
||||
status=$?
|
||||
|
||||
if [ $status -eq 0 ]; then
|
||||
echo "Command succeeded"
|
||||
else
|
||||
echo "Command failed with exit status $status"
|
||||
fi
|
||||
```
|
||||
|
||||
|
||||
|
||||
这个脚本首先执行 `your_command_here`,然后存储退出状态码,并根据状态码输出相应的消息。
|
||||
|
||||
### 总结
|
||||
|
||||
通过使用 `$?` 变量,你可以轻松地获取上一个命令的退出状态码,并根据该状态码执行相应的操作。这在编写脚本时特别有用,可以帮助你处理错误情况并进行调试。
|
||||
125
daliy_note/8月归档/8.22/linux获取上一个命令的执行结果.md
Normal file
125
daliy_note/8月归档/8.22/linux获取上一个命令的执行结果.md
Normal file
@ -0,0 +1,125 @@
|
||||
在 Linux 上,如果你想获取上一次命令的输出结果,有几种方法可以实现。这些方法包括使用命令替换、变量存储和管道重定向等技术。以下是几种常用的方法:
|
||||
|
||||
### 方法一:使用命令替换
|
||||
|
||||
你可以使用命令替换(command substitution)将命令的输出存储到一个变量中。例如:
|
||||
|
||||
```
|
||||
result=$(your_command_here)
|
||||
echo "$result"
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 示例
|
||||
|
||||
假设你要获取 `ls` 命令的输出并存储在变量中:
|
||||
|
||||
```
|
||||
result=$(ls /path/to/directory)
|
||||
echo "$result"
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 方法二:使用临时文件
|
||||
|
||||
你可以将命令的输出重定向到一个临时文件,然后读取该文件的内容。例如:
|
||||
|
||||
```
|
||||
your_command_here > temp_output.txt
|
||||
cat temp_output.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 示例
|
||||
|
||||
假设你要获取 `ls` 命令的输出并存储在临时文件中:
|
||||
|
||||
```
|
||||
ls /path/to/directory > temp_output.txt
|
||||
cat temp_output.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 方法三:使用管道和 `tee` 命令
|
||||
|
||||
`tee` 命令可以将输入内容同时写入标准输出和一个文件中。你可以利用这个特性将命令的输出存储到一个文件,同时显示在终端上。例如:
|
||||
|
||||
```
|
||||
your_command_here | tee temp_output.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 示例
|
||||
|
||||
假设你要获取 `ls` 命令的输出并同时显示在终端和存储在文件中:
|
||||
|
||||
```
|
||||
ls /path/to/directory | tee temp_output.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 方法四:重定向标准输出和标准错误
|
||||
|
||||
你可以将命令的标准输出和标准错误重定向到一个文件,然后读取该文件。例如:
|
||||
|
||||
```
|
||||
your_command_here > temp_output.txt 2>&1
|
||||
cat temp_output.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 示例
|
||||
|
||||
假设你要获取 `ls` 命令的输出和错误信息并存储在一个文件中:
|
||||
|
||||
```
|
||||
ls /path/to/directory > temp_output.txt 2>&1
|
||||
cat temp_output.txt
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 选择合适的方法
|
||||
|
||||
根据你的具体需求,可以选择以上方法之一。如果你只需要在脚本中临时存储并使用命令的输出,使用命令替换(方法一)通常是最方便的。如果你需要将输出内容保存在文件中供以后使用,可以选择方法二或方法三。
|
||||
|
||||
### 例子
|
||||
|
||||
假设你要获取当前目录下的所有文件和目录列表并存储在变量中:
|
||||
|
||||
```
|
||||
result=$(ls)
|
||||
echo "Current directory listing:"
|
||||
echo "$result"
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果你要在脚本中存储并处理命令的输出:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# 获取当前目录下的所有文件和目录列表
|
||||
result=$(ls)
|
||||
|
||||
# 打印输出
|
||||
echo "Current directory listing:"
|
||||
echo "$result"
|
||||
|
||||
# 进一步处理输出
|
||||
# 例如统计文件数
|
||||
file_count=$(echo "$result" | wc -l)
|
||||
echo "Number of files and directories: $file_count"
|
||||
```
|
||||
|
||||
|
||||
|
||||
通过这种方式,你可以灵活地获取并处理上一次命令的执行结果。
|
||||
0
daliy_note/8月归档/8.22/makefile.md
Normal file
0
daliy_note/8月归档/8.22/makefile.md
Normal file
0
daliy_note/8月归档/8.23/8.23.md
Normal file
0
daliy_note/8月归档/8.23/8.23.md
Normal file
85
daliy_note/8月归档/8.23/runmaxpos.md
Normal file
85
daliy_note/8月归档/8.23/runmaxpos.md
Normal file
@ -0,0 +1,85 @@
|
||||
`runtime.GOMAXPROCS` 是 Go 语言标准库中的一个函数,用于设置和获取可以同时执行的最大 CPU 数量。它是 Go 运行时调度器的重要部分,影响 Go 程序的并发性能。
|
||||
|
||||
### 用法
|
||||
|
||||
`runtime.GOMAXPROCS` 的签名如下:
|
||||
|
||||
```
|
||||
func GOMAXPROCS(n int) int
|
||||
```
|
||||
|
||||
|
||||
|
||||
- `n`:要设置的最大 CPU 核数。如果 `n` 为 0 或负数,`GOMAXPROCS` 不会改变当前的设置,只返回当前的值。
|
||||
- 返回值:函数会返回之前的 `GOMAXPROCS` 设置值。
|
||||
|
||||
### 示例代码
|
||||
|
||||
以下是一个简单的示例展示如何使用 `runtime.GOMAXPROCS`:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"runtime"
|
||||
)
|
||||
|
||||
func main() {
|
||||
// 获取当前的 GOMAXPROCS 设置
|
||||
currentProcs := runtime.GOMAXPROCS(0)
|
||||
fmt.Printf("Current GOMAXPROCS: %d\n", currentProcs)
|
||||
|
||||
// 设置 GOMAXPROCS 为 4
|
||||
previousProcs := runtime.GOMAXPROCS(4)
|
||||
fmt.Printf("Previous GOMAXPROCS: %d\n", previousProcs)
|
||||
|
||||
// 再次获取当前的 GOMAXPROCS 设置
|
||||
currentProcs = runtime.GOMAXPROCS(0)
|
||||
fmt.Printf("New GOMAXPROCS: %d\n", currentProcs)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 解释
|
||||
|
||||
1. **获取当前 `GOMAXPROCS` 设置**:
|
||||
|
||||
```
|
||||
currentProcs := runtime.GOMAXPROCS(0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
调用 `runtime.GOMAXPROCS(0)`,传入 0 表示不改变当前设置,只返回当前的 `GOMAXPROCS` 值。
|
||||
|
||||
2. **设置 `GOMAXPROCS`**:
|
||||
|
||||
```
|
||||
previousProcs := runtime.GOMAXPROCS(4)
|
||||
```
|
||||
|
||||
|
||||
|
||||
调用 `runtime.GOMAXPROCS(4)`,将最大并发执行的 CPU 数量设置为 4。函数返回之前的 `GOMAXPROCS` 值。
|
||||
|
||||
3. **再次获取当前的 `GOMAXPROCS` 设置**:
|
||||
|
||||
```
|
||||
currentProcs = runtime.GOMAXPROCS(0)
|
||||
```
|
||||
|
||||
|
||||
|
||||
再次获取当前的 `GOMAXPROCS` 值,验证新的设置是否生效。
|
||||
|
||||
### 注意事项
|
||||
|
||||
- **默认值**:在 Go 1.5 之前,`GOMAXPROCS` 的默认值是 1,这意味着默认情况下 Go 程序只能使用一个 CPU 核。在 Go 1.5 及以后,默认值是运行时机器上的 CPU 核数。
|
||||
- **性能影响**:设置过高的 `GOMAXPROCS` 值可能导致过多的上下文切换和资源争用,反而会降低程序性能。一般来说,`GOMAXPROCS` 的值设置为物理 CPU 核数是一个合理的选择。
|
||||
- **并发模型**:Go 的调度器使用的是 M:N 模型,其中 M 个 goroutine 映射到 N 个 OS 线程上。`GOMAXPROCS` 控制的是可以同时运行的 OS 线程数。
|
||||
|
||||
### 总结
|
||||
|
||||
`runtime.GOMAXPROCS` 是 Go 语言中的一个重要函数,用于设置和获取可以同时执行的最大 CPU 数量。合理设置 `GOMAXPROCS` 可以显著影响 Go 程序的并发性能。通过理解和使用 `GOMAXPROCS`,开发者可以更好地控制 Go 程序的调度行为,优化程序性能。
|
||||
34
daliy_note/8月归档/8.23/struct_compare.md
Normal file
34
daliy_note/8月归档/8.23/struct_compare.md
Normal file
@ -0,0 +1,34 @@
|
||||
- 别名可以直接比较 type MyStudent1 = Student
|
||||
- 属性字段一样,可以通过类型转换进行比较
|
||||
|
||||
```Go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
type Student struct {
|
||||
Name string
|
||||
}
|
||||
|
||||
type StudentAnother struct {
|
||||
Name string
|
||||
}
|
||||
|
||||
type MyStudent Student
|
||||
type MyStudent1 = Student
|
||||
|
||||
func main() {
|
||||
s1 := Student{Name: "1"}
|
||||
s2 := MyStudent{Name: "1"}
|
||||
s3 := MyStudent1{Name: "1"}
|
||||
s4 := StudentAnother{Name: "1"}
|
||||
fmt.Printf("s1: %T\n", s1)
|
||||
fmt.Printf("s2: %T\n", s2)
|
||||
fmt.Printf("s3: %T\n", s3)
|
||||
fmt.Printf("s4: %T\n", s4)
|
||||
// fmt.Printf("(s1 == s2): %v\n", (s1 == s2))
|
||||
fmt.Printf("(s1 == s3): %v\n", (s1 == s3))
|
||||
fmt.Printf("(s1 == Student(s4)): %v\n", (s1 == Student(s4)))
|
||||
}
|
||||
```
|
||||
|
||||
1
daliy_note/8月归档/8.26/8.26.md
Normal file
1
daliy_note/8月归档/8.26/8.26.md
Normal file
@ -0,0 +1 @@
|
||||

|
||||
35
daliy_note/8月归档/8.26/nfs.md
Normal file
35
daliy_note/8月归档/8.26/nfs.md
Normal file
@ -0,0 +1,35 @@
|
||||
### centos 挂载
|
||||
|
||||
#### 1. 安装 nfs-utils
|
||||
|
||||
```bash
|
||||
yum install nfs-utils -y
|
||||
```
|
||||
|
||||
#### 2. 挂载目录
|
||||
|
||||
```bash
|
||||
mount -t nfs 192.168.0.4:/export/share /mnt/nfs
|
||||
```
|
||||
|
||||
#### 3. 检查挂载
|
||||
|
||||
```bash
|
||||
df -h | grep nfs
|
||||
```
|
||||
|
||||
#### 4. 卸载
|
||||
|
||||
```bash
|
||||
umount /mnt/nfs
|
||||
```
|
||||
|
||||
### ubuntu挂载
|
||||
|
||||
#### 1. 安装 nfs-common
|
||||
|
||||
```bash
|
||||
apt install nfs-common
|
||||
```
|
||||
|
||||
#### 2. 剩余同上
|
||||
115
daliy_note/8月归档/8.26/redis.md
Normal file
115
daliy_note/8月归档/8.26/redis.md
Normal file
@ -0,0 +1,115 @@
|
||||
在 Redis 中,设置认证(AUTH)可以为你的 Redis 服务器增加一层安全性。通过设置密码,只有提供正确密码的客户端才能访问 Redis 服务器。以下是设置和使用 Redis 认证的步骤:
|
||||
|
||||
### 1. 修改 Redis 配置文件
|
||||
|
||||
首先,找到你的 Redis 配置文件(通常是 `redis.conf`)。
|
||||
|
||||
在配置文件中,找到以下行(可能是被注释掉的):
|
||||
|
||||
```
|
||||
# requirepass foobared
|
||||
```
|
||||
|
||||
|
||||
|
||||
将其取消注释并设置一个强密码,例如:
|
||||
|
||||
```
|
||||
requirepass YourStrongPasswordHere
|
||||
```
|
||||
|
||||
|
||||
|
||||
保存配置文件并重启 Redis 服务器以使更改生效:
|
||||
|
||||
```
|
||||
sudo systemctl restart redis-server
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者,如果你是手动启动 Redis 的,可以使用:
|
||||
|
||||
```
|
||||
redis-server /path/to/your/redis.conf
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 2. 使用 AUTH 连接 Redis 服务器
|
||||
|
||||
当 Redis 设置了密码之后,客户端需要在连接时提供密码。以下是不同客户端的示例:
|
||||
|
||||
#### 使用 redis-cli
|
||||
|
||||
```
|
||||
redis-cli
|
||||
> AUTH YourStrongPasswordHere
|
||||
> PING
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果认证成功,`PING` 命令将返回 `PONG`。
|
||||
|
||||
#### 使用 Python 的 redis-py
|
||||
|
||||
```
|
||||
import redis
|
||||
|
||||
r = redis.Redis(host='localhost', port=6379, password='YourStrongPasswordHere')
|
||||
print(r.ping()) # 如果认证成功,将返回 True
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 使用 Node.js 的 ioredis
|
||||
|
||||
```
|
||||
const Redis = require('ioredis');
|
||||
const redis = new Redis({
|
||||
host: 'localhost',
|
||||
port: 6379,
|
||||
password: 'YourStrongPasswordHere'
|
||||
});
|
||||
|
||||
redis.ping().then(result => {
|
||||
console.log(result); // 如果认证成功,将返回 'PONG'
|
||||
});
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 3. 在运行时设置密码
|
||||
|
||||
如果你需要在运行时设置或更改密码,可以使用 `CONFIG SET` 命令:
|
||||
|
||||
```
|
||||
redis-cli
|
||||
> CONFIG SET requirepass YourNewStrongPasswordHere
|
||||
```
|
||||
|
||||
|
||||
|
||||
请注意,使用 `CONFIG SET` 命令设置的密码不会持久化到配置文件中。如果 Redis 服务器重启,设置将丢失。因此,最好在 `redis.conf` 中设置密码以确保持久性。
|
||||
|
||||
### 4. 移除密码
|
||||
|
||||
如果你决定移除密码保护,可以将 `requirepass` 设置为空字符串:
|
||||
|
||||
```
|
||||
redis-cli
|
||||
> CONFIG SET requirepass ""
|
||||
```
|
||||
|
||||
|
||||
|
||||
或者在配置文件中注释掉 `requirepass` 行并重启 Redis 服务器。
|
||||
|
||||
### 5. 注意事项
|
||||
|
||||
1. **安全性**:确保使用强密码,并限制 Redis 服务器的网络访问权限。
|
||||
2. **持久化**:修改 `redis.conf` 文件确保密码在重启后仍然有效。
|
||||
3. **监控**:定期检查 Redis 日志和访问记录,确保未发生未经授权的访问。
|
||||
|
||||
通过这些步骤,你可以为 Redis 服务器增加一层安全保护,防止未经授权的访问。
|
||||
13
daliy_note/8月归档/8.26/samba.md
Normal file
13
daliy_note/8月归档/8.26/samba.md
Normal file
@ -0,0 +1,13 @@
|
||||
### 解决windows系统挂载omv的samba共享不能执行.exe文件的问题
|
||||
|
||||
- 打开:服务-->SMB/CIFS-->设置,在“高级设置”中的“扩展选项”中填入“acl allow execute always = True”,保存配置就可以
|
||||
|
||||

|
||||
|
||||
### 解决 Windows LTSC 版本无法连接 SMB 共享目录
|
||||
|
||||
- 因为在 LTSC 系统上默认禁止不安全的来宾的访问,需要手动配置组策略
|
||||
- 快捷键 Win + R 运行,输入 gpedit.msc 打开本地组策略编辑器
|
||||
- 依次展开「管理模版」->「网络」->「Lanman 工作站」标签
|
||||
|
||||

|
||||
11
daliy_note/8月归档/8.27/alertmanager.md
Normal file
11
daliy_note/8月归档/8.27/alertmanager.md
Normal file
@ -0,0 +1,11 @@
|
||||
### dispatcher
|
||||
|
||||
dispatch/dispatch.go
|
||||
|
||||
### route
|
||||
|
||||
dispatch/route.go
|
||||
|
||||
### tool
|
||||
|
||||
alertmanager/scripts/tools.go
|
||||
15
daliy_note/8月归档/8.28/vim.md
Normal file
15
daliy_note/8月归档/8.28/vim.md
Normal file
@ -0,0 +1,15 @@
|
||||
### Esc
|
||||
|
||||
- ctrl + [
|
||||
|
||||
### jj映射为Esc
|
||||
|
||||
- .vimrc
|
||||
|
||||
```sh
|
||||
inoremap jj <Esc>
|
||||
```
|
||||
|
||||
### 引用
|
||||
|
||||
- https://placeless.net/blog/map-jj-to-esc-for-zsh-vim-vscode-ipython-jupyterlab
|
||||
0
daliy_note/8月归档/8.29/8.29.md
Normal file
0
daliy_note/8月归档/8.29/8.29.md
Normal file
49
daliy_note/8月归档/8.29/mysql.md
Normal file
49
daliy_note/8月归档/8.29/mysql.md
Normal file
@ -0,0 +1,49 @@
|
||||
### mysql where 条件大小写
|
||||
|
||||
在 MySQL 中,`WHERE` 条件的大小写敏感性取决于所使用的字符集和排序规则(collation)。
|
||||
|
||||
### 1. 默认行为
|
||||
|
||||
- **大小写不敏感**:在大多数情况下,MySQL 的默认字符集 `latin1`和 `utf8` 使用的排序规则(如 `latin1_swedish_ci` 或 `utf8_general_ci`)都是不区分大小写的。这意味着在这些排序规则下,`WHERE` 子句将不会区分大小写。例如:
|
||||
|
||||
```
|
||||
SELECT * FROM users WHERE username = 'JohnDoe';
|
||||
```
|
||||
|
||||
该查询将返回 `johnDoe`、`JOHNDOE` 和 `JohnDoe` 等所有变体。
|
||||
|
||||
### 2. 大小写敏感
|
||||
|
||||
- **使用大小写敏感的排序规则**:如果你想要 `WHERE` 条件区分大小写,可以使用大小写敏感的排序规则,例如 `latin1_bin` 或 `utf8_bin`。例如:
|
||||
|
||||
```
|
||||
SELECT * FROM users WHERE BINARY username = 'JohnDoe';
|
||||
```
|
||||
|
||||
|
||||
|
||||
使用 `BINARY` 关键字会强制 MySQL 将 `username` 列的值视为二进制字符串,从而实现大小写敏感的比较。
|
||||
|
||||
- **指定排序规则**:你也可以在查询中显式指定排序规则。例如:
|
||||
|
||||
```
|
||||
SELECT * FROM users WHERE username COLLATE utf8_bin = 'JohnDoe';
|
||||
```
|
||||
|
||||
### 3. 修改表字符集
|
||||
|
||||
- utf8_general_ci --不区分大小写
|
||||
- utf8_bin–区分大小写
|
||||
|
||||
```sql
|
||||
ALTER TABLE temp_01 MODIFY COLUMN browser VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL;
|
||||
Query OK, 180 rows affected (0.01 sec)
|
||||
Records: 180 Duplicates: 0 Warnings: 0
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 4. 总结
|
||||
|
||||
- 默认情况下,MySQL 的 `WHERE` 条件是大小写不敏感的,除非使用了二进制比较或指定了大小写敏感的排序规则。
|
||||
- 如果想要进行大小写敏感的比较,可以使用 `BINARY` 关键字或者指定适当的排序规则。
|
||||
13
daliy_note/8月归档/8.30/go_deep_copy.md
Normal file
13
daliy_note/8月归档/8.30/go_deep_copy.md
Normal file
@ -0,0 +1,13 @@
|
||||
```go
|
||||
func DeepCopy(dst, src interface{}) error {
|
||||
var buf bytes.Buffer
|
||||
gob.Register(map[string]interface{}{})
|
||||
gob.Register([]interface{}(nil))
|
||||
gob.Register([]map[string]interface{}{})
|
||||
if err := gob.NewEncoder(&buf).Encode(src); err != nil {
|
||||
return err
|
||||
}
|
||||
return gob.NewDecoder(bytes.NewBuffer(buf.Bytes())).Decode(dst)
|
||||
}
|
||||
```
|
||||
|
||||
17
daliy_note/8月归档/8.30/go_正态分布_指数分布.md
Normal file
17
daliy_note/8月归档/8.30/go_正态分布_指数分布.md
Normal file
@ -0,0 +1,17 @@
|
||||
```go
|
||||
func ExponentialRandom(lambda float64) float64 {
|
||||
rand.Seed(time.Now().UnixNano())
|
||||
uniform := rand.Float64()
|
||||
return -lambda * math.Log(1.0-uniform)
|
||||
}
|
||||
|
||||
func NormalDistribution(mean float64, stdDev float64) float64 {
|
||||
rand.Seed(time.Now().UnixNano())
|
||||
uniform := rand.Float64()
|
||||
exponent := -math.Pow((uniform-mean), 2) / (2 * math.Pow(stdDev, 2))
|
||||
coefficient := 1 / (stdDev * math.Sqrt(2*math.Pi))
|
||||
result := coefficient * math.Exp(exponent)
|
||||
return result*stdDev + mean
|
||||
}
|
||||
```
|
||||
|
||||
77
daliy_note/8月归档/8.30/k3s.md
Normal file
77
daliy_note/8月归档/8.30/k3s.md
Normal file
@ -0,0 +1,77 @@
|
||||
### /etc/pve/lxc/301.conf
|
||||
|
||||
```
|
||||
lxc.apparmor.profile: unconfined
|
||||
lxc.cgroup.devices.allow: a
|
||||
lxc.cap.drop:
|
||||
lxc.cgroup2.devices.allow: c 10:200 rwm
|
||||
lxc.mount.entry: /dev/net/tun dev/net/tun none bind,create=file
|
||||
lxc.mount.auto: proc:rw sys:rw
|
||||
```
|
||||
|
||||
|
||||
|
||||
### /dev/kmsg
|
||||
|
||||
```bash
|
||||
cat <<'EOF' | tee /usr/local/bin/conf-kmsg.sh > /dev/null
|
||||
#!/bin/sh -e
|
||||
if [ ! -e /dev/kmsg ];then
|
||||
ln -s /dev/console /dev/kmsg
|
||||
fi
|
||||
mount --make-rshared /
|
||||
|
||||
EOF
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 开机自启
|
||||
|
||||
```bash
|
||||
chmod +x /usr/local/bin/conf-kmsg.sh
|
||||
chmod +x /etc/rc.local
|
||||
chmod +x /etc/rc.d/rc.local
|
||||
```
|
||||
|
||||
|
||||
|
||||
### /etc/rc.local
|
||||
|
||||
```
|
||||
sh /usr/local/bin/conf-kmsg.sh
|
||||
```
|
||||
|
||||
|
||||
|
||||
### ip forward
|
||||
|
||||
```bash
|
||||
echo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf
|
||||
sysctl --system
|
||||
```
|
||||
|
||||
|
||||
|
||||
### K3s_token
|
||||
|
||||
```bash
|
||||
cat /var/lib/rancher/k3s/server/node-token
|
||||
```
|
||||
|
||||
> K103ecfc393250507782a8275efe48fb3a27bfb010e14862ebfd7145448514b9f8b::server:0ef7e0ba1534843bcc8637dd8c9a31e9
|
||||
|
||||
### 主节点
|
||||
|
||||
```bash
|
||||
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_VERSION=v1.28.12+k3s1 INSTALL_K3S_MIRROR=cn sh -
|
||||
```
|
||||
|
||||
|
||||
|
||||
### agent加入集群
|
||||
|
||||
```bash
|
||||
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_VERSION=v1.28.12+k3s1 INSTALL_K3S_MIRROR=cn K3S_URL=https://192.168.0.20:6443 K3S_TOKEN=K103ecfc393250507782a8275efe48fb3a27bfb010e14862ebfd7145448514b9f8b::server:0ef7e0ba1534843bcc8637dd8c9a31e9 sh -
|
||||
```
|
||||
|
||||
6
daliy_note/8月归档/8.30/带内故障带外故障.md
Normal file
6
daliy_note/8月归档/8.30/带内故障带外故障.md
Normal file
@ -0,0 +1,6 @@
|
||||
**服务器故障可以分为带内故障和带外故障,这两种故障类型主要区别在于管理和维护的方式。**
|
||||
|
||||
- **带内故障**涉及通过服务器内部的接口进行管理和控制,这种方式可以对服务器进行实时监控和维护,但需要占用服务器的计算资源,可能会影响服务器的性能。带内管理的优点在于可以直接访问服务器的操作系统和硬件资源,进行详细的诊断和修复。然而,它的缺点是当服务器操作系统或硬件出现故障时,带内管理将无法进行,因为管理操作依赖于服务器本身的运行状态。
|
||||
- **带外故障**则是指通过专用的网卡或管理口实现对服务器的管理,这种方式不受操作系统和硬件故障的影响,提供更加稳定的管理方式。带外管理可以通过一些专用硬件设备(例如BMC、DRAC、iLO等)进行实现,也可以通过管理软件和云平台实现。带外管理的优点包括可以实现远程管理和监控,不需要物理接触服务器,同时也不会影响服务器的性能。这种管理方式非常适用于远程数据中心、云计算环境等场景,因为它可以在任何时间、任何地点对服务器进行全面的远程控制和管理。
|
||||
|
||||
综上所述,带内管理和带外管理都是服务器管理中重要的方式,各自具有自己的优势和适用范围。带内管理适用于对服务器的操作系统和硬件资源进行详细的诊断和修复,而带外管理则适用于远程管理和监控,不受操作系统和硬件故障的影响,提供更加稳定的管理方式。
|
||||
6
daliy_note/9月归档/9.10/smartctl.md
Normal file
6
daliy_note/9月归档/9.10/smartctl.md
Normal file
@ -0,0 +1,6 @@
|
||||
### 查看硬盘设备 sn
|
||||
|
||||
```bash
|
||||
smartctl -a /dev/nvme0
|
||||
```
|
||||
|
||||
83
daliy_note/9月归档/9.11/alertmanager-报警写入.md
Normal file
83
daliy_note/9月归档/9.11/alertmanager-报警写入.md
Normal file
@ -0,0 +1,83 @@
|
||||
### function 报警接收处理函数
|
||||
|
||||
```go
|
||||
func (api *API) postAlertsHandler(params alert_ops.PostAlertsParams) middleware.Responder {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 报警指纹(唯一id)生成
|
||||
|
||||
```bash
|
||||
func labelSetToFingerprint(ls LabelSet) Fingerprint {
|
||||
if len(ls) == 0 {
|
||||
return Fingerprint(emptyLabelSignature)
|
||||
}
|
||||
|
||||
labelNames := make(LabelNames, 0, len(ls))
|
||||
for labelName := range ls {
|
||||
labelNames = append(labelNames, labelName)
|
||||
}
|
||||
sort.Sort(labelNames)
|
||||
|
||||
sum := hashNew()
|
||||
for _, labelName := range labelNames {
|
||||
sum = hashAdd(sum, string(labelName))
|
||||
sum = hashAddByte(sum, SeparatorByte)
|
||||
sum = hashAdd(sum, string(ls[labelName]))
|
||||
sum = hashAddByte(sum, SeparatorByte)
|
||||
}
|
||||
return Fingerprint(sum)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 接收报警
|
||||
|
||||
```go
|
||||
func (o *PostAlerts) ServeHTTP(rw http.ResponseWriter, r *http.Request) {
|
||||
route, rCtx, _ := o.Context.RouteInfo(r)
|
||||
if rCtx != nil {
|
||||
*r = *rCtx
|
||||
}
|
||||
var Params = NewPostAlertsParams()
|
||||
if err := o.Context.BindValidRequest(r, route, &Params); err != nil { // bind params
|
||||
o.Context.Respond(rw, r, route.Produces, route, err)
|
||||
return
|
||||
}
|
||||
|
||||
res := o.Handler.Handle(Params) // actually handle the request
|
||||
o.Context.Respond(rw, r, route.Produces, route, res)
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### NewAPI时注册
|
||||
|
||||
```go'
|
||||
func NewAPI(
|
||||
alerts provider.Alerts,
|
||||
gf groupsFn,
|
||||
sf getAlertStatusFn,
|
||||
silences *silence.Silences,
|
||||
peer cluster.ClusterPeer,
|
||||
l log.Logger,
|
||||
r prometheus.Registerer,
|
||||
) (*API, error) {
|
||||
openAPI.AlertGetAlertsHandler = alert_ops.GetAlertsHandlerFunc(api.getAlertsHandler)
|
||||
openAPI.AlertPostAlertsHandler = alert_ops.PostAlertsHandlerFunc(api.postAlertsHandler)
|
||||
openAPI.AlertgroupGetAlertGroupsHandler = alertgroup_ops.GetAlertGroupsHandlerFunc(api.getAlertGroupsHandler)
|
||||
openAPI.GeneralGetStatusHandler = general_ops.GetStatusHandlerFunc(api.getStatusHandler)
|
||||
openAPI.ReceiverGetReceiversHandler = receiver_ops.GetReceiversHandlerFunc(api.getReceiversHandler)
|
||||
openAPI.SilenceDeleteSilenceHandler = silence_ops.DeleteSilenceHandlerFunc(api.deleteSilenceHandler)
|
||||
openAPI.SilenceGetSilenceHandler = silence_ops.GetSilenceHandlerFunc(api.getSilenceHandler)
|
||||
openAPI.SilenceGetSilencesHandler = silence_ops.GetSilencesHandlerFunc(api.getSilencesHandler)
|
||||
openAPI.SilencePostSilencesHandler = silence_ops.PostSilencesHandlerFunc(api.postSilencesHandler)
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
17
daliy_note/9月归档/9.11/alertmanager工作模式.md
Normal file
17
daliy_note/9月归档/9.11/alertmanager工作模式.md
Normal file
@ -0,0 +1,17 @@
|
||||
Alertmanager 是一个用于处理 Prometheus 发送的警报的工具。它支持多种模式和配置,以便更好地管理和路由警报。你提到的 "fallbck mode" 可能是 "fallback mode" 的拼写错误。以下是相关模式和概念的解释:
|
||||
|
||||
### 1. Fallback Mode
|
||||
**Fallback 模式** 是一种在主要配置或路径失效时使用的备用机制。在 Alertmanager 中,fallback 模式的一种常见用途是在某些接收器不可用时,将警报发送到备用接收器。例如,如果主要的电子邮件服务器不可用,可以配置 Alertmanager 将警报发送到备用的电子邮件服务器或其他通知渠道(如 Slack 或 PagerDuty)。
|
||||
|
||||
### 2. UTF-8 Strict Mode
|
||||
**UTF-8 严格模式** 通常指的是在处理字符串数据时,严格按照 UTF-8 编码进行解码和验证。这意味着任何不是合法 UTF-8 编码的字符串都会被拒绝或抛出错误。在 Alertmanager 的上下文中,UTF-8 严格模式可以确保接收到的警报信息(如标签和值)是按照 UTF-8 编码的,从而避免乱码或编码错误带来的问题。
|
||||
|
||||
### 3. Classic Mode
|
||||
**Classic 模式** 可能指的是 Alertmanager 的默认操作模式或配置。在这种模式下,Alertmanager 按照最基本和标准的方式处理警报,并使用默认的路由规则和接收器。与其他自定义模式或高级配置相比,classic 模式通常不包含特殊的处理逻辑或备用机制。
|
||||
|
||||
### 区别总结
|
||||
- **Fallback Mode**: 在主要配置或路径失效时启用的备用机制,确保系统的高可用性和冗余。
|
||||
- **UTF-8 Strict Mode**: 严格按照 UTF-8 编码处理字符串数据,确保数据的正确性和一致性。
|
||||
- **Classic Mode**: 默认的操作模式或配置,使用标准的路由规则和接收器处理警报。
|
||||
|
||||
这些模式和概念的选择和使用取决于具体的应用场景和需求。合理配置和使用这些模式可以提高系统的可靠性和稳定性。
|
||||
71
daliy_note/9月归档/9.11/gossip.md
Normal file
71
daliy_note/9月归档/9.11/gossip.md
Normal file
@ -0,0 +1,71 @@
|
||||
在计算机科学和分布式系统中,“Gossip” 通常指的是一种用于信息传播和一致性维护的协议或算法。这种协议模拟了人类社会中的八卦(gossip)传播方式,即通过节点之间随机地交流信息,使得整个网络逐渐达成共识或传播信息。以下是 Gossip 协议的详细介绍:
|
||||
|
||||
### Gossip 协议的基本概念
|
||||
|
||||
1. **信息传播**:
|
||||
在 Gossip 协议中,每个节点会随机选择一个或多个其他节点,并将自己知道的信息传递给这些节点。接收到信息的节点再继续传播给其他节点,类似于病毒传播或人类口耳相传的八卦。
|
||||
|
||||
2. **随机选择**:
|
||||
Gossip 协议依赖于节点之间的随机选择和通信,这种随机性确保了信息能够广泛而迅速地传播到整个网络。
|
||||
|
||||
3. **去中心化**:
|
||||
Gossip 协议通常是去中心化的,没有单点故障。每个节点都可以独立地执行 Gossip 操作,这使得系统具有高可用性和容错性。
|
||||
|
||||
### Gossip 协议的特点
|
||||
|
||||
1. **鲁棒性**:
|
||||
Gossip 协议对节点故障和网络分区具有较高的容错性。即使部分节点失效,信息仍然可以通过其他节点传播。
|
||||
|
||||
2. **可扩展性**:
|
||||
由于 Gossip 协议是去中心化的,它非常适合大规模分布式系统,能够在大量节点之间有效传播信息。
|
||||
|
||||
3. **一致性**:
|
||||
Gossip 协议可以用于维护系统的一致性,例如分布式数据库中的数据一致性、分布式缓存中的缓存一致性等。
|
||||
|
||||
4. **最终一致性**:
|
||||
Gossip 协议通常提供最终一致性(Eventual Consistency),即在没有新的更新的情况下,所有节点最终会收敛到相同的状态。
|
||||
|
||||
### 常见应用场景
|
||||
|
||||
1. **分布式数据库**:
|
||||
Gossip 协议被广泛用于分布式数据库系统,如 Apache Cassandra 和 Amazon DynamoDB,用于节点间的元数据传播和一致性维护。
|
||||
|
||||
2. **分布式缓存**:
|
||||
在分布式缓存系统中,Gossip 协议用于同步缓存节点之间的缓存状态和失效信息。
|
||||
|
||||
3. **集群管理**:
|
||||
在分布式集群管理和监控系统中,Gossip 协议用于节点状态的传播和故障检测。
|
||||
|
||||
4. **区块链**:
|
||||
在一些区块链网络中,Gossip 协议用于区块和交易信息的传播。
|
||||
|
||||
### Gossip 协议的实现
|
||||
|
||||
Gossip 协议的实现通常包括以下步骤:
|
||||
|
||||
1. **节点选择**:
|
||||
每个节点定期随机选择一个或多个其他节点进行通信。选择方式可以是完全随机的,也可以是基于某些策略的(例如最近最少交流)。
|
||||
|
||||
2. **信息交换**:
|
||||
选定的节点之间交换信息。这些信息可以是节点状态、数据更新、故障报告等。
|
||||
|
||||
3. **信息传播**:
|
||||
接收到信息的节点继续选择其他节点进行信息传播,直到信息在整个网络中传播开来。
|
||||
|
||||
4. **收敛性**:
|
||||
通过多轮 Gossip 操作,信息逐渐在整个网络中传播并收敛到一致的状态。
|
||||
|
||||
### 示例
|
||||
|
||||
假设有一个分布式系统包含四个节点 A、B、C 和 D,每个节点定期与其他节点进行 Gossip 操作:
|
||||
|
||||
1. 节点 A 将自己知道的信息传递给节点 B。
|
||||
2. 节点 B 接收到信息后,又将其传递给节点 C。
|
||||
3. 节点 C 再将信息传递给节点 D。
|
||||
4. 节点 D 最后将信息传递给节点 A。
|
||||
|
||||
通过多次这样的操作,所有节点最终都会知道相同的信息。
|
||||
|
||||
### 总结
|
||||
|
||||
Gossip 协议是一种用于分布式系统中信息传播和一致性维护的去中心化协议。它通过节点之间的随机通信,确保信息能够有效地传播到整个网络。Gossip 协议具有鲁棒性、可扩展性和最终一致性的特点,广泛应用于分布式数据库、分布式缓存、集群管理和区块链等领域。
|
||||
59
daliy_note/9月归档/9.11/openstack与k8s.md
Normal file
59
daliy_note/9月归档/9.11/openstack与k8s.md
Normal file
@ -0,0 +1,59 @@
|
||||
OpenStack 和 Kubernetes 是两种不同类型的云计算和容器编排平台,但它们可以相互协作,以提供更全面的云服务。以下是对 OpenStack 和 Kubernetes 的比较及其协作方式的简要介绍:
|
||||
|
||||
### OpenStack
|
||||
|
||||
**主要用途**: OpenStack 主要用于创建和管理虚拟化的基础设施。它提供计算、存储和网络资源,类似于基础设施即服务(IaaS)平台。
|
||||
|
||||
**核心组件**:
|
||||
- **Nova**: 虚拟机管理
|
||||
- **Swift**: 对象存储
|
||||
- **Cinder**: 块存储
|
||||
- **Neutron**: 网络服务
|
||||
- **Keystone**: 身份认证
|
||||
- **Glance**: 镜像管理
|
||||
- **Horizon**: Web 仪表盘
|
||||
|
||||
### Kubernetes
|
||||
|
||||
**主要用途**: Kubernetes 主要用于容器的编排和管理。它帮助部署、扩展和管理容器化应用,类似于容器即服务(CaaS)平台。
|
||||
|
||||
**核心组件**:
|
||||
- **Pod**: 最小部署单元,包含一个或多个容器
|
||||
- **Service**: 为一组 Pod 提供网络访问
|
||||
- **Deployment**: 管理 Pod 的声明式更新
|
||||
- **ConfigMap 和 Secret**: 配置和敏感信息管理
|
||||
- **Ingress**: HTTP 和 HTTPS 路由
|
||||
|
||||
### 比较
|
||||
|
||||
1. **基础架构管理 vs 应用管理**:
|
||||
- **OpenStack**: 专注于虚拟机、存储和网络等基础设施资源的管理。
|
||||
- **Kubernetes**: 专注于容器和应用的编排与管理。
|
||||
|
||||
2. **虚拟机 vs 容器**:
|
||||
- **OpenStack**: 管理虚拟机和裸金属服务器。
|
||||
- **Kubernetes**: 管理容器和容器化应用。
|
||||
|
||||
3. **服务类型**:
|
||||
- **OpenStack**: 提供 IaaS 服务。
|
||||
- **Kubernetes**: 提供 CaaS 服务。
|
||||
|
||||
### 协作
|
||||
|
||||
OpenStack 和 Kubernetes 可以相互集成,从而提供更强大的云解决方案。以下是一些常见的集成方式:
|
||||
|
||||
1. **使用 OpenStack 作为 Kubernetes 的底层基础设施**:
|
||||
- **计算资源**: Kubernetes 可以在 OpenStack 的虚拟机上运行,利用 Nova 提供的计算资源。
|
||||
- **存储资源**: Kubernetes 可以利用 OpenStack 的 Cinder 或 Swift 作为持久化存储解决方案。
|
||||
- **网络资源**: Kubernetes 可以使用 OpenStack 的 Neutron 提供的网络功能,管理 Pod 的网络配置。
|
||||
|
||||
2. **Kubernetes on OpenStack**: 这是一个常见的部署模式,其中 Kubernetes 集群运行在 OpenStack 提供的虚拟机上。OpenStack 提供底层基础设施,Kubernetes 管理容器化应用。
|
||||
|
||||
3. **OpenStack Magnum**: OpenStack 提供了一个名为 Magnum 的服务,用于在 OpenStack 上管理容器编排引擎(如 Kubernetes、Docker Swarm 和 Mesos)。Magnum 使得在 OpenStack 环境中部署和管理 Kubernetes 集群变得更加容易。
|
||||
|
||||
### 示例场景
|
||||
|
||||
- **企业私有云**: 企业可以使用 OpenStack 构建私有云基础设施,并在其上运行 Kubernetes,管理和编排容器化应用。
|
||||
- **混合云和多云部署**: 企业可以利用 OpenStack 提供的虚拟化资源,同时通过 Kubernetes 管理跨多个云环境的容器化应用,实现灵活的资源调度和高可用性。
|
||||
|
||||
总的来说,OpenStack 和 Kubernetes 各有侧重,但它们的结合可以提供从基础设施到应用的全栈云计算解决方案。
|
||||
1
daliy_note/9月归档/9.13/alertmanager流程图.md
Normal file
1
daliy_note/9月归档/9.13/alertmanager流程图.md
Normal file
@ -0,0 +1 @@
|
||||
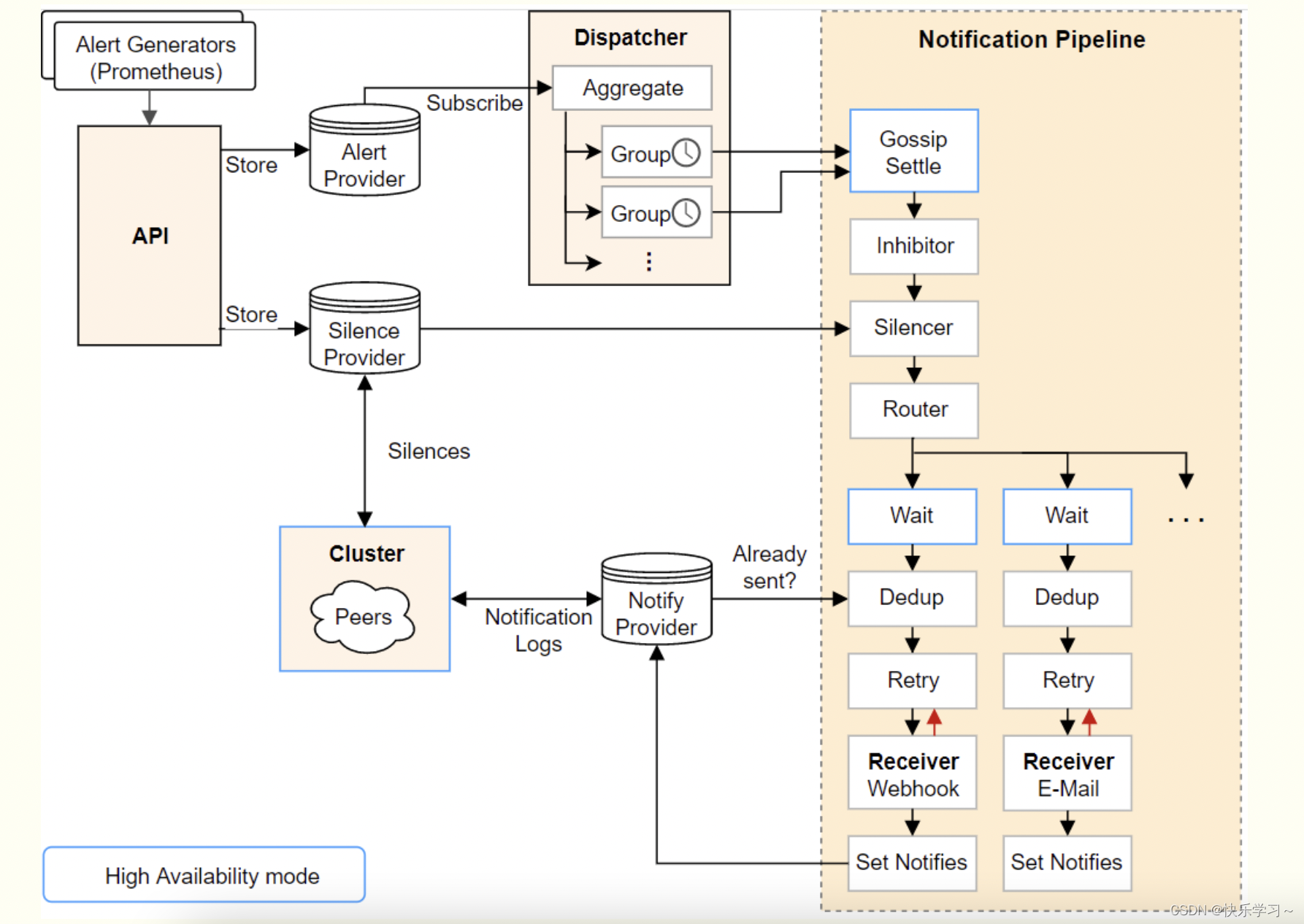
|
||||
18
daliy_note/9月归档/9.13/macos安装picgo.md
Normal file
18
daliy_note/9月归档/9.13/macos安装picgo.md
Normal file
@ -0,0 +1,18 @@
|
||||
### 提示软件已经损坏,移到废纸篓
|
||||
|
||||
#### 允许mac安装和打开任何来源
|
||||
|
||||
- 回车后,输入电脑开机密码
|
||||
|
||||
```bash
|
||||
sudo spctl --master-disable
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 移除picgoapp的签名验证
|
||||
|
||||
```bash
|
||||
xattr -cr /Applications/PicGo.app
|
||||
```
|
||||
|
||||
97
daliy_note/9月归档/9.18/gin框架.md
Normal file
97
daliy_note/9月归档/9.18/gin框架.md
Normal file
@ -0,0 +1,97 @@
|
||||
### 设置router时,传递多个HandlerFunc
|
||||
|
||||
```go
|
||||
|
||||
// HandlerFunc defines the handler used by gin middleware as return value.
|
||||
type HandlerFunc func(*Context)
|
||||
```
|
||||
|
||||
|
||||
|
||||
在 Go 语言的 Gin Web 框架中,设置路由时传递多个 `HandlerFunc` 的目的是为了实现中间件机制。中间件是指在处理请求的过程中,能够在请求到达最终处理函数之前或响应返回客户端之前,对请求和响应进行预处理或后处理的一些函数。
|
||||
|
||||
### 中间件的用途
|
||||
|
||||
中间件可以用于多种场景,包括但不限于:
|
||||
|
||||
1. **日志记录**:记录每个请求的详细信息,如请求路径、方法、处理时间等。
|
||||
2. **认证与授权**:检查用户是否已登录,是否有权限访问某些资源。
|
||||
3. **错误处理**:捕获和处理请求处理过程中的错误,返回统一的错误响应。
|
||||
4. **请求修改**:在请求到达最终处理函数之前,对请求进行修改,如解析和验证请求参数。
|
||||
5. **响应处理**:在响应返回给客户端之前,对响应进行修改,如添加响应头、格式化响应数据等。
|
||||
|
||||
### 示例
|
||||
|
||||
例如,你可以定义一个简单的中间件来记录请求的处理时间:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
"time"
|
||||
|
||||
"github.com/gin-gonic/gin"
|
||||
)
|
||||
|
||||
// 定义一个中间件函数
|
||||
func LoggerMiddleware(c *gin.Context) {
|
||||
start := time.Now()
|
||||
c.Next() // 处理请求
|
||||
|
||||
// 请求处理完成后执行以下代码
|
||||
duration := time.Since(start)
|
||||
log.Printf("Request processed in %v", duration)
|
||||
}
|
||||
|
||||
func main() {
|
||||
r := gin.Default()
|
||||
|
||||
// 使用中间件
|
||||
r.GET("/ping", LoggerMiddleware, func(c *gin.Context) {
|
||||
c.JSON(200, gin.H{
|
||||
"message": "pong",
|
||||
})
|
||||
})
|
||||
|
||||
r.Run() // 监听并在 0.0.0.0:8080 上启动服务
|
||||
}
|
||||
```
|
||||
|
||||
在这个例子中,`LoggerMiddleware` 是一个中间件函数,它会记录每个请求的处理时间。`c.Next()` 用于调用下一个中间件或最终的处理函数。
|
||||
|
||||
### 使用多个中间件
|
||||
|
||||
你可以传递多个 `HandlerFunc` 来设置多个中间件。例如,假设你有两个中间件,一个用于日志记录,一个用于认证:
|
||||
|
||||
```go
|
||||
func AuthMiddleware(c *gin.Context) {
|
||||
// 这里进行认证逻辑
|
||||
token := c.GetHeader("Authorization")
|
||||
if token != "valid-token" {
|
||||
c.JSON(401, gin.H{"error": "Unauthorized"})
|
||||
c.Abort() // 终止请求的进一步处理
|
||||
return
|
||||
}
|
||||
c.Next()
|
||||
}
|
||||
|
||||
func main() {
|
||||
r := gin.Default()
|
||||
|
||||
// 使用多个中间件
|
||||
r.GET("/secure", LoggerMiddleware, AuthMiddleware, func(c *gin.Context) {
|
||||
c.JSON(200, gin.H{
|
||||
"message": "secure data",
|
||||
})
|
||||
})
|
||||
|
||||
r.Run() // 监听并在 0.0.0.0:8080 上启动服务
|
||||
}
|
||||
```
|
||||
|
||||
在这个例子中,`LoggerMiddleware` 和 `AuthMiddleware` 会按顺序执行,然后再执行最终的处理函数。如果认证失败,中间件会终止请求处理并返回 401 错误。
|
||||
|
||||
### 总结
|
||||
|
||||
在 Gin 中传递多个 `HandlerFunc` 是为了实现中间件机制,中间件可以在请求处理的不同阶段执行特定的逻辑,从而提供更好的代码组织和复用性。中间件在处理请求时按照传递的顺序依次执行,`c.Next()` 用于调用下一个中间件或最终处理函数。
|
||||
31
daliy_note/9月归档/9.19/AIOps.md
Normal file
31
daliy_note/9月归档/9.19/AIOps.md
Normal file
@ -0,0 +1,31 @@
|
||||
AIOps(Artificial Intelligence for IT Operations)的概念起源于将人工智能(AI)技术应用于IT运维(IT Operations)领域。其目的是通过自动化和智能化手段来提升IT运维的效率和效果。AIOps综合了大数据、机器学习、人工智能等技术,帮助企业更好地管理和优化其IT基础设施和应用服务。
|
||||
|
||||
### AIOps的核心概念
|
||||
|
||||
1. **数据收集与整合**:AIOps平台能够从多个数据源(如日志、监控系统、事件管理系统等)中收集数据,并对这些数据进行整合和预处理。
|
||||
2. **实时监控与分析**:通过实时监控IT环境中的各种指标,AIOps平台可以对数据进行实时分析,识别出潜在的问题和风险。
|
||||
3. **异常检测与告警**:利用机器学习算法,AIOps平台能够检测出异常行为,并在问题发生之前发出告警。
|
||||
4. **根因分析**:AIOps平台可以通过自动化分析和关联性算法,快速定位问题的根因,减少故障排除的时间。
|
||||
5. **自动化响应与修复**:在检测到问题后,AIOps平台可以自动化执行一些预定义的修复操作,减少人工干预。
|
||||
6. **持续优化**:通过不断学习和优化,AIOps平台可以逐渐提升其检测和响应的准确性和效率。
|
||||
|
||||
### AIOps的作用
|
||||
|
||||
1. **提高运维效率**:通过自动化监控、告警和修复,AIOps减少了人工干预,提高了运维效率。
|
||||
2. **提升服务稳定性**:AIOps可以实时监控和分析系统状态,提前发现和解决潜在问题,减少系统宕机时间。
|
||||
3. **加快问题解决速度**:利用根因分析功能,AIOps能够快速定位问题的根本原因,缩短故障排除时间。
|
||||
4. **降低运维成本**:通过自动化手段减少人工操作,AIOps可以降低运维成本,同时减少人为错误的发生。
|
||||
5. **数据驱动决策**:AIOps平台提供的数据分析和报告功能,可以帮助运维团队做出更为精准的数据驱动决策。
|
||||
6. **提升用户体验**:通过减少系统故障和提升系统性能,AIOps可以显著提升最终用户的体验。
|
||||
|
||||
### AIOps的应用场景
|
||||
|
||||
1. **故障检测与预测**:利用机器学习模型,AIOps可以预测可能的故障,并提前采取预防措施。
|
||||
2. **性能优化**:通过分析监控数据,AIOps可以识别性能瓶颈并提供优化建议。
|
||||
3. **事件关联与根因分析**:AIOps可以自动关联多个事件,帮助快速定位问题的根本原因。
|
||||
4. **自动化运维**:通过预定义的自动化脚本,AIOps可以在检测到问题后自动执行修复操作。
|
||||
5. **容量规划**:通过对历史数据的分析,AIOps能够帮助企业进行容量规划,确保资源的合理分配。
|
||||
|
||||
### 总结
|
||||
|
||||
AIOps是现代IT运维发展的重要方向,通过引入人工智能技术,AIOps能够大幅提升运维的自动化和智能化水平,从而提高效率、降低成本、提升系统稳定性和用户体验。随着大数据和AI技术的不断发展,AIOps必将在更多的企业和场景中得到广泛应用。
|
||||
6
daliy_note/9月归档/9.2/9.2.md
Normal file
6
daliy_note/9月归档/9.2/9.2.md
Normal file
@ -0,0 +1,6 @@
|
||||
### mysql 客户端中文
|
||||
|
||||
```sh
|
||||
set names utf8;
|
||||
```
|
||||
|
||||
28
daliy_note/9月归档/9.20/OCI.md
Normal file
28
daliy_note/9月归档/9.20/OCI.md
Normal file
@ -0,0 +1,28 @@
|
||||
**开放容器倡议(Open Container Initiative,简称 OCI)** 是由 **Linux 基金会(Linux Foundation)** 在 2015 年 6 月发起的一个开源项目。其主要目标是为 **容器(Container)** 技术制定开放的行业标准,包括容器的 **规范化格式** 和 **运行时规范**,以促进不同容器平台之间的互操作性,避免供应商锁定,推动容器生态系统的健康发展。
|
||||
|
||||
### 产生背景:
|
||||
|
||||
在容器技术快速发展的过程中,市场上出现了多种容器格式和运行时实现方式,如 Docker、rkt 等。由于缺乏统一的标准,导致不同容器技术之间缺乏兼容性,给开发者和运营者带来了挑战。为了解决这一问题,Docker 公司与其他行业领导者共同发起了 OCI,希望通过制定统一的标准,促进容器技术的广泛采用和互操作性。
|
||||
|
||||
### 主要工作:
|
||||
|
||||
OCI 的主要工作是制定和维护以下两大规范:
|
||||
|
||||
1. **容器运行时规范(Runtime Specification)**:
|
||||
- 定义了容器运行时的标准,包括容器的创建、配置、执行和生命周期管理等方面。
|
||||
- 规范描述了容器运行时应该如何解读容器配置,如何设置容器的环境,以及如何启动应用程序等。
|
||||
- **`runc`** 是一个符合 OCI 运行时规范的参考实现,由 OCI 社区维护。
|
||||
2. **容器镜像规范(Image Specification)**:
|
||||
- 定义了容器镜像的格式和结构,包括镜像的清单、层次结构、配置和元数据等。
|
||||
- 旨在确保容器镜像可以在不同的容器引擎和运行时之间互相兼容和传输。
|
||||
- **`umoci`** 是一个符合 OCI 镜像规范的参考工具,用于操作 OCI 镜像。
|
||||
|
||||
### 影响和意义:
|
||||
|
||||
- **互操作性**:通过制定统一的规范,OCI 促进了不同容器技术和平台之间的兼容性,使开发者和运营者可以更加灵活地选择容器工具和服务。
|
||||
- **生态系统健康发展**:避免了由于标准缺失导致的供应商锁定,有利于容器技术的创新和生态系统的繁荣。
|
||||
- **社区合作**:汇集了行业内的主要参与者,包括技术公司、云服务提供商和开源社区,共同参与规范的制定和实施。
|
||||
|
||||
### 总结:
|
||||
|
||||
开放容器倡议(OCI)在容器技术发展的关键时期,为容器格式和运行时制定了开放的行业标准。这些标准为容器技术的广泛应用奠定了基础,促进了容器生态系统的开放性和可移植性,对云计算、微服务和 DevOps 等领域的发展产生了深远的影响。
|
||||
257
daliy_note/9月归档/9.20/helm-hook.md
Normal file
257
daliy_note/9月归档/9.20/helm-hook.md
Normal file
@ -0,0 +1,257 @@
|
||||
Helm 的 Hooks 是一种机制,允许用户在 Chart 的生命周期的某些关键点执行自定义操作。Hooks 可以用于执行初始化任务、清理任务、备份操作等。以下是 Helm 支持的一些常用 Hooks 以及它们的触发点:
|
||||
|
||||
### 常用 Hooks
|
||||
|
||||
#### 1. `pre-install`
|
||||
- **触发点**:在 Helm 安装 Chart 之前执行。
|
||||
- **用途**:用于初始化或准备操作,如创建必要的资源。
|
||||
|
||||
#### 2. `post-install`
|
||||
- **触发点**:在 Helm 安装 Chart 之后执行。
|
||||
- **用途**:用于执行后续操作,如配置或通知。
|
||||
|
||||
#### 3. `pre-delete`
|
||||
- **触发点**:在 Helm 删除 Chart 之前执行。
|
||||
- **用途**:用于执行清理操作,确保资源正确释放。
|
||||
|
||||
#### 4. `post-delete`
|
||||
- **触发点**:在 Helm 删除 Chart 之后执行。
|
||||
- **用途**:用于执行后续清理任务或通知。
|
||||
|
||||
#### 5. `pre-upgrade`
|
||||
- **触发点**:在 Helm 升级 Chart 之前执行。
|
||||
- **用途**:用于准备升级操作,如备份数据。
|
||||
|
||||
#### 6. `post-upgrade`
|
||||
- **触发点**:在 Helm 升级 Chart 之后执行。
|
||||
- **用途**:用于执行后续操作或验证升级结果。
|
||||
|
||||
#### 7. `pre-rollback`
|
||||
- **触发点**:在 Helm 回滚 Chart 之前执行。
|
||||
- **用途**:用于准备回滚操作。
|
||||
|
||||
#### 8. `post-rollback`
|
||||
- **触发点**:在 Helm 回滚 Chart 之后执行。
|
||||
- **用途**:用于执行回滚后的操作。
|
||||
|
||||
#### 9. `test`
|
||||
- **触发点**:专用于测试操作。
|
||||
- **用途**:用于运行测试用例,验证 Chart 部署是否成功。
|
||||
|
||||
### 使用 Hook 的示例
|
||||
|
||||
在 Helm Chart 的模板文件中,使用注解来定义 Hook。例如,一个简单的 ConfigMap 资源可以在安装之前创建:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: ConfigMap
|
||||
metadata:
|
||||
name: my-config
|
||||
annotations:
|
||||
"helm.sh/hook": pre-install
|
||||
data:
|
||||
my-value: "This is a pre-install hook"
|
||||
```
|
||||
|
||||
### Hook 的生命周期
|
||||
|
||||
1. **安装(Install)**:
|
||||
- `pre-install`
|
||||
- Chart 安装
|
||||
- `post-install`
|
||||
|
||||
2. **升级(Upgrade)**:
|
||||
- `pre-upgrade`
|
||||
- Chart 升级
|
||||
- `post-upgrade`
|
||||
|
||||
3. **删除(Delete)**:
|
||||
- `pre-delete`
|
||||
- Chart 删除
|
||||
- `post-delete`
|
||||
|
||||
4. **回滚(Rollback)**:
|
||||
- `pre-rollback`
|
||||
- Chart 回滚
|
||||
- `post-rollback`
|
||||
|
||||
### Hook 的策略
|
||||
|
||||
你还可以为 Hook 定义策略,以控制它们的行为。这些策略通过注解指定:
|
||||
|
||||
- **`"helm.sh/hook-delete-policy"`**:定义 Hook 执行完毕后的删除策略。
|
||||
- `hook-succeeded`:当 Hook 成功时删除。
|
||||
- `hook-failed`:当 Hook 失败时删除。
|
||||
- `before-hook-creation`:在创建新的 Hook 资源之前删除旧的 Hook 资源。
|
||||
|
||||
示例:
|
||||
|
||||
```yaml
|
||||
apiVersion: batch/v1
|
||||
kind: Job
|
||||
metadata:
|
||||
name: test-job
|
||||
annotations:
|
||||
"helm.sh/hook": test
|
||||
"helm.sh/hook-delete-policy": hook-succeeded
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: test-container
|
||||
image: busybox
|
||||
command: ['sh', '-c', 'echo Hello, Helm!']
|
||||
restartPolicy: Never
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
Helm 的 Hooks 提供了在 Chart 生命周期的关键点上执行自定义操作的灵活性,使得 Chart 的管理和部署更加细粒度和可控。掌握和使用这些 Hooks,可以让你的 Helm Chart 更加健壮和自动化。
|
||||
|
||||
---
|
||||
|
||||
当然,以下是上边例子的详细解释,包括其执行过程和作用:
|
||||
|
||||
### 示例解释
|
||||
|
||||
这个示例是一个 Kubernetes `Job` 资源,带有 Helm Hook 的注解。具体内容如下:
|
||||
|
||||
```yaml
|
||||
apiVersion: batch/v1
|
||||
kind: Job
|
||||
metadata:
|
||||
name: test-job
|
||||
annotations:
|
||||
"helm.sh/hook": test
|
||||
"helm.sh/hook-delete-policy": hook-succeeded
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: test-container
|
||||
image: busybox
|
||||
command: ['sh', '-c', 'echo Hello, Helm!']
|
||||
restartPolicy: Never
|
||||
```
|
||||
|
||||
### 细节解释
|
||||
|
||||
1. **资源类型**:
|
||||
- `apiVersion: batch/v1` 和 `kind: Job` 表明这是一个 Kubernetes `Job` 资源。
|
||||
- `Job` 资源在 Kubernetes 中用于一次性的任务,通常会在完成后自动退出。
|
||||
|
||||
2. **元数据**:
|
||||
- `metadata` 部分包含了资源的名称 `test-job`。
|
||||
- `annotations` 部分包含了 Helm Hook 的注解:
|
||||
- `"helm.sh/hook": test` 表示这个 `Job` 是一个测试 Hook。
|
||||
- `"helm.sh/hook-delete-policy": hook-succeeded` 表示当这个 `Job` 成功完成后,Helm 会删除它。
|
||||
|
||||
3. **Job 规范**:
|
||||
- `spec` 部分定义了 `Job` 的具体行为。
|
||||
- `template` 部分定义了 `Pod` 模板,这个 `Pod` 包含一个名为 `test-container` 的容器。
|
||||
- 容器使用 `busybox` 镜像,并且执行命令 `echo Hello, Helm!`。
|
||||
- `restartPolicy: Never` 表示这个 `Pod` 在完成任务后不会重新启动。
|
||||
|
||||
### 执行过程
|
||||
|
||||
1. **安装 Chart**:
|
||||
- 当你执行 `helm install` 命令来安装 Chart 时:
|
||||
```sh
|
||||
helm install <release_name> <chart_name>
|
||||
```
|
||||
- Helm 会识别并执行这个 `Job`,因为它带有 `"helm.sh/hook": test` 注解。
|
||||
|
||||
2. **执行 Hook**:
|
||||
- `Job` 资源会被创建并启动。
|
||||
- 容器会执行命令 `echo Hello, Helm!`,将 "Hello, Helm!" 输出到控制台。
|
||||
|
||||
3. **删除 Hook**:
|
||||
- 因为这个 Hook 带有 `"helm.sh/hook-delete-policy": hook-succeeded` 注解,当 `Job` 成功完成(即输出 "Hello, Helm!" 并退出)后,Helm 会自动删除这个 `Job` 资源。
|
||||
|
||||
### 总结
|
||||
|
||||
这个示例展示了如何使用 Helm 的 `test` Hook 来运行一个一次性的任务,并在任务成功完成后自动清理资源。具体流程如下:
|
||||
|
||||
1. Helm 识别到 `Job` 资源带有 `test` Hook 注解。
|
||||
2. Helm 在安装过程中执行这个 `Job`。
|
||||
3. `Job` 成功完成任务(输出 "Hello, Helm!")。
|
||||
4. Helm 根据 `hook-delete-policy` 注解自动删除 `Job` 资源。
|
||||
|
||||
通过这种方式,你可以在 Helm Chart 中定义各种自定义任务,并确保在任务完成后自动清理资源,从而保持集群的整洁和高效。
|
||||
|
||||
---
|
||||
|
||||
多个hook执行顺序
|
||||
|
||||
当然,以下是上边例子的详细解释,包括其执行过程和作用:
|
||||
|
||||
### 示例解释
|
||||
|
||||
这个示例是一个 Kubernetes `Job` 资源,带有 Helm Hook 的注解。具体内容如下:
|
||||
|
||||
```yaml
|
||||
apiVersion: batch/v1
|
||||
kind: Job
|
||||
metadata:
|
||||
name: test-job
|
||||
annotations:
|
||||
"helm.sh/hook": test
|
||||
"helm.sh/hook-delete-policy": hook-succeeded
|
||||
spec:
|
||||
template:
|
||||
spec:
|
||||
containers:
|
||||
- name: test-container
|
||||
image: busybox
|
||||
command: ['sh', '-c', 'echo Hello, Helm!']
|
||||
restartPolicy: Never
|
||||
```
|
||||
|
||||
### 细节解释
|
||||
|
||||
1. **资源类型**:
|
||||
- `apiVersion: batch/v1` 和 `kind: Job` 表明这是一个 Kubernetes `Job` 资源。
|
||||
- `Job` 资源在 Kubernetes 中用于一次性的任务,通常会在完成后自动退出。
|
||||
|
||||
2. **元数据**:
|
||||
- `metadata` 部分包含了资源的名称 `test-job`。
|
||||
- `annotations` 部分包含了 Helm Hook 的注解:
|
||||
- `"helm.sh/hook": test` 表示这个 `Job` 是一个测试 Hook。
|
||||
- `"helm.sh/hook-delete-policy": hook-succeeded` 表示当这个 `Job` 成功完成后,Helm 会删除它。
|
||||
|
||||
3. **Job 规范**:
|
||||
- `spec` 部分定义了 `Job` 的具体行为。
|
||||
- `template` 部分定义了 `Pod` 模板,这个 `Pod` 包含一个名为 `test-container` 的容器。
|
||||
- 容器使用 `busybox` 镜像,并且执行命令 `echo Hello, Helm!`。
|
||||
- `restartPolicy: Never` 表示这个 `Pod` 在完成任务后不会重新启动。
|
||||
|
||||
### 执行过程
|
||||
|
||||
1. **安装 Chart**:
|
||||
- 当你执行 `helm install` 命令来安装 Chart 时:
|
||||
```sh
|
||||
helm install <release_name> <chart_name>
|
||||
```
|
||||
- Helm 会识别并执行这个 `Job`,因为它带有 `"helm.sh/hook": test` 注解。
|
||||
|
||||
2. **执行 Hook**:
|
||||
- `Job` 资源会被创建并启动。
|
||||
- 容器会执行命令 `echo Hello, Helm!`,将 "Hello, Helm!" 输出到控制台。
|
||||
|
||||
3. **删除 Hook**:
|
||||
- 因为这个 Hook 带有 `"helm.sh/hook-delete-policy": hook-succeeded` 注解,当 `Job` 成功完成(即输出 "Hello, Helm!" 并退出)后,Helm 会自动删除这个 `Job` 资源。
|
||||
|
||||
### 总结
|
||||
|
||||
这个示例展示了如何使用 Helm 的 `test` Hook 来运行一个一次性的任务,并在任务成功完成后自动清理资源。具体流程如下:
|
||||
|
||||
1. Helm 识别到 `Job` 资源带有 `test` Hook 注解。
|
||||
2. Helm 在安装过程中执行这个 `Job`。
|
||||
3. `Job` 成功完成任务(输出 "Hello, Helm!")。
|
||||
4. Helm 根据 `hook-delete-policy` 注解自动删除 `Job` 资源。
|
||||
|
||||
通过这种方式,你可以在 Helm Chart 中定义各种自定义任务,并确保在任务完成后自动清理资源,从而保持集群的整洁和高效。
|
||||
|
||||
---
|
||||
|
||||
https://helm.sh/zh/docs/topics/charts_hooks/
|
||||
147
daliy_note/9月归档/9.20/helm.md
Normal file
147
daliy_note/9月归档/9.20/helm.md
Normal file
@ -0,0 +1,147 @@
|
||||
Helm 是 Kubernetes 的包管理器,用于管理 Kubernetes 应用程序。以下是一些常用的 Helm 命令,帮助你在 Kubernetes 集群中更有效地管理应用程序。
|
||||
|
||||
### 基本命令
|
||||
|
||||
#### 1. 安装 Chart
|
||||
```sh
|
||||
helm install <release_name> <chart_name>
|
||||
```
|
||||
- `release_name`:指定这次安装的名称。
|
||||
- `chart_name`:指定要安装的 Chart 名称。
|
||||
|
||||
#### 2. 升级 Release
|
||||
```sh
|
||||
helm upgrade <release_name> <chart_name>
|
||||
```
|
||||
- `release_name`:要升级的 Release 的名称。
|
||||
- `chart_name`:新的 Chart 名称或路径。
|
||||
|
||||
#### 3. 卸载 Release
|
||||
```sh
|
||||
helm uninstall <release_name>
|
||||
```
|
||||
- `release_name`:要卸载的 Release 的名称。
|
||||
|
||||
#### 4. 查看 Release
|
||||
```sh
|
||||
helm list
|
||||
```
|
||||
- 列出所有已安装的 Release。
|
||||
|
||||
#### 5. 查看 Release 状态
|
||||
```sh
|
||||
helm status <release_name>
|
||||
```
|
||||
- 查看指定 Release 的状态。
|
||||
|
||||
#### 6. 查看 Release 历史
|
||||
```sh
|
||||
helm history <release_name>
|
||||
```
|
||||
- 查看指定 Release 的历史记录。
|
||||
|
||||
### Chart 管理
|
||||
|
||||
#### 7. 搜索 Chart
|
||||
```sh
|
||||
helm search hub <keyword>
|
||||
```
|
||||
- 在 Helm Hub 中搜索 Chart。
|
||||
|
||||
```sh
|
||||
helm search repo <keyword>
|
||||
```
|
||||
- 在已添加的仓库中搜索 Chart。
|
||||
|
||||
#### 8. 添加仓库
|
||||
```sh
|
||||
helm repo add <repo_name> <repo_url>
|
||||
```
|
||||
- `repo_name`:仓库的名称。
|
||||
- `repo_url`:仓库的 URL。
|
||||
|
||||
#### 9. 更新仓库
|
||||
```sh
|
||||
helm repo update
|
||||
```
|
||||
- 更新所有已添加仓库的信息。
|
||||
|
||||
#### 10. 列出仓库
|
||||
```sh
|
||||
helm repo list
|
||||
```
|
||||
- 列出所有已添加的仓库。
|
||||
|
||||
#### 11. 移除仓库
|
||||
```sh
|
||||
helm repo remove <repo_name>
|
||||
```
|
||||
- 移除指定的仓库。
|
||||
|
||||
### Chart 开发
|
||||
|
||||
#### 12. 创建新的 Chart
|
||||
```sh
|
||||
helm create <chart_name>
|
||||
```
|
||||
- 创建一个新的 Chart 目录结构。
|
||||
|
||||
#### 13. 打包 Chart
|
||||
```sh
|
||||
helm package <chart_path>
|
||||
```
|
||||
- 将指定目录下的 Chart 打包成 `.tgz` 文件。
|
||||
|
||||
#### 14. 验证 Chart
|
||||
```sh
|
||||
helm lint <chart_path>
|
||||
```
|
||||
- 检查 Chart 是否符合规范,有无错误。
|
||||
|
||||
### 配置管理
|
||||
|
||||
#### 15. 查看默认值
|
||||
```sh
|
||||
helm show values <chart_name>
|
||||
```
|
||||
- 查看 Chart 的默认值。
|
||||
|
||||
#### 16. 使用自定义值安装/升级
|
||||
```sh
|
||||
helm install <release_name> <chart_name> -f <custom_values_file>
|
||||
```
|
||||
```sh
|
||||
helm upgrade <release_name> <chart_name> -f <custom_values_file>
|
||||
```
|
||||
- 使用指定的自定义值文件进行安装或升级。
|
||||
|
||||
### Helm 插件
|
||||
|
||||
#### 17. 列出插件
|
||||
```sh
|
||||
helm plugin list
|
||||
```
|
||||
- 列出所有已安装的 Helm 插件。
|
||||
|
||||
#### 18. 安装插件
|
||||
```sh
|
||||
helm plugin install <plugin_url>
|
||||
```
|
||||
- 从指定 URL 安装插件。
|
||||
|
||||
#### 19. 移除插件
|
||||
```sh
|
||||
helm plugin uninstall <plugin_name>
|
||||
```
|
||||
- 移除指定的插件。
|
||||
|
||||
### 其他
|
||||
|
||||
#### 20. 获取 Helm 版本
|
||||
```sh
|
||||
helm version
|
||||
```
|
||||
- 查看当前 Helm 客户端和服务端的版本信息。
|
||||
|
||||
### 总结
|
||||
这些是 Helm 的一些常用命令,掌握这些命令可以帮助你在 Kubernetes 集群中更高效地管理应用程序。Helm 提供了强大且灵活的功能,适用于各种场景的应用管理。
|
||||
74
daliy_note/9月归档/9.20/openelb.md
Normal file
74
daliy_note/9月归档/9.20/openelb.md
Normal file
@ -0,0 +1,74 @@
|
||||
OpenELB(开放式负载均衡器)是一个开源项目,旨在为 Kubernetes 集群提供高性能的负载均衡和服务发现功能。OpenELB 支持多种负载均衡模式,包括 Layer 2 模式、BGP 模式和 VIP 模式。让我们详细了解这些模式的区别与工作原理。
|
||||
|
||||
### 1. Layer 2 模式
|
||||
|
||||
#### 工作原理:
|
||||
- **Layer 2 模式**利用数据链路层(也称为 MAC 层)的广播功能,将请求分发到不同的后端节点。
|
||||
- 在这种模式下,OpenELB 会将负载均衡器的虚拟 IP(VIP)配置为一个浮动 IP 地址,并将其广播到同一子网内的所有节点。
|
||||
- 这些节点会响应这个浮动 IP 地址的 ARP 请求,最终实现请求的分发。
|
||||
|
||||
#### 优点:
|
||||
- 配置简单,不需要额外的路由协议支持。
|
||||
- 适用于小型集群和简单网络拓扑。
|
||||
|
||||
#### 缺点:
|
||||
- 不适用于跨子网或跨数据中心的场景。
|
||||
- 可能存在广播风暴的风险,对网络性能有一定影响。
|
||||
|
||||
### 2. BGP 模式
|
||||
|
||||
#### 工作原理:
|
||||
- **BGP(Border Gateway Protocol)模式**利用 BGP 路由协议实现跨子网、跨数据中心的负载均衡。
|
||||
- OpenELB 充当一个 BGP 路由器,与集群内的其他 BGP 路由器建立 BGP 会话。
|
||||
- 通过 BGP 广播 VIP 地址,并将其路由到正确的后端节点。
|
||||
- 这种模式可以实现更复杂的路由策略和更高的网络可扩展性。
|
||||
|
||||
#### 优点:
|
||||
- 适用于跨子网、跨数据中心的场景。
|
||||
- 支持复杂的路由策略和高可扩展性。
|
||||
- 更加稳定,适合大型集群和复杂网络拓扑。
|
||||
|
||||
#### 缺点:
|
||||
- 配置复杂,需要一定的网络知识和 BGP 配置经验。
|
||||
- 需要支持 BGP 路由协议的网络设备或软件。
|
||||
|
||||
### 3. VIP 模式
|
||||
|
||||
#### 工作原理:
|
||||
- **VIP(Virtual IP)模式**通过将一个虚拟 IP 地址(VIP)分配给服务,实现负载均衡。
|
||||
- OpenELB 将 VIP 地址绑定到一个特定的节点上,作为服务的入口。
|
||||
- 通过 IPVS(IP Virtual Server)或其他负载均衡技术,将请求分发到后端的实际服务实例。
|
||||
|
||||
#### 优点:
|
||||
- 配置相对简单,适用于大多数场景。
|
||||
- 支持高可用性,通过监控和切换 VIP 地址,实现故障转移。
|
||||
|
||||
#### 缺点:
|
||||
- 如果 VIP 地址绑定的节点发生故障,可能需要手动或通过高可用机制进行切换,存在一定的延迟。
|
||||
|
||||
- 在某些复杂网络环境下,可能需要额外的配置来确保 VIP 地址的可达性。
|
||||
|
||||
### 总结
|
||||
|
||||
#### 1. Layer 2 模式
|
||||
|
||||
- **适用场景**:适用于小型集群和简单网络拓扑的场景。通常用于单个子网内部的服务负载均衡。
|
||||
- **选择建议**:如果你的集群规模较小,且网络环境简单,Layer 2 模式是一个快速、简单的选择。
|
||||
|
||||
#### 2. BGP 模式
|
||||
|
||||
- **适用场景**:适用于跨子网、跨数据中心的场景,尤其是在需要复杂路由策略和高可扩展性的环境中。
|
||||
- **选择建议**:如果你的集群规模较大,网络拓扑复杂,或者需要跨数据中心进行负载均衡,BGP 模式是一个更合适的选择。
|
||||
|
||||
#### 3. VIP 模式
|
||||
|
||||
- **适用场景**:适用于大多数场景,包括需要高可用性和故障转移的环境。适合中型到大型集群,网络环境相对复杂,但不需要跨数据中心。
|
||||
- **选择建议**:如果你需要一个相对简单但功能强大的负载均衡解决方案,能够提供高可用性和故障转移能力,VIP 模式是一个不错的选择。
|
||||
|
||||
### 选择建议
|
||||
|
||||
- **简单和快速部署**:选择 Layer 2 模式。
|
||||
- **复杂网络环境和高可扩展性**:选择 BGP 模式。
|
||||
- **需要高可用性和故障转移**:选择 VIP 模式。
|
||||
|
||||
选择哪种模式应根据你的具体需求和网络环境来决定。如果你对网络配置和路由协议有一定的经验,可以考虑使用更复杂的 BGP 模式。如果你需要一个快速部署且相对简单的解决方案,可以选择 Layer 2 模式或 VIP 模式。无论选择哪种模式,都需要确保对相关配置和工作原理有充分的理解,以实现最佳的负载均衡效果。
|
||||
24
daliy_note/9月归档/9.20/semver.md
Normal file
24
daliy_note/9月归档/9.20/semver.md
Normal file
@ -0,0 +1,24 @@
|
||||
SemVer 2,即 “Semantic Versioning 2.0.0”,是一种版本控制策略,用于管理应用程序、库和API的版本号。它是一种约定俗成的规范,通过版本号来清晰地表达软件变更的意义。
|
||||
|
||||
根据SemVer 2.0.0,版本号被定义为 `MAJOR.MINOR.PATCH`,具体含义如下:
|
||||
|
||||
1. **MAJOR(主版本号)**:当你做了不兼容的 API 修改;
|
||||
2. **MINOR(次版本号)**:当你做了向下兼容的功能性新增;
|
||||
3. **PATCH(修订号)**:当你做了向下兼容的问题修正。
|
||||
|
||||
另外,还包括一些额外的标签用于标示预发布版本和构建元数据,这部分通常以 `-` 或 `+` 连接到版本号的后面:
|
||||
|
||||
- **预发布版本标签**(如 `1.0.0-alpha`、`1.0.0-beta`):用于在开发过程中标示不稳定的版本,这些版本不一定是完全的。
|
||||
- **构建元数据**(如 `1.0.0+20130313144700`):用于标示构建的特定信息,通常用于区分不同的构建,而不影响版本排序。
|
||||
|
||||
一个完整的版本号实例可能是: `1.4.7-alpha.1+exp.sha.5114f85`。
|
||||
|
||||
### 具体规则和示例:
|
||||
|
||||
- **初始开发阶段**:0.Y.Z 版本号,当软件还在开发初期阶段,不稳定,不应保证API稳定性。
|
||||
- **发布1.0.0版本后**:
|
||||
- **MAJOR版本变更**:`1.0.0` -> `2.0.0`,表示不兼容API的重大修改。
|
||||
- **MINOR版本变更**:`1.1.0` -> `1.2.0`,表示新增了功能,但是保持向后兼容。
|
||||
- **PATCH版本变更**:`1.1.1` -> `1.1.2`,表示修复了错误,保持向后兼容。
|
||||
|
||||
通过采用 SemVer 规范,开发者和用户可以更清楚地理解每个发布版本的变更范围和潜在影响,有助于版本管理和依赖管理。
|
||||
18
daliy_note/9月归档/9.23/nc.md
Normal file
18
daliy_note/9月归档/9.23/nc.md
Normal file
@ -0,0 +1,18 @@
|
||||
`nc`(或 `netcat`)是一个网络工具,用于读写网络连接。它可以用于执行多种网络操作,如端口扫描、数据传输等。下面是你提供的命令的具体解析:
|
||||
|
||||
```bash
|
||||
nc -zv -w 3 100.64.1.11 8009
|
||||
```
|
||||
|
||||
各个选项的含义如下:
|
||||
|
||||
1. `nc`:调用 `netcat` 程序。
|
||||
2. `-z`:零输入/扫描模式。这个选项告诉 `netcat` 不要发送任何数据,只是去扫描指定的端口,以确定它是否打开。
|
||||
3. `-v`:详细模式。启用详细输出,会在执行过程中显示更多信息,例如连接的尝试和结果。
|
||||
4. `-w 3`:设置超时时间为3秒。这个选项指定了在尝试连接时的超时时间,即如果在3秒内没有成功连接,就放弃。
|
||||
5. `100.64.1.11`:目标IP地址。
|
||||
6. `8009`:目标端口。
|
||||
|
||||
综合起来,这个命令的功能是尝试连接到IP地址 `100.64.1.11` 的端口 `8009`,并在3秒内确定该端口是否打开(即是否有服务在监听这个端口)。它不会发送任何数据,只是用来检测端口的状态,并且会输出详细的连接结果。
|
||||
|
||||
这个命令常用于网络诊断和故障排除,帮助管理员确定某个服务是否在目标IP和端口上运行。
|
||||
28
daliy_note/9月归档/9.23/prometheus.md
Normal file
28
daliy_note/9月归档/9.23/prometheus.md
Normal file
@ -0,0 +1,28 @@
|
||||
在Prometheus中,`scalar` 函数用于将一个时间序列的值转换为一个标量值。这意味着它可以将一个单值时间序列(也就是只有一个数据点的时间序列)转换为一个静态值,可以在计算中使用。
|
||||
|
||||
**函数语法**:
|
||||
```promql
|
||||
scalar(expr)
|
||||
```
|
||||
|
||||
**参数**:
|
||||
- `expr`: 任何有效的PromQL表达式,该表达式应返回一个或多个时间序列。通常情况下,表达式返回的时间序列应该只有一个样本点(单值)。
|
||||
|
||||
**返回值**:
|
||||
- 返回一个单一的标量值,这个值来自于给定表达式计算后获得的时间序列的最后一个样本。如果表达式返回多个样本或没有样本,则`scalar`函数会产生错误。
|
||||
|
||||
### 使用场景
|
||||
- 当你需要在计算中使用一个查询的最后一个值,但你不关心时间序列的时间戳,只希望获取一个数值时,`scalar` 函数非常有用。
|
||||
- 例如,如果你想要通过计算某个时间序列的最后一个值来与另一个时间序列进行比较或做进一步的数学运算。
|
||||
|
||||
### 示例
|
||||
假设你有一个名为 `http_requests_total` 的计数器时间序列,你希望获取最后一次请求的总数并用这个值去做其他的计算:
|
||||
|
||||
```promql
|
||||
scalar(http_requests_total{job="my_service"})
|
||||
```
|
||||
|
||||
这会返回 `http_requests_total` 中最后一个样本的数值,而不关心它与时间的关系。
|
||||
|
||||
### 注意事项
|
||||
- 如果查询返回了多个时间序列数据,那么使用 `scalar` 函数将导致错误,因此确保你在使用该函数时,表达式的结果是一个单一的时间序列。
|
||||
24
daliy_note/9月归档/9.24/KubeOnKube.md
Normal file
24
daliy_note/9月归档/9.24/KubeOnKube.md
Normal file
@ -0,0 +1,24 @@
|
||||
"Kubernetes on Kubernetes" (通常缩写为 "Kube-on-Kube") 是指使用一个 Kubernetes 集群来管理和运行另一个 Kubernetes 集群的架构或方法。这种方法通常用于提供 Kubernetes 集群的自动化管理、集群生命周期管理、集群监控等功能。
|
||||
|
||||
以下是对 "Kubernetes on Kubernetes" 的进一步解释:
|
||||
|
||||
1. **管理集群和工作负载集群**:
|
||||
- **管理集群(Management Cluster)**:这是第一个 Kubernetes 集群,用于管理其他 Kubernetes 集群的生命周期。管理集群中可能运行控制平面组件、集群管理工具和其他辅助服务。
|
||||
- **工作负载集群(Workload Cluster)**:这些是由管理集群创建和管理的 Kubernetes 集群,实际用于运行用户的应用和服务。
|
||||
|
||||
2. **使用 Helm Charts 或 Operators**:在管理集群中可以使用 Helm Charts 或 Kubernetes Operators 来部署和管理工作负载集群。这些工具可以帮助自动化集群的创建、配置、更新和监控。
|
||||
|
||||
3. **KubeVirt**:KubeVirt 是一个开源项目,允许在 Kubernetes 中管理和运行虚拟机。使用 KubeVirt,可以在 Kubernetes 集群上运行 VM,这些虚拟机可以用于运行另一个 Kubernetes 集群的控制平面组件,从而实现 Kubernetes on Kubernetes 的架构。
|
||||
|
||||
4. **Cluster API**:Cluster API 是一个 Kubernetes 项目,提供了一组标准化的 API 和控制器,用于在 Kubernetes 集群上声明性地创建、配置和管理另一个 Kubernetes 集群。Cluster API 使得集群的配置、升级和扩展变得更加自动化和一致。
|
||||
|
||||
5. **优势**:
|
||||
- **一致性和标准化**:使用 Kubernetes 的原生 API 和工具管理集群,提高了集群管理的一致性和标准化。
|
||||
- **自动化**:通过自动化工具和控制器,可以简化集群的生命周期管理,减少手动操作的复杂性。
|
||||
- **弹性和扩展性**:可以根据需求动态地创建和删除工作负载集群,灵活应对不同的工作负载需求。
|
||||
|
||||
6. **挑战**:
|
||||
- **复杂性**:管理多层次的 Kubernetes 集群会增加系统的复杂性,需要对 Kubernetes 有深入的理解。
|
||||
- **资源开销**:运行多个 Kubernetes 集群会占用更多的计算、存储和网络资源,需要合理规划和调度。
|
||||
|
||||
总的来说,Kubernetes on Kubernetes 是一种强大的架构方法,可以帮助实现高度自动化和可扩展的集群管理,但也需要解决复杂性和资源管理的问题。
|
||||
61
daliy_note/9月归档/9.25/Cassandra.md
Normal file
61
daliy_note/9月归档/9.25/Cassandra.md
Normal file
@ -0,0 +1,61 @@
|
||||
> https://wallenotes.github.io/categories/%E6%95%B0%E6%8D%AE%E5%BA%93/Cassandra/
|
||||
|
||||
Apache Cassandra 是一个高可用性、高扩展性、分布式的 NoSQL 数据库管理系统。它最初由 Facebook 开发,并在 2008 年开源,后来成为 Apache 软件基金会的顶级项目。Cassandra 采用了去中心化的架构设计,能够在大规模分布式系统中实现高性能和高可用性。
|
||||
|
||||
### Cassandra 的主要特点
|
||||
|
||||
1. **去中心化架构**:Cassandra 采用去中心化的对等节点架构(Peer-to-Peer),没有单点故障,每个节点在集群中地位平等。数据自动在集群中均匀分布,保证了高可用性和容错性。
|
||||
|
||||
2. **线性扩展性**:Cassandra 能够通过增加节点来线性扩展处理能力和存储容量。无论是写操作还是读操作,性能都可以通过增加节点来提升。
|
||||
|
||||
3. **高可用性和容错性**:数据在多个节点之间进行复制,确保即使某些节点故障,数据依然可用。Cassandra 支持多数据中心的部署,能够在地理上分布的多个数据中心之间进行数据复制。
|
||||
|
||||
4. **灵活的数据模型**:Cassandra 采用了宽列存储模型(Wide Column Store),允许用户定义灵活的表结构。每个表可以有多个列族,每个列族可以包含任意数量的列。
|
||||
|
||||
5. Cassandra 提供了强一致性和最终一致性之间的灵活选择。用户可以根据需求调整读写操作的一致性级别(例如 `ONE`、`QUORUM`、`ALL`),以在性能和数据一致性之间进行权衡。
|
||||
|
||||
6. **高吞吐量和低延迟**:Cassandra 设计用于处理大规模的写入和读取操作,能够在高并发环境下保持低延迟和高吞吐量。
|
||||
7. **支持 CQL(Cassandra Query Language)**:CQL 类似于 SQL,但专为 Cassandra 的数据模型设计,提供了简单易用的查询接口。
|
||||
|
||||
### Cassandra 的核心组件
|
||||
|
||||
1. **节点(Node)**:Cassandra 集群中的基本单位,每个节点存储部分数据。所有节点地位平等,可以独立处理读写请求。
|
||||
|
||||
2. **数据中心(Data Center)**:多个节点可以组成一个数据中心,Cassandra 支持跨数据中心的部署和数据复制,以提高容灾能力和数据可用性。
|
||||
|
||||
3. **键空间(Keyspace)**:键空间是一个逻辑容器,用于组织表,类似于关系数据库中的数据库。它定义了数据复制策略等元数据信息。
|
||||
|
||||
4. **表(Table)**:表是数据存储的基本单位,由行和列组成。每行有一个唯一的主键,通过主键进行数据分区和分布。
|
||||
|
||||
5. **列族(Column Family)**:列族是表的一个逻辑分组,用于组织列。每个列族可以包含任意数量的列。
|
||||
|
||||
### Cassandra 的常见使用场景
|
||||
|
||||
1. **实时大数据分析**:由于其高吞吐量和低延迟,Cassandra 适合用于实时大数据分析和处理。例如,日志记录、监控系统、点击流分析等。
|
||||
|
||||
2. **社交网络**:Cassandra 能够高效处理社交网络中的大量用户数据和交互数据,支持高并发的读写操作。例如,Facebook 在其收件箱搜索系统中使用了 Cassandra。
|
||||
|
||||
3. **物联网(IoT)**:Cassandra 适合处理物联网设备产生的大量数据,能够在分布式环境中实现数据收集和处理。
|
||||
|
||||
4. **电子商务**:Cassandra 能够高效处理电子商务平台中的商品目录、用户数据、订单记录等,支持高并发的交易处理。
|
||||
|
||||
5. **金融服务**:金融机构可以利用 Cassandra 存储和分析金融交易数据、用户行为数据等,支持实时风控和欺诈检测。
|
||||
|
||||
### Cassandra 的优缺点
|
||||
|
||||
#### 优点
|
||||
|
||||
1. **高可用性和无单点故障**:去中心化的架构设计确保了高可用性和无单点故障。
|
||||
2. **线性扩展性**:能够通过增加节点来线性提升性能和存储容量。
|
||||
3. **灵活的数据模型**:宽列存储模型允许用户定义灵活的数据结构。
|
||||
4. **高吞吐量和低延迟**:设计用于处理大规模的写入和读取操作,性能表现优异。
|
||||
|
||||
#### 缺点
|
||||
|
||||
1. **学习曲线**:Cassandra 的数据模型和查询语言与传统关系数据库不同,可能需要一定的学习成本。
|
||||
2. **事务支持有限**:Cassandra 主要提供最终一致性,事务支持不如传统关系数据库强大。
|
||||
3. **复杂的运维管理**:大规模的分布式系统需要专业的运维管理和监控,运维成本较高。
|
||||
|
||||
### 总结
|
||||
|
||||
Apache Cassandra 是一个强大的分布式 NoSQL 数据库,适用于需要高可用性、高扩展性和高性能的应用场景。尽管它的学习和运维成本较高,但其在处理大规模数据和高并发操作中的优势,使其成为诸多企业和应用的首选。
|
||||
115
daliy_note/9月归档/9.25/时序数据存储方案.md
Normal file
115
daliy_note/9月归档/9.25/时序数据存储方案.md
Normal file
@ -0,0 +1,115 @@
|
||||
这些系统都是用于时间序列数据存储和监控的解决方案,但它们在架构、功能、性能和使用场景上各有不同。以下是 Prometheus、M3DB、VictoriaMetrics、Thanos 和 Cortex 的对比。
|
||||
|
||||
### Prometheus
|
||||
|
||||
**概述**:
|
||||
- Prometheus 是一个开源的系统监控和报警工具包,最初由 SoundCloud 开发,并于 2016 年加入 CNCF。
|
||||
- 主要用于监控和告警,设计目标是可靠性和快速查询。
|
||||
|
||||
**特点**:
|
||||
- **数据模型**:时间序列数据库,数据按时间序列存储。
|
||||
- **查询语言**:PromQL,功能强大,适合复杂查询。
|
||||
- **架构**:单节点设计,但可以通过远程存储集成扩展。
|
||||
- **数据持久化**:本地存储,支持远程写入和读取。
|
||||
- **高可用性**:单节点设计有单点故障问题,但可以通过 Thanos 或 Cortex 实现高可用性。
|
||||
|
||||
**使用场景**:
|
||||
- 适合中小规模的监控系统。
|
||||
- 需要复杂查询和告警功能的场景。
|
||||
|
||||
### M3DB
|
||||
|
||||
**概述**:
|
||||
- M3DB 是 Uber 开发的分布式时间序列数据库,设计用于大规模监控系统。
|
||||
|
||||
**特点**:
|
||||
- **数据模型**:时间序列数据库,支持高吞吐量和低延迟。
|
||||
- **查询语言**:支持 PromQL 以及其他查询语言。
|
||||
- **架构**:分布式架构,支持水平扩展。
|
||||
- **数据持久化**:支持多种存储后端,如本地磁盘、S3 等。
|
||||
- **高可用性**:内置高可用性和数据复制
|
||||
- **数据压缩**:高效的数据压缩算法,适合大规模数据存储。
|
||||
|
||||
- **集成**:与 Prometheus 兼容,可以作为 Prometheus 的远程存储后端。
|
||||
- **运维**:需要较高的运维和管理成本,适合有专门运维团队的组织。
|
||||
|
||||
**使用场景**:
|
||||
- 超大规模监控系统,需要高吞吐量和低延迟的场景。
|
||||
- 需要持久化存储和高可用性的场景,如金融服务、物联网等。
|
||||
|
||||
### VictoriaMetrics
|
||||
|
||||
**概述**:
|
||||
- VictoriaMetrics 是一个高性能、开源的时间序列数据库,设计用于高效存储和检索大规模时间序列数据。
|
||||
|
||||
**特点**:
|
||||
- **数据模型**:时间序列数据库,支持高并发写入和查询。
|
||||
- **查询语言**:支持 PromQL。
|
||||
- **架构**:单节点和集群模式,集群模式支持水平扩展。
|
||||
- **数据持久化**:本地存储,支持远程存储(如 S3)。
|
||||
- **高可用性**:集群模式提供高可用性和数据复制。
|
||||
|
||||
**性能**:
|
||||
- **高性能**:高效的存储和压缩算法,适合大规模数据的存储和查询。
|
||||
- **低资源消耗**:相比其他解决方案,资源消耗较低。
|
||||
|
||||
**使用场景**:
|
||||
- 高性能、大规模数据存储和查询的场景。
|
||||
- 资源受限的环境,如边缘计算和嵌入式系统。
|
||||
|
||||
### Thanos
|
||||
|
||||
**概述**:
|
||||
- Thanos 是一个开源项目,扩展了 Prometheus 的功能,提供长时间存储、全局查询和高可用性。
|
||||
|
||||
**特点**:
|
||||
- **数据模型**:基于 Prometheus 的时间序列数据模型。
|
||||
- **查询语言**:支持 PromQL。
|
||||
- **架构**:模块化架构,包括 Sidecar、Store Gateway、Query、Compactor 等组件。
|
||||
- **数据持久化**:与对象存储(如 S3、GCS)集成,实现长时间存储。
|
||||
- **高可用性**:支持 Prometheus 的高可用性,通过多 Prometheus 实例和全局查询实现。
|
||||
|
||||
**功能**:
|
||||
- **长时间存储**:解决 Prometheus 本地存储的局限性。
|
||||
- **全局查询**:跨多个 Prometheus 实例进行全局查询。
|
||||
- **高可用性**:实现 Prometheus 的高可用性和数据冗余。
|
||||
|
||||
**使用场景**:
|
||||
- 需要长时间数据存储和全局查询的场景。
|
||||
- 需要高可用性监控的场景,如大规模分布式系统。
|
||||
|
||||
### Cortex
|
||||
|
||||
**概述**:
|
||||
- Cortex 是一个开源项目,用于将 Prometheus 扩展到大规模、高可用性的环境,提供多租户支持。
|
||||
|
||||
**特点**:
|
||||
- **数据模型**:基于 Prometheus 的时间序列数据模型。
|
||||
- **查询语言**:支持 PromQL。
|
||||
- **架构**:模块化架构,包括 Distributor、Ingester、Querier、Store Gateway 等组件。
|
||||
- **数据持久化**:支持多种存储后端,如 DynamoDB、Cassandra、S3 等。
|
||||
- **高可用性**:内置高可用性和数据分片、复制功能。
|
||||
|
||||
**功能**:
|
||||
- **多租户支持**:适合多租户环境,如 SaaS 平台。
|
||||
- **水平扩展**:支持水平扩展,适合大规模监控系统。
|
||||
- **高可用性**:通过数据分片和复制实现高可用性。
|
||||
|
||||
**使用场景**:
|
||||
- 多租户、大规模、高可用性监控的场景。
|
||||
- 需要 Prometheus 兼容性和扩展性的场景。
|
||||
|
||||
### 总结对比
|
||||
|
||||
| 特性 | Prometheus | M3DB | VictoriaMetrics | Thanos | Cortex |
|
||||
| ---------- | ------------ | ---------------------- | ---------------------- | -------------------- | ------------------ |
|
||||
| 数据模型 | 时间序列 | 时间序列 | 时间序列 | 时间序列 | 时间序列 |
|
||||
| 查询语言 | PromQL | PromQL, 其他 | PromQL | PromQL | PromQL |
|
||||
| 架构 | 单节点 | 分布式 | 单节点、集群 | 模块化扩展 | 模块化扩展 |
|
||||
| 数据持久化 | 本地存储 | 多种存储后端 | 本地存储、远程存储 | 对象存储(如 S3) | 多种存储后端 |
|
||||
| 高可用性 | 单节点故障 | 内置高可用性和数据复制 | 集群模式高可用性 | 支持高可用性 | 内置高可用性 |
|
||||
| 主要优点 | 简单易用 | 高吞吐量、低延迟 | 高性能、低资源消耗 | 长时间存储、全局查询 | 多租户、高可用性 |
|
||||
| 主要缺点 | 单点故障 | 运维成本较高 | 单节点模式有局限 | 需要额外配置和维护 | 复杂性较高 |
|
||||
| 适用场景 | 中小规模监控 | 超大规模监控 | 高性能、大规模存储查询 | 长时间存储、高可用性 | 多租户、大规模监控 |
|
||||
|
||||
选择合适的时间序列数据库和监控解决方案需要根据具体的需求、规模和资源情况来决定。Prometheus 适合中小规模的监控,M3DB 和 Cortex 适合大规模高性能的监控,而 Thanos 和 VictoriaMetrics 则提供了长时间存储和高可用性的解决方案。
|
||||
141
daliy_note/9月归档/9.26/nodejs_promise.md
Normal file
141
daliy_note/9月归档/9.26/nodejs_promise.md
Normal file
@ -0,0 +1,141 @@
|
||||
在 Node.js 中,`Promise` 是一种用于处理异步操作的方式。它可以帮助你简化嵌套的回调函数(即“回调地狱”),并提供更加直观的代码结构。在本回答中,我将介绍如何在 Node.js 中使用 `Promise`,包括创建和使用 `Promise`,以及如何将回调函数转换为 `Promise`。
|
||||
|
||||
### 基本概念
|
||||
|
||||
一个 `Promise` 有三种状态:
|
||||
|
||||
1. **Pending**:初始状态,既没有被解决(fulfilled)也没有被拒绝(rejected)。
|
||||
2. **Fulfilled**:操作成功完成。
|
||||
3. **Rejected**:操作失败。
|
||||
|
||||
### 创建和使用 `Promise`
|
||||
|
||||
#### 创建 `Promise`
|
||||
|
||||
你可以通过 `new Promise` 来创建一个 `Promise` 对象。它接收一个执行函数,该函数有两个参数:`resolve` 和 `reject`,分别用于表示操作成功和失败。
|
||||
|
||||
```javascript
|
||||
const myPromise = new Promise((resolve, reject) => {
|
||||
// 异步操作
|
||||
setTimeout(() => {
|
||||
const success = true; // 你可以根据实际情况设置成功或失败
|
||||
|
||||
if (success) {
|
||||
resolve('Operation completed successfully!');
|
||||
} else {
|
||||
reject('Operation failed!');
|
||||
}
|
||||
}, 1000);
|
||||
});
|
||||
```
|
||||
|
||||
#### 使用 `Promise`
|
||||
|
||||
你可以使用 `then` 和 `catch` 方法来处理 `Promise` 的结果。
|
||||
|
||||
```javascript
|
||||
myPromise
|
||||
.then(result => {
|
||||
console.log(result); // 输出: Operation completed successfully!
|
||||
})
|
||||
.catch(error => {
|
||||
console.error(error); // 输出: Operation failed!
|
||||
});
|
||||
```
|
||||
|
||||
### 将回调函数转换为 `Promise`
|
||||
|
||||
许多 Node.js 核心模块(如 `fs`)使用回调函数。你可以使用 `util.promisify` 将这些回调函数转换为返回 `Promise` 的函数。
|
||||
|
||||
#### 使用 `util.promisify`
|
||||
|
||||
```javascript
|
||||
const fs = require('fs');
|
||||
const util = require('util');
|
||||
|
||||
const readFile = util.promisify(fs.readFile);
|
||||
|
||||
readFile('example.txt', 'utf8')
|
||||
.then(data => {
|
||||
console.log(data);
|
||||
})
|
||||
.catch(error => {
|
||||
console.error(error);
|
||||
});
|
||||
```
|
||||
|
||||
#### 手动转换回调函数
|
||||
|
||||
你也可以手动将回调函数转换为 `Promise`。
|
||||
|
||||
```javascript
|
||||
const fs = require('fs');
|
||||
|
||||
function readFilePromise(filePath, encoding) {
|
||||
return new Promise((resolve, reject) => {
|
||||
fs.readFile(filePath, encoding, (err, data) => {
|
||||
if (err) {
|
||||
reject(err);
|
||||
} else {
|
||||
resolve(data);
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
readFilePromise('example.txt', 'utf8')
|
||||
.then(data => {
|
||||
console.log(data);
|
||||
})
|
||||
.catch(error => {
|
||||
console.error(error);
|
||||
});
|
||||
```
|
||||
|
||||
### 使用 `async`/`await`
|
||||
|
||||
`async` 和 `await` 是基于 `Promise` 的语法糖,可以让你的异步代码看起来像同步代码。它们使得代码更具可读性和可维护性。
|
||||
|
||||
```javascript
|
||||
const fs = require('fs').promises; // 使用 fs.promises 提供的基于 Promise 的方法
|
||||
|
||||
async function readFileAsync(filePath) {
|
||||
try {
|
||||
const data = await fs.readFile(filePath, 'utf8');
|
||||
console.log(data);
|
||||
} catch (error) {
|
||||
console.error(error);
|
||||
}
|
||||
}
|
||||
|
||||
readFileAsync('example.txt');
|
||||
```
|
||||
|
||||
### 链式调用和错误处理
|
||||
|
||||
你可以通过链式调用来处理多个异步操作,并在最后使用 `catch` 处理所有可能的错误。
|
||||
|
||||
```javascript
|
||||
const fs = require('fs').promises;
|
||||
|
||||
fs.readFile('example.txt', 'utf8')
|
||||
.then(data => {
|
||||
console.log('File content:', data);
|
||||
return fs.writeFile('example_copy.txt', data);
|
||||
})
|
||||
.then(() => {
|
||||
console.log('File copied successfully');
|
||||
})
|
||||
.catch(error => {
|
||||
console.error('Error:', error);
|
||||
});
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
- `Promise` 为异步操作提供了一种更加直观的处理方式。
|
||||
- `then` 和 `catch` 方法用于处理 `Promise` 的结果和错误。
|
||||
- `util.promisify` 可以将回调函数转换为返回 `Promise` 的函数。
|
||||
- `async`/`await` 是基于 `Promise` 的语法糖,使得异步代码更具可读性。
|
||||
|
||||
通过这些方法,你可以在 Node.js 中更高效地处理异步操作。
|
||||
146
daliy_note/9月归档/9.26/prometheus无数据报警.md
Normal file
146
daliy_note/9月归档/9.26/prometheus无数据报警.md
Normal file
@ -0,0 +1,146 @@
|
||||
无数据报警(也称为“空数据报警”或“数据缺失报警”),指的是当预期的数据没有按时到达或数据源停止输出时触发报警。这在监控系统中非常重要,因为它可以帮助你及时发现数据采集系统或服务出现的问题。以下是一个实现无数据报警的方案,主要基于 Prometheus 和 Alertmanager。
|
||||
|
||||
### 方案步骤
|
||||
|
||||
#### 1. 配置 Prometheus 规则
|
||||
在 Prometheus 中配置报警规则,检测某个时间窗口内数据是否缺失。假设你想监控一个指标 `http_requests_total`,并在 5 分钟内没有任何数据时触发报警。
|
||||
|
||||
```yaml
|
||||
groups:
|
||||
- name: NoDataAlertGroup
|
||||
rules:
|
||||
- alert: NoDataForHttpRequests
|
||||
expr: absent(http_requests_total) == 1
|
||||
for: 5m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
summary: "No data for http_requests_total"
|
||||
description: "No data has been received for the metric http_requests_total in the last 5 minutes."
|
||||
```
|
||||
|
||||
这个规则使用 `absent()` 函数来检测 `http_requests_total` 这个指标是否不存在。如果在 5 分钟内没有数据,这个报警会被触发。
|
||||
|
||||
#### 2. 部署 Alertmanager
|
||||
确保你的 Alertmanager 已经部署并与 Prometheus 集成。你可以在 Prometheus 的配置文件 `prometheus.yml` 中添加 Alertmanager 的配置。
|
||||
|
||||
```yaml
|
||||
alerting:
|
||||
alertmanagers:
|
||||
- static_configs:
|
||||
- targets:
|
||||
- 'alertmanager-service:9093'
|
||||
```
|
||||
|
||||
#### 3. 配置 Alertmanager 接收器
|
||||
|
||||
在 Alertmanager 的配置文件 `alertmanager.yml` 中,配置接收器来处理报警通知。以下是一个示例,设置了 Slack 接收器:
|
||||
|
||||
```yaml
|
||||
route:
|
||||
group_by: ['alertname']
|
||||
group_wait: 30s
|
||||
group_interval: 5m
|
||||
repeat_interval: 3h
|
||||
receiver: 'slack-notifications'
|
||||
|
||||
receivers:
|
||||
- name: 'slack-notifications'
|
||||
slack_configs:
|
||||
- api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
|
||||
channel: '#alerts'
|
||||
text: "{{ .CommonAnnotations.description }}"
|
||||
```
|
||||
|
||||
在这个配置中,`route` 部分定义了报警的路由规则,`receivers` 部分定义了接收器的配置。你可以根据需要替换为其他接收器,比如电子邮件、PagerDuty 甚至自定义的 Webhook。
|
||||
|
||||
#### 4. 测试报警配置
|
||||
|
||||
为了确保无数据报警配置正确,可以手动停止某些数据源或服务,然后观察是否能够及时收到报警通知。
|
||||
|
||||
1. **停止数据源**:例如,停止发送 `http_requests_total` 数据的服务。
|
||||
2. **等待报警**:根据配置的 `for` 时间等待一段时间(如 5 分钟)。
|
||||
3. **检查报警**:在 Slack 或其他接收器中查看是否收到了报警通知。
|
||||
|
||||
#### 5. 可视化和监控
|
||||
|
||||
使用 Grafana 来可视化和监控这些报警数据,可以帮助你更直观地了解系统的健康状况。
|
||||
|
||||
1. **添加 Prometheus 数据源**:在 Grafana 中添加 Prometheus 作为数据源。
|
||||
2. **创建仪表板**:创建一个仪表板来展示关键指标和报警状态。例如,你可以创建一个面板来展示 `http_requests_total` 指标的变化情况,以及当前的报警状态。
|
||||
|
||||
#### 6. 优化和调整
|
||||
|
||||
根据实际情况,不断优化和调整报警规则。例如,你可能需要:
|
||||
|
||||
- **调整报警阈值**:根据业务需求调整报警触发的时间窗口和阈值。
|
||||
- **细化报警规则**:为不同的指标配置不同的报警规则,以便更精细地监控系统。
|
||||
|
||||
### 总结
|
||||
|
||||
通过上述步骤,你可以在云原生环境中实现无数据报警方案。核心思路是使用 Prometheus 配置 `absent()` 函数检测数据缺失,并通过 Alertmanager 发送报警通知。结合 Grafana,可以实现可视化监控和报警管理,从而确保系统的可靠性和稳定性。
|
||||
|
||||
### unless 关键字
|
||||
|
||||
在 Prometheus 中,`unless` 是用于执行集合差集运算的关键字。它用于过滤掉在一个集合中出现但在另一个集合中也出现的数据点。简单来说,`A unless B` 表示从集合 A 中剔除所有在集合 B 中也出现的数据点。
|
||||
|
||||
#### 基本语法
|
||||
|
||||
```promql
|
||||
vector1 unless vector2
|
||||
```
|
||||
|
||||
- **vector1**:第一个向量表达式。
|
||||
- **vector2**:第二个向量表达式。
|
||||
- **结果**:返回在 `vector1` 中但不在 `vector2` 中的所有数据点。
|
||||
|
||||
#### 示例
|
||||
|
||||
假设你有两个指标:`up`(表示服务是否正常运行)和 `http_requests_total`(表示 HTTP 请求总数)。你希望找出那些有 HTTP 请求的服务,但这些服务没有运行:
|
||||
|
||||
```promql
|
||||
http_requests_total unless up
|
||||
```
|
||||
|
||||
这个查询将返回那些有 HTTP 请求但服务不在运行状态的实例。
|
||||
|
||||
### 实现无数据报警的另一种方式
|
||||
|
||||
你可以结合 `unless` 关键字来实现无数据报警。假设你想监控一个名为 `http_requests_total` 的指标,如果某一实例在过去 5 分钟内没有数据,你希望触发报警。你可以使用以下 PromQL 表达式:
|
||||
|
||||
```promql
|
||||
up unless http_requests_total[5m]
|
||||
```
|
||||
|
||||
这个表达式将返回那些在过去 5 分钟内没有 `http_requests_total` 数据的实例(前提是这些实例仍然在运行状态)。
|
||||
|
||||
结合报警规则:
|
||||
|
||||
```yaml
|
||||
groups:
|
||||
- name: example-alerts
|
||||
rules:
|
||||
- alert: NoDataForHttpRequests
|
||||
expr: up unless http_requests_total[5m]
|
||||
for: 5m
|
||||
labels:
|
||||
severity: critical
|
||||
annotations:
|
||||
summary: "No data for http_requests_total"
|
||||
description: "No data has been received for the metric http_requests_total in the last 5 minutes."
|
||||
```
|
||||
|
||||
### 进一步优化和扩展
|
||||
|
||||
- **多指标组合**:你可以使用 `unless` 结合多个指标来实现更复杂的报警规则。例如,监控多个服务的健康状态和数据采集情况。
|
||||
- **细化标签**:通过在查询中添加标签,可以细化报警规则。例如,只监控特定服务或特定实例的数据缺失情况。
|
||||
|
||||
```promql
|
||||
up{job="myservice"} unless http_requests_total{job="myservice"}[5m]
|
||||
```
|
||||
|
||||
- **结合其他 PromQL 函数**:你可以结合其他 PromQL 函数(如 `rate`, `avg_over_time` 等)来实现更复杂的查询和报警规则。
|
||||
|
||||
### 总结
|
||||
|
||||
使用 Prometheus 的 `unless` 关键字,你可以轻松地实现无数据报警。通过编写合适的 PromQL 表达式并配置报警规则,你可以确保在数据缺失的情况下及时收到通知。这是 Prometheus 强大查询功能的一个具体应用,能够帮助你更好地监控和维护你的系统。
|
||||
1
daliy_note/9月归档/9.4/git.md
Normal file
1
daliy_note/9月归档/9.4/git.md
Normal file
@ -0,0 +1 @@
|
||||
https://cloud.tencent.com/developer/article/1590046
|
||||
3
daliy_note/9月归档/9.4/ssh问题.md
Normal file
3
daliy_note/9月归档/9.4/ssh问题.md
Normal file
@ -0,0 +1,3 @@
|
||||
Host *
|
||||
HostkeyAlgorithms=+ssh-rsa,ssh-dss
|
||||
PubkeyAcceptedAlgorithms=+ssh-rsa,ssh-dss
|
||||
62
daliy_note/9月归档/9.4/uri和url.md
Normal file
62
daliy_note/9月归档/9.4/uri和url.md
Normal file
@ -0,0 +1,62 @@
|
||||
URI(Uniform Resource Identifier)和URL(Uniform Resource Locator)是两个常见的术语,它们用于标识和访问网络资源。尽管它们有许多相似之处,但它们并不是完全相同的概念。
|
||||
|
||||
### URI
|
||||
|
||||
URI(统一资源标识符)是一个通用的标识符,用于标识任何资源。URI可以是一个URL,也可以是URN(Uniform Resource Name)。URI的语法由RFC 3986标准定义。
|
||||
|
||||
URI的基本结构如下:
|
||||
|
||||
```
|
||||
scheme:[//[userinfo@]host[:port]]path[?query][#fragment]
|
||||
```
|
||||
|
||||
|
||||
|
||||
- **scheme**:指定使用的协议(例如,http, https, ftp)。
|
||||
- **userinfo**:可选的用户信息,通常包含用户名和密码。
|
||||
- **host**:资源所在的主机名或IP地址。
|
||||
- **port**:可选的端口号。
|
||||
- **path**:资源的路径。
|
||||
- **query**:可选的查询字符串,用于传递参数。
|
||||
- **fragment**:可选的片段标识符,用于指定资源的某部分。
|
||||
|
||||
### URL
|
||||
|
||||
URL(统一资源定位符)是URI的一个子集,专门用于标识网络资源的定位信息。URL不仅标识资源,而且提供了如何访问资源的具体方法。URL的基本结构也是由RFC 3986定义的。
|
||||
|
||||
URL的基本结构如下:
|
||||
|
||||
```
|
||||
scheme://userinfo@host:port/path?query#fragment
|
||||
```
|
||||
|
||||
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
https://www.example.com:8080/path/to/resource?search=query#section
|
||||
```
|
||||
|
||||
|
||||
|
||||
在这个例子中:
|
||||
|
||||
- `https` 是方案,表示使用HTTPS协议。
|
||||
- `www.example.com` 是主机名。
|
||||
- `8080` 是端口号。
|
||||
- `/path/to/resource` 是路径。
|
||||
- `?search=query` 是查询字符串。
|
||||
- `#section` 是片段标识符。
|
||||
|
||||
### 区别
|
||||
|
||||
- **URI 是一个更广泛的概念**:它可以标识任何资源,而不仅仅是通过网络协议访问的资源。
|
||||
- **URL 是 URI 的一个特例**:它不仅标识资源,还提供访问资源的具体方法。
|
||||
|
||||
### 总结
|
||||
|
||||
- **URI**:统一资源标识符,标识和命名资源。
|
||||
- **URL**:统一资源定位符,标识和定位资源。
|
||||
|
||||
在实践中,URL是最常见的URI形式,特别是在Web开发和互联网应用中。
|
||||
0
daliy_note/9月归档/9.5/9.5.md
Normal file
0
daliy_note/9月归档/9.5/9.5.md
Normal file
7
daliy_note/9月归档/9.5/helm.md
Normal file
7
daliy_note/9月归档/9.5/helm.md
Normal file
@ -0,0 +1,7 @@
|
||||
### 下载 && 安装
|
||||
|
||||
```bash
|
||||
sudo -i
|
||||
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
|
||||
```
|
||||
|
||||
14
daliy_note/9月归档/9.5/kubectl.md
Normal file
14
daliy_note/9月归档/9.5/kubectl.md
Normal file
@ -0,0 +1,14 @@
|
||||
### 下载
|
||||
|
||||
```bash
|
||||
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 安装
|
||||
|
||||
```bash
|
||||
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
|
||||
```
|
||||
|
||||
4
daliy_note/9月归档/9.6/docker.md
Normal file
4
daliy_note/9月归档/9.6/docker.md
Normal file
@ -0,0 +1,4 @@
|
||||
### 空容器一直运行
|
||||
|
||||
docker run -d ubuntu /bin/bash -c "while true; do sleep 1; echo i_am_a_container;done"
|
||||
|
||||
191
daliy_note/9月归档/9.6/shell.md
Normal file
191
daliy_note/9月归档/9.6/shell.md
Normal file
@ -0,0 +1,191 @@
|
||||
在 shell 脚本中,`if` 语句用于条件判断,有多种条件表达式可以使用,其中 `-z`、`-n` 和 `-x` 是用于字符串和文件的条件测试选项。以下是对这些选项的详细解释:
|
||||
|
||||
### 字符串条件判断
|
||||
|
||||
#### `-z`
|
||||
|
||||
`-z` 用于判断字符串是否为空。如果字符串的长度为零,则条件为真。
|
||||
|
||||
```sh
|
||||
if [ -z "$string" ]; then
|
||||
echo "String is empty"
|
||||
else
|
||||
echo "String is not empty"
|
||||
fi
|
||||
```
|
||||
|
||||
#### `-n`
|
||||
|
||||
`-n` 用于判断字符串是否不为空。如果字符串的长度不为零,则条件为真。
|
||||
|
||||
```sh
|
||||
if [ -n "$string" ]; then
|
||||
echo "String is not empty"
|
||||
else
|
||||
echo "String is empty"
|
||||
fi
|
||||
```
|
||||
|
||||
### 文件条件判断
|
||||
|
||||
#### `-x`
|
||||
|
||||
`-x` 用于判断文件是否有可执行权限。如果文件存在且有可执行权限,则条件为真。
|
||||
|
||||
```sh
|
||||
if [ -x "$file" ]; then
|
||||
echo "File is executable"
|
||||
else
|
||||
echo "File is not executable or does not exist"
|
||||
fi
|
||||
```
|
||||
|
||||
### 其他常见文件条件判断选项
|
||||
|
||||
除了 `-x`,还有其他一些常见的文件条件判断选项:
|
||||
|
||||
- `-e`:判断文件是否存在。
|
||||
- `-f`:判断是否为普通文件。
|
||||
- `-d`:判断是否为目录。
|
||||
- `-r`:判断文件是否有读权限。
|
||||
- `-w`:判断文件是否有写权限。
|
||||
|
||||
### 综合示例
|
||||
|
||||
以下是一个综合示例,演示如何使用 `-z`、`-n` 和 `-x` 进行条件判断:
|
||||
|
||||
```sh
|
||||
#!/bin/bash
|
||||
|
||||
file="/path/to/your/file"
|
||||
string="Hello, World!"
|
||||
|
||||
# 判断字符串是否为空
|
||||
if [ -z "$string" ]; then
|
||||
echo "String is empty"
|
||||
else
|
||||
echo "String is not empty"
|
||||
fi
|
||||
|
||||
# 判断字符串是否不为空
|
||||
if [ -n "$string" ]; then
|
||||
echo "String is not empty"
|
||||
else
|
||||
echo "String is empty"
|
||||
fi
|
||||
|
||||
# 判断文件是否有可执行权限
|
||||
if [ -x "$file" ]; then
|
||||
echo "File is executable"
|
||||
else
|
||||
echo "File is not executable or does not exist"
|
||||
fi
|
||||
```
|
||||
|
||||
在 Shell 脚本中,`if` 条件判断可以使用多种标识符来检查文件属性、字符串内容、数值比较等。以下是一些常见的 `if` 判断标识符:
|
||||
|
||||
### 文件条件判断标识符
|
||||
|
||||
- `-e FILE`:判断文件是否存在。
|
||||
- `-f FILE`:判断是否为普通文件。
|
||||
- `-d FILE`:判断是否为目录。
|
||||
- `-r FILE`:判断文件是否可读。
|
||||
- `-w FILE`:判断文件是否可写。
|
||||
- `-x FILE`:判断文件是否可执行。
|
||||
- `-s FILE`:判断文件是否非空(文件大小是否大于零)。
|
||||
- `-L FILE`:判断是否为符号链接。
|
||||
- `-p FILE`:判断是否为命名管道(FIFO)。
|
||||
- `-c FILE`:判断是否为字符设备文件。
|
||||
- `-b FILE`:判断是否为块设备文件。
|
||||
|
||||
### 字符串条件判断标识符
|
||||
|
||||
- `-z STRING`:判断字符串是否为空(长度为零)。
|
||||
- `-n STRING`:判断字符串是否不为空(长度不为零)。
|
||||
- `STRING1 = STRING2`:判断两个字符串是否相等。
|
||||
- `STRING1 != STRING2`:判断两个字符串是否不相等。
|
||||
|
||||
### 数值条件判断标识符
|
||||
|
||||
- `-eq`:等于(equal)。
|
||||
- `-ne`:不等于(not equal)。
|
||||
- `-lt`:小于(less than)。
|
||||
- `-le`:小于或等于(less than or equal)。
|
||||
- `-gt`:大于(greater than)。
|
||||
- `-ge`:大于或等于(greater than or equal)。
|
||||
|
||||
### 逻辑运算符
|
||||
|
||||
- `!`:逻辑非(not)。
|
||||
- `-a`:逻辑与(and)。
|
||||
- `-o`:逻辑或(or)。
|
||||
|
||||
### 组合示例
|
||||
|
||||
以下是一个示例脚本,演示如何使用这些条件判断标识符:
|
||||
|
||||
```sh
|
||||
#!/bin/bash
|
||||
|
||||
file="/path/to/your/file"
|
||||
string1="Hello"
|
||||
string2="World"
|
||||
num1=10
|
||||
num2=20
|
||||
|
||||
# 文件条件判断
|
||||
if [ -e "$file" ]; then
|
||||
echo "File exists"
|
||||
else
|
||||
echo "File does not exist"
|
||||
fi
|
||||
|
||||
if [ -d "$file" ]; then
|
||||
echo "File is a directory"
|
||||
else
|
||||
echo "File is not a directory"
|
||||
fi
|
||||
|
||||
# 字符串条件判断
|
||||
if [ -z "$string1" ]; then
|
||||
echo "String1 is empty"
|
||||
else
|
||||
echo "String1 is not empty"
|
||||
fi
|
||||
|
||||
if [ "$string1" = "$string2" ]; then
|
||||
echo "Strings are equal"
|
||||
else
|
||||
echo "Strings are not equal"
|
||||
fi
|
||||
|
||||
# 数值条件判断
|
||||
if [ $num1 -eq $num2 ]; then
|
||||
echo "Numbers are equal"
|
||||
else
|
||||
echo "Numbers are not equal"
|
||||
fi
|
||||
|
||||
if [ $num1 -lt $num2 ]; then
|
||||
echo "num1 is less than num2"
|
||||
else
|
||||
echo "num1 is not less than num2"
|
||||
fi
|
||||
|
||||
# 逻辑运算
|
||||
if [ -e "$file" -a -x "$file" ]; then
|
||||
echo "File exists and is executable"
|
||||
else
|
||||
echo "File does not exist or is not executable"
|
||||
fi
|
||||
|
||||
if [ -n "$string1" -o -n "$string2" ]; then
|
||||
echo "At least one of the strings is not empty"
|
||||
else
|
||||
echo "Both strings are empty"
|
||||
fi
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
在 shell 脚本中,有多种条件判断标识符可以使用,用于检查文件属性、字符串内容、数值比较和逻辑运算。这些标识符使得脚本能够根据不同条件执行不同的操作,从而增强脚本的灵活性和功能性。
|
||||
5
daliy_note/9月归档/9.9/git.md
Normal file
5
daliy_note/9月归档/9.9/git.md
Normal file
@ -0,0 +1,5 @@
|
||||
https://stackoverflow.com/questions/66366582/github-unexpected-disconnect-while-reading-sideband-packet
|
||||
|
||||
|
||||
|
||||
git config --global http.postBuffer 157286400
|
||||
1
note/.gitignore
vendored
Normal file
1
note/.gitignore
vendored
Normal file
@ -0,0 +1 @@
|
||||
.DS_Store
|
||||
14
note/Blog/chatgpt.md
Normal file
14
note/Blog/chatgpt.md
Normal file
@ -0,0 +1,14 @@
|
||||
### 部署容器 ChatGPT
|
||||
|
||||
- PandoraNext
|
||||
|
||||
```bash
|
||||
docker run -d --restart always \
|
||||
--name PandoraNext \
|
||||
--net=internal \
|
||||
-p 8181:8181 \
|
||||
-v /root/data/pandora/data:/data \
|
||||
-v /root/data/pandora/sessions:/root/.cache/PandoraNext \
|
||||
pengzhile/pandora-next
|
||||
```
|
||||
|
||||
82
note/Blog/折腾wordpress.md
Normal file
82
note/Blog/折腾wordpress.md
Normal file
@ -0,0 +1,82 @@
|
||||
### docker 部署 mysql
|
||||
|
||||
```bash
|
||||
docker run -d --privileged=true \
|
||||
--net=internal \
|
||||
--name mysql \
|
||||
-v /root/data/mysql:/var/lib/mysql \
|
||||
-e MYSQL_ROOT_PASSWORD=XXXXX \
|
||||
-p 3206:3306 \
|
||||
mysql:5.7
|
||||
```
|
||||
|
||||
### docker 部署 wordpress
|
||||
|
||||
```bash
|
||||
docker run -itd \
|
||||
--name wp \
|
||||
--net=internal \
|
||||
--link mysql \
|
||||
wordpress:latest
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Nginx 代理 wordpress
|
||||
|
||||
```nginx
|
||||
server{
|
||||
listen 443 ssl;
|
||||
server_name test.heysq.com;
|
||||
ssl_certificate /etc/nginx/ssls/heysq_com/cert.pem;
|
||||
ssl_certificate_key /etc/nginx/ssls/heysq_com/key.pem;
|
||||
ssl_session_timeout 5m;
|
||||
client_max_body_size 500m;
|
||||
location / {
|
||||
proxy_pass http://wp:80;
|
||||
proxy_redirect off;
|
||||
proxy_set_header Host $host;
|
||||
proxy_set_header X-Real-IP $remote_addr;
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header X-Forwarded-Host $server_name;
|
||||
proxy_set_header X-Forwarded-Proto https;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_read_timeout 86400;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 访问test.heysq.com
|
||||
|
||||
- 页面报错阻止加载混合活动内容,因为浏览器安全策略,禁止https网站内部加载http请求
|
||||
|
||||

|
||||
|
||||
### wordpress配置
|
||||
|
||||
- 在没有页面样式的情况下进行wordpress配置数据库和站点信息
|
||||
|
||||
- 配置完站点信息后,进入wordpress容器查看生成的`wp-config.php`文件
|
||||
|
||||
<img src="https://blog-heysq-1255479807.cos.ap-beijing.myqcloud.com/note/image-20231220102119917.png" alt="image-20231220102119917" style="zoom:50%;" />
|
||||
|
||||
- 按照wordpress官网的教程,在`wp-config.php`文件中添加以下代码
|
||||
|
||||
```php
|
||||
define('FORCE_SSL_ADMIN', true);
|
||||
|
||||
if (strpos($_SERVER['HTTP_X_FORWARDED_PROTO'], 'https') !== false){
|
||||
$_SERVER['HTTPS'] = 'on';
|
||||
$_SERVER['SERVER_PORT'] = 443;
|
||||
}
|
||||
if (isset($_SERVER['HTTP_X_FORWARDED_HOST'])) {
|
||||
$_SERVER['HTTP_HOST'] = $_SERVER['HTTP_X_FORWARDED_HOST'];
|
||||
}
|
||||
|
||||
define('WP_HOME','https://test.heysq.com/'); // 替换成自己网站的域名
|
||||
define('WP_SITEURL','https://test.heysq.com/'); // 替换成自己网站的域名
|
||||
```
|
||||
|
||||
- 刷新站点页面,wordpress 样式恢复正常
|
||||
|
||||
69
note/Go/GMP.md
Normal file
69
note/Go/GMP.md
Normal file
@ -0,0 +1,69 @@
|
||||
### Go goroutine调度
|
||||
- 目的:将 Goroutine 按照一定算法放到不同的操作系统线程中去执行
|
||||
- 调度模型与算法几经演化,从最初的 G-M 模型、到 G-P-M 模型,从不支持抢占,到支持协作式抢占,再到支持基于信号的异步抢占
|
||||
|
||||
### GM模型
|
||||
- 每个 Goroutine 对应于运行时中的一个抽象结构:G(Goroutine)
|
||||
- 被视作“物理 CPU”的操作系统线程,则被抽象为另外一个结构:M(machine)
|
||||
|
||||
#### GM不足
|
||||
- 单一全局互斥锁(Sched.Lock) 和集中状态存储的存在,导致所有 Goroutine 相关操作,比如创建、重新调度等,都要上锁
|
||||
- Goroutine 传递问题:M 经常在 M 之间传递“可运行”的 Goroutine,这导致调度延迟增大,也增加了额外的性能损耗
|
||||
- 每个 M 都做内存缓存,导致内存占用过高,数据局部性较差
|
||||
- 由于系统调用(syscall)而形成的频繁的工作线程阻塞和解除阻塞,导致额外的性能损耗
|
||||
> 集中状态(centralized state),就是一把全局锁要保护的数据太多。这样无论访问哪个数据,都要锁这把全局锁。数据局部性差是因为每个m都会缓存它执行的代码或数据,但是如果在m之间频繁传递goroutine,那么这种局部缓存的意义就没有了。无法实现局部缓存带来的性能提升。
|
||||
|
||||
|
||||
### GMP模型
|
||||
- 在 Go 1.1 版本中实现了 G-P-M 调度模型和work stealing 算法,这个模型一直沿用至今
|
||||

|
||||
|
||||
- P 是一个“逻辑 Proccessor”,每个 G(Goroutine)要想真正运行起来,首先需要被分配一个 P,也就是进入到 P 的本地运行队列(local runq)中
|
||||
- 对于 G 来说,P 就是运行它的“CPU”,可以说:在 G 的眼里只有 P
|
||||
- 从 Go 调度器的视角来看,真正的“CPU”是 M,只有将 P 和 M 绑定,才能让 P 的 runq 中的 G 真正运行起来
|
||||
|
||||
- Go 1.1 模型不支持抢占式调度
|
||||
- GO 1.2 加入抢占式调度,原理就是,Go 编译器在每个函数或方法的入口处加上了一段额外的代码 (runtime.morestack_noctxt),让运行时有机会在这段代码中检查是否需要执行抢占调度,弊端就是只有在函数或方法不能能加入代码,纯算法循环代码无法加入调度功能(比如死循环)
|
||||
- Go 1.14 版本中增加了对非协作的抢占式调度的支持,这种抢占式调度是基于系统信号的,也就是通过向线程发送信号的方式来抢占正在运行的 Goroutine
|
||||
> 协作式:大家都按事先定义好的规则来,比如:一个goroutine执行完后,退出,让出p,然后下一个goroutine被调度到p上运行。这样做的缺点就在于 是否让出p的决定权在groutine自身。一旦某个g不主动让出p或执行时间较长,那么后面的goroutine只能等着,没有方法让前者让出p,导致延迟甚至饿死。而非协作: 就是由runtime来决定一个goroutine运行多长时间,如果你不主动让出,对不起,我有手段可以抢占你,把你踢出去,让后面的goroutine进来运行
|
||||
### G
|
||||
- goroutine 缩写,每次go func()都代表一个G,无限制,而且 G 对象是可以重用的
|
||||
- 使用struct runtime.g,包含了当前goroutine的状态,堆栈和上下文
|
||||
|
||||
### M
|
||||
- 工作线程(OS thread)也被称为Machine,使用 struct runtime.m,所有M是有线程栈的(1-8M)
|
||||
- 执行流程是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复
|
||||
- 如果不对该线程栈提供内存的话,系统会给该线程栈提供内存(不同操作系统提供的线程栈大小不同)。当指定了线程栈,则 M.stack→G.stack,M 的 PC 寄存器指向 G 提供的函数,然后去执行
|
||||
|
||||
### P
|
||||
- Processor是一个抽象概念,并不是真正的物理CPU
|
||||
- 代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。负责衔接M和G的调度上下文,将等待执行的G和M进行连接。当P有任务是需要创建或者唤醒一个M来执行 它队列里的任务,所以P/M需要进行绑定,构成一个执行单元
|
||||
- P决定了并发任务的数量,通过runtime.GOMAXPROCS来设定,Go1.5之后被默认设置为可用核数,之前默认设置为1
|
||||
|
||||
### GMP优化部分
|
||||
- netpoller,即便 G 发起网络 I/O 操作,也不会导致 M 被阻塞(仅阻塞 G),也就不会导致大量线程(M)被创建出来
|
||||
- io poller,这个功能可以像 netpoller 那样,在 G 操作那些支持监听(pollable)的文件描述符时,仅会阻塞 G,而不会阻塞 M。不支持对常规文件的监听
|
||||
|
||||
### 协作抢占式监控线程 sysmon M
|
||||
- M 的特殊之处在于它不需要绑定 P 就可以运行(以 g0 这个 G 的形式)
|
||||
- sysmon 每 20us~10ms 启动一次
|
||||
- 释放闲置超过 5 分钟的 span 内存
|
||||
- 如果超过 2 分钟没有垃圾回收,强制执行
|
||||
- 将长时间未处理的 netpoll 结果添加到任务队列
|
||||
- 向长时间运行的 G 任务发出抢占调度
|
||||
- 收回因 syscall 长时间阻塞的 P
|
||||
|
||||
### sysmon M 抢占调度goroutine
|
||||
- 如果一个 G 任务运行 10ms,sysmon 就会认为它的运行时间太久而发出抢占式调度的请求
|
||||
- 一旦 G 的抢占标志位被设为 true,等到这个 G 下一次调用函数或方法时,运行时就可以将 G 抢占并移出运行状态,放入队列中,等待下一次被调度
|
||||
|
||||
### channel 阻塞或网络 I/O 情况下的调度
|
||||
- G 被阻塞在某个 channel 操作或网络 I/O 操作上时,G 会被放置到某个等待(wait)队列中,而 M 会尝试运行 P 的下一个可运行的 G
|
||||
- 如果这个时候 P 没有可运行的 G 供 M 运行,那么 M 将解绑 P,并进入挂起状态
|
||||
- 当 I/O 操作完成或 channel 操作完成,在等待队列中的 G 会被唤醒,标记为可运行(runnable),并被放入到某 P 的队列中,绑定一个 M 后继续执行
|
||||
|
||||
### 系统调用阻塞情况下的调度
|
||||
- G 被阻塞在某个系统调用(system call)上,不光 G 会阻塞,执行这个 G 的 M 也会解绑 P,与 G 一起进入挂起状态
|
||||
- 如果此时有空闲的 M,那么 P 就会和它绑定,并继续执行其他 G
|
||||
- 如果没有空闲的 M,但仍然有其他 G 要去执行,Go 运行时就会创建一个新 M(线程)
|
||||
- 当进行一些慢系统调用的时候,比如常规文件io,执行系统调用的m就要和g一起挂起,这是os的要求,不是go runtime的要求。毕竟真正执行代码的还是m
|
||||
30
note/Go/GMP细节.md
Normal file
30
note/Go/GMP细节.md
Normal file
@ -0,0 +1,30 @@
|
||||
[Go:g0,特殊的 Goroutine](https://zhuanlan.zhihu.com/p/213745994)
|
||||
### 创建P
|
||||
- P 的初始化:首先会创建逻辑 CPU 核数个 P ,存储在 sched 的 空闲链表(pidle)。
|
||||

|
||||
|
||||
### 创建os thread
|
||||
- 准备运行的新 goroutine 将唤醒 P 以更好地分发工作。这个 P 将创建一个与之关联的 M 绑定到一个OS thread
|
||||
- go func() 中 触发 Wakeup 唤醒机制,有空闲的 Processor 而没有在 spinning 状态的 Machine 时候, 需要去唤醒一个空闲(睡眠)的 M 或者新建一个。spinning就是自选状态,没有任务处理,自旋一段时间后进入睡眠状态等待下次被唤醒
|
||||
|
||||
### 创建M0 main
|
||||
- 程序启动后,Go 已经将主线程和 M 绑定(rt0_go)
|
||||
- 当 goroutine 创建完后,放在当前 P 的 local queue,如果本地队列满了,它会将本地队列的前半部分和 newg 迁移到全局队列中
|
||||
|
||||
### Work-stealing goroutine偷取
|
||||
- M 绑定的 P 没有可执行的 goroutine 时,它会去按照优先级去抢占任务
|
||||
- 有1/61的概率去选择全局goroutine队列获取任务,防止全局goroutine饥饿
|
||||
- 如果没有的话,去自己本地的队列获取任务
|
||||
- 如果没有的话,去偷取其他P的队列的任务
|
||||
- 如果没有的话,检查其他阻塞的goroutine有没有就绪的
|
||||
- 如果没有进入自旋状态
|
||||
- 找到任何一个任务,切换调用栈执行任务。再循环不断的获取任务,直到进入休眠
|
||||
> 为了保证公平性,从随机位置上的 P 开始,而且遍历的顺序也随机化了(选择一个小于 GOMAXPROCS,且和它互为质数的步长),保证遍历的顺序也随机化了
|
||||
|
||||
### spinning thread 线程自旋
|
||||
- 线程自旋是相对于线程阻塞而言的,表象就是循环执行一个指定逻辑(就是上面提到的调度逻辑,目的是不停地寻找 G)。
|
||||
- 会产生问题,如果 G 迟迟不来,CPU 会白白浪费在这无意义的计算上。但好处也很明显,降低了 M 的上下文切换成本,提高了性能
|
||||
- 带P的M不停的找G
|
||||
- 不带P的M找P挂载
|
||||
- G 创建又没 spining M 唤醒一个 M
|
||||
|
||||
26
note/Go/GoModule.md
Normal file
26
note/Go/GoModule.md
Normal file
@ -0,0 +1,26 @@
|
||||
### 语义导入版本
|
||||
- Semantic Import Versioning
|
||||
- go.mod 的 require 段中依赖的版本号,都符合 vX.Y.Z 的格式
|
||||
- 一个符合 Go Module 要求的版本号,由前缀 v 和一个满足语义版本规范的版本号组成
|
||||
- 借助于语义版本规范,Go 命令可以确定同一 module 的两个版本发布的先后次序,而且可以确定它们是否兼容
|
||||
- Go Module 规定:如果同一个包的新旧版本是兼容的,那么它们的包导入路径应该是相同的
|
||||
|
||||
|
||||
#### 语义版本号组成
|
||||
- 主版本
|
||||
- 次版本
|
||||
- 补丁版本
|
||||

|
||||
|
||||
### 最小版本选择
|
||||
- Minimal Version Selection
|
||||
- 项目之间出现依赖同一个包但是不同版本的情况
|
||||
- go mod 选择依赖所有版本的最小的那个版本
|
||||
- go mod 不会选择最新的1.7.0版本,而是选择1.3.0 版本
|
||||

|
||||
|
||||
### GO111MODULE配置值
|
||||
- on 开启
|
||||
- off 关闭
|
||||
- auto 编译器判断
|
||||

|
||||
31
note/Go/GoModule操作.md
Normal file
31
note/Go/GoModule操作.md
Normal file
@ -0,0 +1,31 @@
|
||||
### 为当前项目添加一个依赖
|
||||
- 在代码中import包地址
|
||||
- go get `新的依赖的包地址`
|
||||
- go mod tidy 自动处理包的依赖导入
|
||||
|
||||
### 升级/降级依赖的版本
|
||||
- 项目modules目录,执行go get 指定的版本
|
||||
- go mod edit 更新依赖版本,然后执行go mod tidy
|
||||
- 可以修改go mod 依赖版本号为要使用的分支,然后执行go mod tidy
|
||||
|
||||
### 添加一个主版本号大于 1 的依赖
|
||||
- 在导包的路径上加上版本号
|
||||
- github.com/go-redis/redis/v7
|
||||
- 然后执行go get 或者 go mod tidy
|
||||
|
||||
### 升级依赖版本到一个不兼容版本
|
||||
- 通过空应用更新版本
|
||||
- `import _ "github.com/go-redis/redis/v8"`
|
||||
- 然后执行go get 或者 go mod tidy
|
||||
|
||||
### 移除一个不用的依赖
|
||||
- 删除代码中的引用
|
||||
- 执行 go mod tidy,更新go.mod和go.sum
|
||||
|
||||
### 特殊情况,可以使用vendor
|
||||
- vendor做为go mod的补充
|
||||
- 不方便访问外网进行包下载
|
||||
- 比较关注构建过程中的性能
|
||||
- 通过 `go mod vendor`自动常见vendor目录
|
||||
- 基于vender文件夹进行构建 `go build -mod=vendor`
|
||||
- Go 1.14 及以后版本中,如果 Go 项目的顶层目录下存在 vendor 目录,那么 go build 默认也会优先基于 vendor 构建,除非go build 传入 -mod=mod 的参数
|
||||
88
note/Go/Goroutine泄漏.md
Normal file
88
note/Go/Goroutine泄漏.md
Normal file
@ -0,0 +1,88 @@
|
||||
### 泄漏的大多数原因
|
||||
- Goroutine 内正在进行 channel/mutex 等读写操作,但由于逻辑问题,某些情况下会被一直阻塞。
|
||||
- Goroutine 内的业务逻辑进入死循环,资源一直无法释放。
|
||||
- Goroutine 内的业务逻辑进入长时间等待,有不断新增的 Goroutine 进入等待
|
||||
|
||||
#### channel发送不接收
|
||||
- 开启多个goroutine,写channel
|
||||
- 只读了部分的channel,导致goroutine阻塞不会释放
|
||||
```go
|
||||
package main
|
||||
|
||||
func main() {
|
||||
for i := 0; i < 4; i++ {
|
||||
queryAll()
|
||||
fmt.Printf("goroutines: %d\n", runtime.NumGoroutine())
|
||||
}
|
||||
}
|
||||
|
||||
func queryAll() int {
|
||||
ch := make(chan int)
|
||||
for i := 0; i < 3; i++ {
|
||||
go func() { ch <- query() }()
|
||||
}
|
||||
// 开启多个channel,只接收了一个
|
||||
return <-ch
|
||||
}
|
||||
|
||||
func query() int {
|
||||
n := rand.Intn(100)
|
||||
time.Sleep(time.Duration(n) * time.Millisecond)
|
||||
return n
|
||||
}
|
||||
```
|
||||
|
||||
#### channel接收不发送
|
||||
- 只开启了接收,但是没有goroutine去发送数据到channel
|
||||
```go
|
||||
func main() {
|
||||
defer func() {
|
||||
fmt.Println("goroutines: ", runtime.NumGoroutine())
|
||||
}()
|
||||
|
||||
var ch chan struct{}
|
||||
go func() {
|
||||
ch <- struct{}{}
|
||||
}()
|
||||
|
||||
time.Sleep(time.Second)
|
||||
}
|
||||
```
|
||||
|
||||
#### nil channel 读写都会阻塞goroutine
|
||||
```go
|
||||
ch := make(chan int)
|
||||
go func() {
|
||||
<-ch
|
||||
}()
|
||||
ch <- 0
|
||||
time.Sleep(time.Second)
|
||||
```
|
||||
|
||||
#### 请求三方接口没有设置超时等待
|
||||
```go
|
||||
func main() {
|
||||
for {
|
||||
go func() {
|
||||
_, err := http.Get("https://www.xxx.com/")
|
||||
if err != nil {
|
||||
fmt.Printf("http.Get err: %v\n", err)
|
||||
}
|
||||
// do something...
|
||||
}()
|
||||
|
||||
time.Sleep(time.Second * 1)
|
||||
fmt.Println("goroutines: ", runtime.NumGoroutine())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 互斥锁忘记解锁
|
||||
- 互斥锁上锁后,忘记解锁
|
||||
- 造成其他goroutine锁等待,进而产生资源泄漏
|
||||
- `defer lock.Unlock()`
|
||||
|
||||
#### 同步锁使用不当
|
||||
- sync.WaitGroup
|
||||
- `Add`的数量和`Done`的数量不一致
|
||||
- `Wait`方法一直阻塞
|
||||
12
note/Go/Goroutine状态.md
Normal file
12
note/Go/Goroutine状态.md
Normal file
@ -0,0 +1,12 @@
|
||||
状态 | 含义
|
||||
-- | --
|
||||
_Gidle | 刚刚被分配,还没有进行初始化。
|
||||
_Grunnable | 已经在运行队列中,还没有执行用户代码。
|
||||
_Grunning | 不在运行队列里中,已经可以执行用户代码,此时已经分配了 M 和 P。
|
||||
_Gsyscall | 正在执行系统调用,此时分配了 M。
|
||||
_Gwaiting | 在运行时被阻止,没有执行用户代码,也不在运行队列中,此时它正在某处阻塞等待中。
|
||||
_Gmoribund_unused | 尚未使用,但是在 gdb 中进行了硬编码。
|
||||
_Gdead | 尚未使用,这个状态可能是刚退出或是刚被初始化,此时它并没有执行用户代码,有可能有也有可能没有分配堆栈。
|
||||
_Genqueue_unused | 尚未使用。
|
||||
_Gcopystack | 正在复制堆栈,并没有执行用户代码,也不在运行队列中。
|
||||
|
||||
7
note/Go/Go简介.md
Normal file
7
note/Go/Go简介.md
Normal file
@ -0,0 +1,7 @@
|
||||
### Go 语言的设计哲学
|
||||
- 简单、显式、组合、并发和面向工程
|
||||
- 简单是指 Go 语言特性始终保持在少且足够的水平,不走语言特性融合的道路,但又不乏生产力。简单是 Go 生产力的源泉,也是 Go 对开发者的最大吸引力
|
||||
- 显式是指任何代码行为都需开发者明确知晓,不存在因“暗箱操作”而导致可维护性降低和不安全的结果:类型显示转换
|
||||
- 组合是构建 Go 程序骨架的主要方式,它可以大幅降低程序元素间的耦合,提高程序的可扩展性和灵活性,接口之间组合实现面向对象与继承
|
||||
- 并发是 Go 敏锐地把握了 CPU 向多核方向发展这一趋势的结果,可以让开发人员在多核时代更容易写出充分利用系统资源、支持性能随 CPU 核数增加而自然提升的应用程序:goroutine,select和channel的结合
|
||||
- 面向工程是 Go 语言在语言设计上的一个重大创新,它将语言要解决的问题域扩展到那些原本并不是由编程语言去解决的领域,从而覆盖了更多开发者在开发过程遇到的“痛点”,为开发者提供了更好的使用体验:没有用到的包和变量构建时报错,禁止包循环依赖
|
||||
553
note/Go/MAP哈希.md
Normal file
553
note/Go/MAP哈希.md
Normal file
@ -0,0 +1,553 @@
|
||||
### Map 常用操作
|
||||
#### 初始化
|
||||
- var m1 map[string]int // m1 == nil 结果为true,此时写入会产生panic
|
||||
- var m2 = map[string]int{}
|
||||
- var m3 = make(map[string]int)
|
||||
- 函数类型、map 类型自身,以及切片类型是不能作为 map 的 key 类型的
|
||||
```go
|
||||
|
||||
s1 := make([]int, 1)
|
||||
s2 := make([]int, 2)
|
||||
f1 := func() {}
|
||||
f2 := func() {}
|
||||
m1 := make(map[int]string)
|
||||
m2 := make(map[int]string)
|
||||
println(s1 == s2) // 错误:invalid operation: s1 == s2 (slice can only be compared to nil)
|
||||
println(f1 == f2) // 错误:invalid operation: f1 == f2 (func can only be compared to nil)
|
||||
println(m1 == m2) // 错误:invalid operation: m1 == m2 (map can only be compared to nil)
|
||||
```
|
||||
- makemap_small 源码
|
||||
```go
|
||||
// makemap_small implements Go map creation for make(map[k]v) and
|
||||
// make(map[k]v, hint) when hint is known to be at most bucketCnt
|
||||
// at compile time and the map needs to be allocated on the heap.
|
||||
// 创建map不指定容量,或者容量小于bucketCnt(这个容量为8)
|
||||
func makemap_small() *hmap {
|
||||
h := new(hmap)
|
||||
h.hash0 = fastrand()
|
||||
return h
|
||||
}
|
||||
|
||||
```
|
||||
- makemap 源码
|
||||
```go
|
||||
// makemap implements Go map creation for make(map[k]v, hint).
|
||||
// If the compiler has determined that the map or the first bucket
|
||||
// can be created on the stack, h and/or bucket may be non-nil.
|
||||
// If h != nil, the map can be created directly in h.
|
||||
// If h.buckets != nil, bucket pointed to can be used as the first bucket.
|
||||
func makemap(t *maptype, hint int, h *hmap) *hmap {
|
||||
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
|
||||
// 数据范围溢出,设置为0
|
||||
if overflow || mem > maxAlloc {
|
||||
hint = 0
|
||||
}
|
||||
|
||||
// initialize Hmap
|
||||
if h == nil {
|
||||
h = new(hmap)
|
||||
}
|
||||
// 随机种子
|
||||
h.hash0 = fastrand()
|
||||
|
||||
// Find the size parameter B which will hold the requested # of elements.
|
||||
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
|
||||
B := uint8(0)
|
||||
for overLoadFactor(hint, B) {
|
||||
B++
|
||||
}
|
||||
h.B = B
|
||||
|
||||
// allocate initial hash table
|
||||
// if B == 0, the buckets field is allocated lazily later (in mapassign)
|
||||
// If hint is large zeroing this memory could take a while.
|
||||
if h.B != 0 {
|
||||
var nextOverflow *bmap
|
||||
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
|
||||
if nextOverflow != nil {
|
||||
h.extra = new(mapextra)
|
||||
h.extra.nextOverflow = nextOverflow
|
||||
}
|
||||
}
|
||||
|
||||
return h
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
#### 写map
|
||||
- key, value 写入
|
||||
- mapassign源码
|
||||
```go
|
||||
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
|
||||
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
|
||||
if h == nil {
|
||||
panic(plainError("assignment to entry in nil map"))
|
||||
}
|
||||
if raceenabled {
|
||||
callerpc := getcallerpc()
|
||||
pc := funcPC(mapassign)
|
||||
racewritepc(unsafe.Pointer(h), callerpc, pc)
|
||||
raceReadObjectPC(t.key, key, callerpc, pc)
|
||||
}
|
||||
if msanenabled {
|
||||
msanread(key, t.key.size)
|
||||
}
|
||||
// hashWriting = 4 固定值 二进制 0000 0100
|
||||
if h.flags&hashWriting != 0 {
|
||||
throw("concurrent map writes")
|
||||
}
|
||||
hash := t.hasher(key, uintptr(h.hash0))
|
||||
|
||||
|
||||
// Set hashWriting after calling t.hasher, since t.hasher may panic,
|
||||
// in which case we have not actually done a write.
|
||||
// map真正写入前设置标记位,其他goroutine写入会马上 throw("concurrent map writes")
|
||||
// 异或操作,相同为0,不同为1,修改第三位为1,保留其他位为原值,再次进行与操作时,等于1,然后就会崩溃
|
||||
h.flags ^= hashWriting
|
||||
|
||||
if h.buckets == nil {
|
||||
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
|
||||
}
|
||||
|
||||
// 省略部分代码
|
||||
```
|
||||
|
||||
#### 读map
|
||||
- value := hash[key]
|
||||
- value, ok := hash[key]
|
||||
- 如果key不存在,返回value类型的零值
|
||||
- mapaccess1 返回val 源码
|
||||
- mapaccess2 返回val和bool
|
||||
```go
|
||||
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
|
||||
// it will return a reference to the zero object for the elem type if
|
||||
// the key is not in the map.
|
||||
// NOTE: The returned pointer may keep the whole map live, so don't
|
||||
// hold onto it for very long.
|
||||
|
||||
// key不存在返回类型的零值
|
||||
// 不要持有返回的指针太长时间,容易造成GC无法回收map,导致内存泄漏
|
||||
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
|
||||
if raceenabled && h != nil {
|
||||
callerpc := getcallerpc()
|
||||
pc := funcPC(mapaccess1)
|
||||
racereadpc(unsafe.Pointer(h), callerpc, pc)
|
||||
raceReadObjectPC(t.key, key, callerpc, pc)
|
||||
}
|
||||
if msanenabled && h != nil {
|
||||
msanread(key, t.key.size)
|
||||
}
|
||||
// map 为空
|
||||
if h == nil || h.count == 0 {
|
||||
if t.hashMightPanic() {
|
||||
t.hasher(key, 0) // see issue 23734
|
||||
}
|
||||
return unsafe.Pointer(&zeroVal[0])
|
||||
}
|
||||
// 有正在写的goroutine,崩溃fatal error
|
||||
if h.flags&hashWriting != 0 {
|
||||
throw("concurrent map read and map write")
|
||||
}
|
||||
hash := t.hasher(key, uintptr(h.hash0)) // 根据key计算的hash值
|
||||
m := bucketMask(h.B) // 桶的个数
|
||||
|
||||
// 指针计算,找到key应该在的bmap
|
||||
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
|
||||
|
||||
// 桶正在扩容
|
||||
if c := h.oldbuckets; c != nil {
|
||||
if !h.sameSizeGrow() {
|
||||
// There used to be half as many buckets; mask down one more power of two.
|
||||
m >>= 1
|
||||
}
|
||||
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
|
||||
if !evacuated(oldb) {
|
||||
b = oldb
|
||||
}
|
||||
}
|
||||
|
||||
top := tophash(hash)
|
||||
// 遍历bucket
|
||||
bucketloop:
|
||||
for ; b != nil; b = b.overflow(t) {
|
||||
for i := uintptr(0); i < bucketCnt; i++ {
|
||||
if b.tophash[i] != top {
|
||||
if b.tophash[i] == emptyRest {
|
||||
break bucketloop
|
||||
}
|
||||
continue
|
||||
}
|
||||
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
|
||||
if t.indirectkey() {
|
||||
k = *((*unsafe.Pointer)(k))
|
||||
}
|
||||
if t.key.equal(key, k) {
|
||||
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
|
||||
if t.indirectelem() {
|
||||
e = *((*unsafe.Pointer)(e))
|
||||
}
|
||||
return e
|
||||
}
|
||||
}
|
||||
}
|
||||
// 没有的话 返回零值
|
||||
return unsafe.Pointer(&zeroVal[0])
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### 删除map中的元素
|
||||
- delete(map, key)
|
||||
- `mapdelete` 方法
|
||||
|
||||
#### range map
|
||||
- 调用 `mapiterinit` 方法进行初始化
|
||||
- 不断调用 `mapiternext` 方法进行循环
|
||||
### 特性
|
||||
- map是个指针,底层指向hmap,所以是个引用类型
|
||||
- golang slice、map、channel都是引用类型,当引用类型作为函数参数时,可能会修改原内容数据
|
||||
- golang 中没有引用传递,只有值和指针传递。map 作为函数实参传递时本质上也是值传递,因为 map 底层数据结构是通过指针指向实际的元素存储空间,在被调函数中修改 map,对调用者同样可见,所以 map 作为函数实参传递时表现出了引用传递的效果
|
||||
- map 底层数据结构是通过指针指向实际的元素存储空间,对其中一个map的更改,会影响到其他map
|
||||
- 遍历无序
|
||||
- map 可以自动扩容,map 中数据元素的 value 位置可能在这一过程中发生变化,所以 Go 不允许获取 map 中 value 的地址,这个约束是在编译期间就生效的
|
||||
|
||||
### Map 实现原理
|
||||
- Go中的map是一个指针,占用8个字节,指向hmap结构体; 源码src/runtime/map.go中可以看到map的底层结构
|
||||
- 每个map的底层结构是hmap,hmap包含若干个结构为bmap的bucket数组。每个bucket底层都采用链表结构
|
||||
- 每个 bucket 中存储的是 Hash 值低 bit 位数值相同的元素,默认的元素个数为 BUCKETSIZE(值为 8,Go 1.17 版本中在 $GOROOT/src/cmd/compile/internal/reflectdata/reflect.go 中定义,与runtime/map.go 中常量 bucketCnt 保持一致)
|
||||
- 当某个 bucket(比如 buckets[0]) 的 8 个空槽 slot)都填满了,且 map 尚未达到扩容的条件的情况下,运行时会建立 overflow bucket,并将这个 overflow bucket 挂在上面 bucket(如 buckets[0])末尾的 overflow 指针上,这样两个 buckets 形成了一个链表结构,直到下一次 map 扩容之前,这个结构都会一直存在
|
||||
- map 结构,key和value单独排列在一起可以减少结构体对齐填充,减少内存浪费
|
||||

|
||||

|
||||
```golang
|
||||
|
||||
// A header for a Go map.
|
||||
type hmap struct {
|
||||
count int
|
||||
// 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
|
||||
flags uint8 // 标记 扩容状态,读写状态
|
||||
B uint8
|
||||
// buckets(桶)的对数log_2
|
||||
// 如果B=5,则buckets数组的长度 = 2^5=32,意味着有32个桶
|
||||
noverflow uint16
|
||||
// 溢出桶的大概数量
|
||||
hash0 uint32
|
||||
// 哈希种子
|
||||
|
||||
buckets unsafe.Pointer
|
||||
// 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
|
||||
oldbuckets unsafe.Pointer
|
||||
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针,
|
||||
// 老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
|
||||
nevacuate uintptr
|
||||
// 表示扩容进度,小于此地址的buckets代表已搬迁完成。
|
||||
|
||||
extra *mapextra
|
||||
// 这个字段是为了优化GC扫描而设计的。当key和value均不包含指针
|
||||
// 并且都可以inline时使用。extra是指向mapextra类型的指针。
|
||||
}
|
||||
```
|
||||
- bmap结构
|
||||
```go
|
||||
bucketCntBits = 3
|
||||
bucketCnt = 1 << bucketCntBits
|
||||
|
||||
// A bucket for a Go map.
|
||||
type bmap struct {
|
||||
// tophash generally contains the top byte of the hash value
|
||||
// for each key in this bucket. If tophash[0] < minTopHash,
|
||||
// tophash[0] is a bucket evacuation state instead.
|
||||
tophash [bucketCnt]uint8
|
||||
// Followed by bucketCnt keys and then bucketCnt elems.
|
||||
// NOTE: packing all the keys together and then all the elems together makes the
|
||||
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
|
||||
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
|
||||
// Followed by an overflow pointer.
|
||||
|
||||
// len为8的数组
|
||||
// 用来快速定位key是否在这个bmap中
|
||||
// 桶的槽位数组,一个桶最多8个槽位,如果key所在的槽位在tophash中,则代表该key在这个桶中
|
||||
// key 单独放在一起,value单独放在一起,相同的类型放在一起,减少空间浪费,
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
- mapextra结构
|
||||
```go
|
||||
// mapextra holds fields that are not present on all maps.
|
||||
// 字面理解附加字段
|
||||
type mapextra struct {
|
||||
// If both key and elem do not contain pointers and are inline, then we mark bucket
|
||||
// type as containing no pointers. This avoids scanning such maps.
|
||||
// However, bmap.overflow is a pointer. In order to keep overflow buckets
|
||||
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
|
||||
// overflow and oldoverflow are only used if key and elem do not contain pointers.
|
||||
// overflow contains overflow buckets for hmap.buckets.
|
||||
// oldoverflow contains overflow buckets for hmap.oldbuckets.
|
||||
// The indirection allows to store a pointer to the slice in hiter.
|
||||
|
||||
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
|
||||
// 就使用 hmap的extra字段 来存储 overflow buckets,这样可以避免 GC 扫描整个 map
|
||||
// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针
|
||||
// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了
|
||||
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
|
||||
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
|
||||
|
||||
overflow *[]*bmap
|
||||
oldoverflow *[]*bmap
|
||||
|
||||
// nextOverflow holds a pointer to a free overflow bucket.
|
||||
nextOverflow *bmap
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### tophash区域
|
||||
- 向 map 插入一条数据,或者是从 map 按 key 查询数据的时候,运行时都会使用哈希函数对 key 做哈希运算,并获得一个哈希值(hashcode)
|
||||
- 运行时会把 hashcode“一分为二”来看待,其中低位区的值用于选定 bucket,高位区的值用于在某个 bucket 中确定 key 的位置
|
||||
- 每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,避免了逐个 key 进行比较这种代价较大的操作
|
||||

|
||||
|
||||
### 为什么遍历map无序?
|
||||
- range map,初始化时调用`fastrand()`随机一个数字,决定本次range的起始点
|
||||
```go
|
||||
// mapiterinit initializes the hiter struct used for ranging over maps.
|
||||
// The hiter struct pointed to by 'it' is allocated on the stack
|
||||
// by the compilers order pass or on the heap by reflect_mapiterinit.
|
||||
// Both need to have zeroed hiter since the struct contains pointers.
|
||||
func mapiterinit(t *maptype, h *hmap, it *hiter) {
|
||||
// 省略一部分
|
||||
|
||||
// decide where to start
|
||||
// 开始迭代时会有一个随机数,决定起始位置
|
||||
r := uintptr(fastrand())
|
||||
if h.B > 31-bucketCntBits {
|
||||
r += uintptr(fastrand()) << 31
|
||||
}
|
||||
it.startBucket = r & bucketMask(h.B)
|
||||
it.offset = uint8(r >> h.B & (bucketCnt - 1))
|
||||
|
||||
// iterator state
|
||||
it.bucket = it.startBucket
|
||||
|
||||
// Remember we have an iterator.
|
||||
// Can run concurrently with another mapiterinit().
|
||||
if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {
|
||||
atomic.Or8(&h.flags, iterator|oldIterator)
|
||||
}
|
||||
|
||||
mapiternext(it)
|
||||
}
|
||||
|
||||
|
||||
```
|
||||
|
||||
### 怎么有序遍历map
|
||||
- 先取出map的key
|
||||
- 对key进行排序
|
||||
- 循环排序后的key,实现有序遍历map
|
||||
|
||||
### 为什么map非线程安全
|
||||
- 并发访问需要控制锁相关,防止出现资源竞争
|
||||
- 大部分不需要从多个goroutine同时读写map,加锁反而造成性能降低
|
||||
|
||||
```go
|
||||
func mapiternext(it *hiter) {
|
||||
h := it.h
|
||||
if raceenabled {
|
||||
callerpc := getcallerpc()
|
||||
racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiternext))
|
||||
}
|
||||
if h.flags&hashWriting != 0 {
|
||||
// 直接抛出异常,fatal error
|
||||
throw("concurrent map iteration and map write")
|
||||
}
|
||||
t := it.t
|
||||
bucket := it.bucket
|
||||
b := it.bptr
|
||||
i := it.i
|
||||
checkBucket := it.checkBucket
|
||||
// 省略部分代码
|
||||
}
|
||||
```
|
||||
|
||||
### 线程安全的map怎么实现
|
||||
- 使用读写锁 `map` + `sync.RWMutex`
|
||||
- [sync.Map](../../mkdocs_wiki/go/sync_map.md)
|
||||
|
||||
### map扩容策略
|
||||
|
||||
- 装载因子超过阈值,源码里定义的阈值是 6.5
|
||||
- overflow 的 bucket 数量过多:当 B 小于 15,也即 bucket 总数小于 2^15 时,overflow 的 bucket 数量超过 2^B;当 B >= 15,也即 bucket 总数大于等于 2^15时,overflow 的 bucket 数量超过 2^15。
|
||||
- 命中装载因子增量扩容
|
||||
- 命中溢出桶太多,等量扩容
|
||||
- 扩容时,只是把原来的桶挂载到新的桶上,然后采用增量复制去迁移桶内的数据
|
||||
|
||||
|
||||
```go
|
||||
// Maximum average load of a bucket that triggers growth is 6.5.
|
||||
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
|
||||
loadFactorNum = 13
|
||||
loadFactorDen = 2
|
||||
|
||||
|
||||
// growing reports whether h is growing. The growth may be to the same size or bigger.
|
||||
func (h *hmap) growing() bool {
|
||||
return h.oldbuckets != nil
|
||||
}
|
||||
|
||||
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
|
||||
func overLoadFactor(count int, B uint8) bool {
|
||||
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
|
||||
}
|
||||
|
||||
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
|
||||
// Note that most of these overflow buckets must be in sparse use;
|
||||
// if use was dense, then we'd have already triggered regular map growth.
|
||||
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
|
||||
// If the threshold is too low, we do extraneous work.
|
||||
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
|
||||
// "too many" means (approximately) as many overflow buckets as regular buckets.
|
||||
// See incrnoverflow for more details.
|
||||
if B > 15 {
|
||||
B = 15
|
||||
}
|
||||
// 15 & 15 = 15
|
||||
// 判断符右边最大的结果就是1 << 15
|
||||
// 这个操作可能是见的太少,为什么要用15呢?
|
||||
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
|
||||
return noverflow >= uint16(1)<<(B&15)
|
||||
}
|
||||
|
||||
// Did not find mapping for key. Allocate new cell & add entry.
|
||||
|
||||
// If we hit the max load factor or we have too many overflow buckets,
|
||||
// and we're not already in the middle of growing, start growing.
|
||||
// 最大装载因子或者溢出桶太多,然后还没有在扩容状态,开始扩容
|
||||
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
|
||||
hashGrow(t, h)
|
||||
goto again
|
||||
}
|
||||
|
||||
func hashGrow(t *maptype, h *hmap) {
|
||||
// 命中装载因子,增量扩容
|
||||
// 溢出桶太多,等量扩容
|
||||
// If we've hit the load factor, get bigger.
|
||||
// Otherwise, there are too many overflow buckets,
|
||||
// so keep the same number of buckets and "grow" laterally.
|
||||
bigger := uint8(1)
|
||||
if !overLoadFactor(h.count+1, h.B) {
|
||||
bigger = 0
|
||||
h.flags |= sameSizeGrow
|
||||
}
|
||||
oldbuckets := h.buckets
|
||||
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
|
||||
|
||||
flags := h.flags &^ (iterator | oldIterator)
|
||||
if h.flags&iterator != 0 {
|
||||
flags |= oldIterator
|
||||
}
|
||||
// commit the grow (atomic wrt gc)
|
||||
h.B += bigger // 如果bigger是0就是等量扩容,是1就是2倍,翻倍扩容
|
||||
h.flags = flags
|
||||
h.oldbuckets = oldbuckets
|
||||
h.buckets = newbuckets
|
||||
h.nevacuate = 0
|
||||
h.noverflow = 0
|
||||
|
||||
if h.extra != nil && h.extra.overflow != nil {
|
||||
// Promote current overflow buckets to the old generation.
|
||||
if h.extra.oldoverflow != nil {
|
||||
throw("oldoverflow is not nil")
|
||||
}
|
||||
h.extra.oldoverflow = h.extra.overflow
|
||||
h.extra.overflow = nil
|
||||
}
|
||||
if nextOverflow != nil {
|
||||
if h.extra == nil {
|
||||
h.extra = new(mapextra)
|
||||
}
|
||||
h.extra.nextOverflow = nextOverflow
|
||||
}
|
||||
|
||||
// 哈希表数据的实际复制是增量完成的
|
||||
// 通过growWork() 和evacuate()。
|
||||
// the actual copying of the hash table data is done incrementally
|
||||
// by growWork() and evacuate().
|
||||
}
|
||||
|
||||
// 写或者删map中的元素才会调用growWork
|
||||
// mapassign
|
||||
// mapdelete
|
||||
func growWork(t *maptype, h *hmap, bucket uintptr) {
|
||||
// make sure we evacuate the oldbucket corresponding
|
||||
// to the bucket we're about to use
|
||||
|
||||
evacuate(t, h, bucket&h.oldbucketmask())
|
||||
|
||||
// evacuate one more oldbucket to make progress on growing
|
||||
if h.growing() {
|
||||
evacuate(t, h, h.nevacuate)
|
||||
}
|
||||
}
|
||||
|
||||
// 迁移桶内数据
|
||||
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
|
||||
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
|
||||
newbit := h.noldbuckets()
|
||||
if !evacuated(b) {
|
||||
// TODO: reuse overflow buckets instead of using new ones, if there
|
||||
// is no iterator using the old buckets. (If !oldIterator.)
|
||||
|
||||
// 先搞长度2个的数组
|
||||
// xy contains the x and y (low and high) evacuation destinations.
|
||||
var xy [2]evacDst
|
||||
x := &xy[0] // 用一个
|
||||
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
|
||||
x.k = add(unsafe.Pointer(x.b), dataOffset)
|
||||
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
|
||||
|
||||
if !h.sameSizeGrow() { // 不是等量扩容,再用另一个
|
||||
// Only calculate y pointers if we're growing bigger.
|
||||
// Otherwise GC can see bad pointers.
|
||||
y := &xy[1]
|
||||
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
|
||||
y.k = add(unsafe.Pointer(y.b), dataOffset)
|
||||
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### map哈希冲突解决方法
|
||||
|
||||
- 开放寻址法:**依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中**,使用开放寻址法来实现哈希表,那么实现哈希表底层的数据结构就是数组
|
||||
|
||||
- 首次索引写入位置 `index := hash("author") % array.len`
|
||||
|
||||
- 如果发生冲突,就会将键值对写入到下一个索引不为空的位置
|
||||
|
||||
|
||||
|
||||
- 读取数据时,会从index位置开始读取并判断key是否相等,不相等的话读下一个索引位置,直到读到或者key为空时返回数据
|
||||
|
||||
|
||||
|
||||
- 装载因子:数组中元素与数组长度的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,会影响哈希表的读写性能。当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入任意元素的时间复杂度都是 𝑂(𝑛) 的,这时需要遍历数组中的全部元素
|
||||
|
||||
- 拉链法
|
||||
|
||||
- 一般会使用数组加上链表,一些编程语言会在拉链法的哈希中引入红黑树以优化性能,拉链法会使用链表数组作为哈希底层的数据结构,可以将它看成可以扩展的二维数组:
|
||||
|
||||
|
||||
- 数组索引位置计算 `index := hash("Key6") % array.len`,根据索引位置,就可以遍历当前桶中的链表,在遍历链表的过程中会遇到以下两种情况:
|
||||
|
||||
1. 找到键相同的键值对 — 更新键对应的值;
|
||||
2. 没有找到键相同的键值对 — 在链表的末尾追加新的键值对
|
||||
|
||||

|
||||
|
||||
- 装载因子:=元素数量÷桶数量
|
||||
|
||||
|
||||
52
note/Go/MAP深拷贝.md
Normal file
52
note/Go/MAP深拷贝.md
Normal file
@ -0,0 +1,52 @@
|
||||
### 深拷贝map
|
||||
|
||||
### 方法一 encoding/gob包
|
||||
|
||||
```go
|
||||
import "encoding/gob"
|
||||
// 需要什么类型的map注册类型就可以
|
||||
func DeepCopy(dst, src interface{}) error {
|
||||
var buf bytes.Buffer
|
||||
gob.Register(map[string]interface{}{})
|
||||
gob.Register([]interface{}(nil))
|
||||
gob.Register([]map[string]interface{}{})
|
||||
if err := gob.NewEncoder(&buf).Encode(src); err != nil {
|
||||
return err
|
||||
}
|
||||
return gob.NewDecoder(bytes.NewBuffer(buf.Bytes())).Decode(dst)
|
||||
}
|
||||
```
|
||||
|
||||
### 方法二 json 序列化后反序列化
|
||||
|
||||
```go
|
||||
func MapDeepCopy(src, dst interface{}) error {
|
||||
byteSlice, err := json.Marshal(src)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return json.Unmarshal(byteSlice, dst)
|
||||
}
|
||||
```
|
||||
|
||||
### 方法三 循环遍历
|
||||
|
||||
```go
|
||||
func DeepCopy(value interface{}) interface{} {
|
||||
if valueMap, ok := value.(map[string]interface{}); ok {
|
||||
newMap := make(map[string]interface{})
|
||||
for k, v := range valueMap {
|
||||
newMap[k] = DeepCopy(v)
|
||||
}
|
||||
return newMap
|
||||
} else if valueSlice, ok := value.([]interface{}); ok {
|
||||
newSlice := make([]interface{}, len(valueSlice))
|
||||
for k, v := range valueSlice {
|
||||
newSlice[k] = DeepCopy(v)
|
||||
}
|
||||
return newSlice
|
||||
}
|
||||
return value
|
||||
}
|
||||
```
|
||||
|
||||
6
note/Go/fmt包.md
Normal file
6
note/Go/fmt包.md
Normal file
@ -0,0 +1,6 @@
|
||||
### fmt 各种v
|
||||
```go
|
||||
%v 按默认格式输出
|
||||
%+v 在%v的基础上额外输出字段名
|
||||
%#v 在%+v的基础上额外输出类型名
|
||||
```
|
||||
51
note/Go/for循环中尽量不要使用defer.md
Normal file
51
note/Go/for循环中尽量不要使用defer.md
Normal file
@ -0,0 +1,51 @@
|
||||
### for 循环中禁止使用defer
|
||||
- 直接在 for 循环中使用 defer 很可能使得 defer 不能执行,导致内存泄露或者其他资源问题,所以应该将 defer 放到外层。
|
||||
- 若确实需要使用 defer,可以将逻辑封装为一个独立函数或者使用闭包
|
||||
- 错误
|
||||
```go
|
||||
func readFiles(files []string) {
|
||||
for i:=0;i<len(files);i++{
|
||||
f,err:=os.Open(files[i])
|
||||
if err!=nil{
|
||||
println(err.Error())
|
||||
continue
|
||||
}
|
||||
|
||||
// bug here
|
||||
// 在循环中的 defer 只有在循环结束后才会执行
|
||||
// 若 files 很多,会导致大量文件句柄未及时释放
|
||||
defer f.Close()
|
||||
|
||||
bf,err:=io.ReadAll(f)
|
||||
if err!=nil{
|
||||
println(err.Error())
|
||||
}else{
|
||||
println(string(bf))
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
- 正确
|
||||
```go
|
||||
func readFiles(files []string) {
|
||||
for i:=0;i<len(files);i++{
|
||||
readFile(files[i])
|
||||
}
|
||||
}
|
||||
|
||||
func readFile(name string){
|
||||
f,err:=os.Open(name)
|
||||
if err!=nil{
|
||||
println(err.Error())
|
||||
return
|
||||
}
|
||||
defer f.Close()
|
||||
bf,err:=io.ReadAll(f)
|
||||
if err!=nil{
|
||||
println(err.Error())
|
||||
}else{
|
||||
println(string(bf))
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
1
note/Go/go_project.md
Normal file
1
note/Go/go_project.md
Normal file
@ -0,0 +1 @@
|
||||

|
||||
10
note/Go/json转义HTML.md
Normal file
10
note/Go/json转义HTML.md
Normal file
@ -0,0 +1,10 @@
|
||||
### 1、NewEncoder
|
||||
|
||||
```go
|
||||
writer := bytes.Buffer{}
|
||||
encoder := json.NewEncoder(&writer)
|
||||
encoder.SetEscapeHTML(false)
|
||||
encoder.Encode(struct{ Name string }{Name: "1111"})
|
||||
jsonStr := writer.String()
|
||||
```
|
||||
|
||||
36
note/Go/nav.md
Normal file
36
note/Go/nav.md
Normal file
@ -0,0 +1,36 @@
|
||||
* [简述](../../mkdocs_wiki/go/desc.md)
|
||||
* [Map](../../mkdocs_wiki/go/map.md)
|
||||
* [SyncMap](../../mkdocs_wiki/go/sync_map.md)
|
||||
* [Go并发](../../mkdocs_wiki/go/go_complicate.md)
|
||||
* [Goroutine && Thread](../../mkdocs_wiki/go/goroutine_thread.md)
|
||||
* [Goroutine 状态](../../mkdocs_wiki/go/goroutine_status.md)
|
||||
* [Goroutine 泄漏](../../mkdocs_wiki/go/goroutine_xielou.md)
|
||||
* [限流算法&&限流器](../../mkdocs_wiki/go/xianliu.md)
|
||||
* [Channel](../../mkdocs_wiki/go/channel.md)
|
||||
* [Go开源项目](../../mkdocs_wiki/go/go_project.md)
|
||||
* [Go Modules构建模式](../../mkdocs_wiki/go/go_mod.md)
|
||||
* [Go Mod6个常规操作](../../mkdocs_wiki/go/go_mod_operate.md)
|
||||
* [代码块&&作用域](../../mkdocs_wiki/go/daimakuai.md)
|
||||
* [数值类型](../../mkdocs_wiki/go/data_type.md)
|
||||
* [字符串类型](../../mkdocs_wiki/go/string_type.md)
|
||||
* [常量](../../mkdocs_wiki/go/changliang.md)
|
||||
* [数组&&切片](../../mkdocs_wiki/go/array_slice.md)
|
||||
* [杂项](../../mkdocs_wiki/go/zaxiang.md)
|
||||
* [结构体](../../mkdocs_wiki/go/struct.md)
|
||||
* [panic&&recover](../../mkdocs_wiki/go/panic_recover.md)
|
||||
* [条件&&循环](../../mkdocs_wiki/go/condition.md)
|
||||
* [函数](../../mkdocs_wiki/go/function.md)
|
||||
* [方法](../../mkdocs_wiki/go/method.md)
|
||||
* [接口](../../mkdocs_wiki/go/interface.md)
|
||||
* [类型嵌入](../../mkdocs_wiki/go/leixingqianru.md)
|
||||
* [sync包同步原语](../../mkdocs_wiki/go/sync.md)
|
||||
* [Socket模型](../../mkdocs_wiki/go/socket.md)
|
||||
* [GC](../../mkdocs_wiki/go/gc.md)
|
||||
* [GMP](../../mkdocs_wiki/go/gmp.md)
|
||||
* [GMP机制](../../mkdocs_wiki/go/gmp_detail.md)
|
||||
* [原始HTTP SERVER](../../mkdocs_wiki/go/http_server.md)
|
||||
* [运行系统命令](../../mkdocs_wiki/go/system_command.md)
|
||||
* [多版本GO](../../mkdocs_wiki/go/many_go.md)
|
||||
* [fmt备忘](../../mkdocs_wiki/go/fmt.md)
|
||||
* [禁止for循环中使用defer](../../mkdocs_wiki/go/for_defer.md)
|
||||
* [命令行小程序](../../mkdocs_wiki/go/cli.md)
|
||||
95
note/Go/socket.md
Normal file
95
note/Go/socket.md
Normal file
@ -0,0 +1,95 @@
|
||||
### Socket模型
|
||||
- 提供阻塞 I/O 模型,只需在 Goroutine 中以最简单、最易用的“阻塞 I/O 模型”的方式,进行 Socket 操作
|
||||
- 每个 Goroutine 处理一个 TCP 连接成为可能,并且在高并发下依旧表现出色
|
||||
- 在运行时中实现了网络轮询器(netpoller),netpoller 的作用,就是只阻塞执行网络 I/O 操作的 Goroutine,但不阻塞执行 Goroutine 的线程(也就是 M)
|
||||
- Go 程序的用户层(相对于 Go 运行时层)来说,它眼中看到的 goroutine 采用了“阻塞 I/O 模型”进行网络 I/O 操作,Socket 都是“阻塞”的
|
||||
|
||||
### netpoller 网络轮询器
|
||||
- I/O 多路复用机制
|
||||
- 真实的底层操作系统 Socket,是非阻塞的
|
||||
- 运行时拦截了针对底层 Socket 的系统调用返回的错误码,并通过 netpoller 和 Goroutine 调度,让 Goroutine“阻塞”在用户层所看到的 Socket 描述符上
|
||||
|
||||
|
||||
### netpoller流程
|
||||
- 用户层针对某个 Socket 描述符发起read操作时,如果这个 Socket 对应的连接上还没有数据,运行时将这个 Socket 描述符加入到 netpoller 中监听,同时发起此次读操作的 Goroutine 会被挂起
|
||||
- Go 运行时收到 Socket 数据可读的通知,Go 运行时重新唤醒等待在这个 Socket 上准备读数据的 Goroutine
|
||||
- 从 Goroutine 的视角来看,就像是 read 操作一直阻塞在 Socket 描述符上
|
||||
|
||||
### 不同系统io多路复用模型
|
||||
- Linux epoll
|
||||
- Windows iocp
|
||||
- FreeBSD/MacOS kqueue
|
||||
- Solaris event port
|
||||
|
||||
### socket 服务端监听(listen)与接收(Accept)
|
||||
- 服务端程序通常采用一个 Goroutine 处理一个连接
|
||||
```go
|
||||
func handleConn(c net.Conn) {
|
||||
defer c.Close()
|
||||
for {
|
||||
// read from the connection
|
||||
// ... ...
|
||||
// write to the connection
|
||||
//... ...
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
l, err := net.Listen("tcp", ":8888")
|
||||
if err != nil {
|
||||
fmt.Println("listen error:", err)
|
||||
return
|
||||
}
|
||||
|
||||
for {
|
||||
c, err := l.Accept()
|
||||
if err != nil {
|
||||
fmt.Println("accept error:", err)
|
||||
break
|
||||
}
|
||||
// start a new goroutine to handle
|
||||
// the new connection.
|
||||
go handleConn(c)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### socket客户端
|
||||
```go
|
||||
conn, err := net.Dial("tcp", "localhost:8888")
|
||||
conn, err := net.DialTimeout("tcp", "localhost:8888", 2 * time.Second)
|
||||
```
|
||||
|
||||
### socket 全双工通信
|
||||
- 通信双方通过各自获得的 Socket,可以在向对方发送数据包的同时,接收来自对方的数据包
|
||||
- 任何一方的操作系统,都会为已建立的连接分配一个发送缓冲区和一个接收缓冲区
|
||||
- 客户端会通过成功连接服务端后得到的 conn(封装了底层的 socket)向服务端发送数据包
|
||||
- 数据包会先进入到己方(客户端)的发送缓冲区中,之后,这些数据会被操作系统内核通过网络设备和链路,发到服务端的接收缓冲区中,服务端程序再通过代表客户端连接的 conn 读取服务端接收缓冲区中的数据
|
||||
|
||||
### socket 读操作
|
||||
- Socket 中无数据,读操作阻塞
|
||||
- Socket 中有部分数据,成功读出这部分数据,并返回,而不是等待期望长度数据全部读取后,再返回
|
||||
- Socket 中有足够数据,读出read操作的数据,剩余数据分多次读取
|
||||
- Socket 设置读超时,SetReadDeadline 方法接受一个绝对时间作为超时的 deadline,一旦通过这个方法设置了某个 socket 的 Read deadline,无论后续的 Read 操作是否超时,只要不重新设置 Deadline,后面与这个 socket 有关的所有读操作,都会返回超时失败错误
|
||||
- 取消超时设置,可以使用 SetReadDeadline(time.Time{})
|
||||
|
||||
### socket 写操作
|
||||
- Write 调用的返回值 n 的值,与预期要写入的数据长度相等,且 err = nil 时,代表写入成功
|
||||
- 写阻塞,发送方将对方的接收缓冲区,以及自身的发送缓冲区都写满后,再调用 Write 方法就会出现阻塞
|
||||
- 写入部分数据
|
||||
- 写入超时,SetWriteDeadline,如果出现超时,无论后续 Write 方法是否成功,如果不重新设置写超时或取消写超时,后续对 Socket 的写操作都将超时失败
|
||||
|
||||
### socket 并发读写
|
||||
- 可以用,但是没必要
|
||||
- 并发写,写入顺序会乱
|
||||
- 并发读,读取的数据是一部分,业务处理逻辑复杂
|
||||
|
||||
### socket 关闭
|
||||
#### 有数据关闭
|
||||
- 有数据关闭”是指在客户端关闭连接(Socket)时,Socket 中还有服务端尚未读取的数据
|
||||
- 服务端的 Read 会成功将剩余数据读取出来
|
||||
- 最后一次 Read 操作将得到io.EOF错误码
|
||||
|
||||
#### 无数据关闭
|
||||
- 服务端直接读到io.EOF
|
||||
> 客户端关闭 Socket 后,如果服务端 Socket 尚未关闭,这个时候服务端向 Socket 的写入操作依然可能会成功,因为数据会成功写入己方的内核 socket 缓冲区中,即便最终发不到对方 socket 缓冲区
|
||||
427
note/Go/sync_map.md
Normal file
427
note/Go/sync_map.md
Normal file
@ -0,0 +1,427 @@
|
||||
### sync Map 总结
|
||||
- sync.map 是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度
|
||||
- 通过读写分离,降低锁时间来提高效率,适用于读多写少的场景
|
||||
- Range 操作需要提供一个函数,参数是 k,v,返回值是一个布尔值:f func(key, value interface{}) bool
|
||||
- 调用 Load 或 LoadOrStore 函数时,如果在 read 中没有找到 key,则会将 misses 值原子地增加 1,当 misses 增加到和 dirty 的长度相等时,会将 dirty 提升为 read,来减少读miss
|
||||
- 新写入的 key 会保存到 dirty 中,如果这时 dirty 为 nil,就会先新创建一个 dirty,并将 read 中未被删除的元素拷贝到 dirty。
|
||||
- 当 dirty 为 nil 的时候,read 就代表 map 所有的数据;当 dirty 不为 nil 的时候,dirty 才代表 map 所有的数据
|
||||
|
||||
### sync.Map结构
|
||||
```go
|
||||
type Map struct {
|
||||
mu Mutex
|
||||
|
||||
// read contains the portion of the map's contents that are safe for
|
||||
// concurrent access (with or without mu held).
|
||||
// read里边存的是并发访问安全的(持不持有锁都是可以的)
|
||||
//
|
||||
// The read field itself is always safe to load, but must only be stored with
|
||||
// mu held.
|
||||
// load read里边内容总是安全的,但是当你想store进去的时候就必须加mutex 锁
|
||||
|
||||
// Entries stored in read may be updated concurrently without mu, but updating
|
||||
// a previously-expunged entry requires that the entry be copied to the dirty
|
||||
// map and unexpunged with mu held.
|
||||
// 大致意思是更新已经删除的key需要加锁,然后把key放到dirty里边
|
||||
read atomic.Value // readOnly
|
||||
|
||||
// dirty contains the portion of the map's contents that require mu to be
|
||||
// held. To ensure that the dirty map can be promoted to the read map quickly,
|
||||
// it also includes all of the non-expunged entries in the read map.
|
||||
// 为了快速提升dirty为read,dirty中存储了read中未删除的key
|
||||
//
|
||||
// Expunged entries are not stored in the dirty map. An expunged entry in the
|
||||
// clean map must be unexpunged and added to the dirty map before a new value
|
||||
// can be stored to it.
|
||||
//
|
||||
// If the dirty map is nil, the next write to the map will initialize it by
|
||||
// making a shallow copy of the clean map, omitting stale entries.
|
||||
dirty map[interface{}]*entry
|
||||
|
||||
// misses counts the number of loads since the read map was last updated that
|
||||
// needed to lock mu to determine whether the key was present.
|
||||
//
|
||||
// 从read中读取不到key,miss就会加一,加到一定阈值,dirty将被提升为read
|
||||
// Once enough misses have occurred to cover the cost of copying the dirty
|
||||
// map, the dirty map will be promoted to the read map (in the unamended
|
||||
// state) and the next store to the map will make a new dirty copy.
|
||||
misses int
|
||||
}
|
||||
|
||||
// readOnly is an immutable struct stored atomically in the Map.read field.
|
||||
// 不可改变,原子性的存在map的read字段里
|
||||
type readOnly struct {
|
||||
m map[interface{}]*entry
|
||||
amended bool // true if the dirty map contains some key not in m.
|
||||
}
|
||||
|
||||
// expunged is an arbitrary pointer that marks entries which have been deleted
|
||||
// from the dirty map.
|
||||
// 专用来标记 entry已经从dirty中删除
|
||||
var expunged = unsafe.Pointer(new(interface{}))
|
||||
|
||||
// An entry is a slot in the map corresponding to a particular key.
|
||||
// entry存放的就是一个指针,指向value的地址
|
||||
type entry struct {
|
||||
// p points to the interface{} value stored for the entry.
|
||||
//
|
||||
// If p == nil, the entry has been deleted, and either m.dirty == nil or
|
||||
// m.dirty[key] is e.
|
||||
// 地址为nil,表明key已经被删除,要么map的dirty为空,要么dirty[key]是这个entry
|
||||
//
|
||||
// If p == expunged, the entry has been deleted, m.dirty != nil, and the entry
|
||||
// is missing from m.dirty.
|
||||
// 地址是expunged,就表示这个entry已经被删了,并且dirty也已经 不存这个值了
|
||||
//
|
||||
// Otherwise, the entry is valid and recorded in m.read.m[key] and, if m.dirty
|
||||
// != nil, in m.dirty[key].
|
||||
// 其他情况下,就是没有被删除,read[key]为这个p,然后如果dirty不为nil,则ditry[key]也为p
|
||||
//
|
||||
// An entry can be deleted by atomic replacement with nil: when m.dirty is
|
||||
// next created, it will atomically replace nil with expunged and leave
|
||||
// m.dirty[key] unset.
|
||||
// 当删除 key 时,并不实际删除。一个 entry 可以通过原子地(CAS 操作)设置 p 为 nil 被删除。
|
||||
// 如果之后创建 m.dirty,nil 又会被原子地设置为 expunged,且不会拷贝到 dirty 中。
|
||||
//
|
||||
// An entry's associated value can be updated by atomic replacement, provided
|
||||
// p != expunged. If p == expunged, an entry's associated value can be updated
|
||||
// only after first setting m.dirty[key] = e so that lookups using the dirty
|
||||
// map find the entry.
|
||||
// 如果 p 不为 expunged,和 entry 相关联的这个 value 可以被原子地更新;
|
||||
//如果 p == expunged,那么仅当它初次被设置到 m.dirty 之后,才可以被更新
|
||||
p unsafe.Pointer // *interface{}
|
||||
}
|
||||
```
|
||||
> 引用知乎回答的一张图 https://zhuanlan.zhihu.com/p/344834329
|
||||
|
||||

|
||||
|
||||
|
||||
### Load
|
||||
- 读不到返回nil,和false
|
||||
- 读到返回值和ok
|
||||
- read map中不存在key,但是ditry map中有这个key,加锁防止dirty升级为map
|
||||
- 加锁从 dirty中读取key,然后load函数会判断读取到的值是不是expunged(也就是被删除的情况)
|
||||
- 标记miss,以便后续dirty升级为read
|
||||
- miss的数量大于等于dirty的map的数量时,dirty升级为map
|
||||
|
||||
```go
|
||||
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
|
||||
read, _ := m.read.Load().(readOnly)
|
||||
e, ok := read.m[key]
|
||||
// read map中不存在key,但是ditry map中有这个key,加锁防止dirty升级为map
|
||||
// 加锁从 dirty中读取key,然后load函数会判断读取到的值是不是expunged(也就是被删除的情况)
|
||||
// 标记miss,以便后续dirty升级为read
|
||||
// miss的数量大于等于dirty的map的数量时,dirty升级为map
|
||||
if !ok && read.amended {
|
||||
m.mu.Lock()
|
||||
// Avoid reporting a spurious miss if m.dirty got promoted while we were
|
||||
// blocked on m.mu. (If further loads of the same key will not miss, it's
|
||||
// not worth copying the dirty map for this key.)
|
||||
read, _ = m.read.Load().(readOnly)
|
||||
e, ok = read.m[key]
|
||||
if !ok && read.amended {
|
||||
e, ok = m.dirty[key]
|
||||
// Regardless of whether the entry was present, record a miss: this key
|
||||
// will take the slow path until the dirty map is promoted to the read
|
||||
// map.
|
||||
m.missLocked()
|
||||
}
|
||||
m.mu.Unlock()
|
||||
}
|
||||
if !ok {
|
||||
return nil, false
|
||||
}
|
||||
return e.load()
|
||||
}
|
||||
|
||||
func (e *entry) load() (value interface{}, ok bool) {
|
||||
p := atomic.LoadPointer(&e.p)
|
||||
// key 被删除
|
||||
if p == nil || p == expunged {
|
||||
return nil, false
|
||||
}
|
||||
return *(*interface{})(p), true
|
||||
}
|
||||
|
||||
func (m *Map) missLocked() {
|
||||
m.misses++
|
||||
if m.misses < len(m.dirty) {
|
||||
return
|
||||
}
|
||||
m.read.Store(readOnly{m: m.dirty})
|
||||
m.dirty = nil
|
||||
m.misses = 0
|
||||
}
|
||||
```
|
||||
|
||||
### Store
|
||||
- 存储一个key到sync Map
|
||||
- key存在更新
|
||||
- 没读到已经存在read中的key要加锁进行存储
|
||||
|
||||
#### store 流程
|
||||
- 如果在 read 里能够找到待存储的 key,并且对应的 entry 的 p 值不为 expunged,也就是没被删除时,直接更新对应的 entry
|
||||
- 第一步没有成功:要么 read 中没有这个 key,要么 key 被标记为删除。则先加锁,再进行后续的操作。
|
||||
- 再次在 read 中查找是否存在这个 key,也就是 double check 一下
|
||||
- 如果 read 中存在该 key,但 p == expunged,说明 m.dirty != nil 并且 m.dirty 中不存在该 key 值 此时: a. 将 p 的状态由 expunged 更改为 nil;b. dirty map 插入 key。然后,直接更新对应的 value。
|
||||
- 如果 read 中没有此 key,那就查看 dirty 中是否有此 key,如果有,则直接更新对应的 value,这时 read 中还是没有此 key
|
||||
- 最后一步,如果 read 和 dirty 中都不存在该 key,则:a. 如果 dirty 为空,则需要创建 dirty,并从 read 中拷贝未被删除的元素;b. 更新 amended 字段,标识 dirty map 中存在 read map 中没有的 key;c. 将 k-v 写入 dirty map 中,read.m 不变。最后,更新此 key 对应的 value
|
||||
|
||||
```go
|
||||
// Store sets the value for a key.
|
||||
func (m *Map) Store(key, value interface{}) {
|
||||
// read 中可以读到这个key
|
||||
read, _ := m.read.Load().(readOnly)
|
||||
if e, ok := read.m[key]; ok && e.tryStore(&value) {
|
||||
return
|
||||
}
|
||||
|
||||
m.mu.Lock()
|
||||
read, _ = m.read.Load().(readOnly)
|
||||
if e, ok := read.m[key]; ok {
|
||||
if e.unexpungeLocked() {
|
||||
// 过去被删除了,就将这个key存到dirty
|
||||
// The entry was previously expunged, which implies that there is a
|
||||
// non-nil dirty map and this entry is not in it.
|
||||
m.dirty[key] = e
|
||||
}
|
||||
// 原子存指针的值
|
||||
e.storeLocked(&value) //dirty和read都可以读到新存进去的值
|
||||
} else if e, ok := m.dirty[key]; ok {
|
||||
e.storeLocked(&value) // dirty 中存在,就直接存储值
|
||||
} else {
|
||||
// 两边都没读到这个key
|
||||
if !read.amended {
|
||||
// We're adding the first new key to the dirty map.
|
||||
// Make sure it is allocated and mark the read-only map as incomplete.
|
||||
m.dirtyLocked() // 如果dirty为nil,就新建一个dirty,然后把read中没删除的key存到dirty
|
||||
m.read.Store(readOnly{m: read.m, amended: true}) // 标记dirtymap中有read中不存在的key
|
||||
}
|
||||
m.dirty[key] = newEntry(value) // 值存储到dirty,下次load可以取到
|
||||
}
|
||||
m.mu.Unlock()
|
||||
}
|
||||
|
||||
// tryStore stores a value if the entry has not been expunged.
|
||||
//
|
||||
// If the entry is expunged, tryStore returns false and leaves the entry
|
||||
// unchanged.
|
||||
// 如果这个key已经被删除了,就返回了
|
||||
// key 没被删除原子交换entry中p的值
|
||||
func (e *entry) tryStore(i *interface{}) bool {
|
||||
for {
|
||||
p := atomic.LoadPointer(&e.p)
|
||||
if p == expunged {
|
||||
return false
|
||||
}
|
||||
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
|
||||
return true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 如果没有dirtymap的话新建一个,然后把read中没有删除的存到dirty
|
||||
func (m *Map) dirtyLocked() {
|
||||
if m.dirty != nil {
|
||||
return
|
||||
}
|
||||
|
||||
read, _ := m.read.Load().(readOnly)
|
||||
m.dirty = make(map[interface{}]*entry, len(read.m))
|
||||
for k, e := range read.m {
|
||||
if !e.tryExpungeLocked() {
|
||||
m.dirty[k] = e
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// 不是nil,也不是expunged的,也就是正常值才会被放到dirty中
|
||||
func (e *entry) tryExpungeLocked() (isExpunged bool) {
|
||||
p := atomic.LoadPointer(&e.p)
|
||||
for p == nil {
|
||||
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
|
||||
return true
|
||||
}
|
||||
p = atomic.LoadPointer(&e.p)
|
||||
}
|
||||
return p == expunged
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### LoadAndStore
|
||||
```go
|
||||
// LoadOrStore returns the existing value for the key if present.
|
||||
// Otherwise, it stores and returns the given value.
|
||||
// The loaded result is true if the value was loaded, false if stored.
|
||||
func (m *Map) LoadOrStore(key, value interface{}) (actual interface{}, loaded bool) {
|
||||
// Avoid locking if it's a clean hit.
|
||||
// 正产查询
|
||||
read, _ := m.read.Load().(readOnly)
|
||||
if e, ok := read.m[key]; ok {
|
||||
actual, loaded, ok := e.tryLoadOrStore(value)
|
||||
if ok {
|
||||
return actual, loaded
|
||||
}
|
||||
}
|
||||
|
||||
m.mu.Lock()
|
||||
read, _ = m.read.Load().(readOnly)
|
||||
if e, ok := read.m[key]; ok {
|
||||
if e.unexpungeLocked() {
|
||||
// e 为 nil,tryLoadOrStore 可以继续store,而不是直接return
|
||||
m.dirty[key] = e
|
||||
}
|
||||
actual, loaded, _ = e.tryLoadOrStore(value)
|
||||
} else if e, ok := m.dirty[key]; ok {
|
||||
actual, loaded, _ = e.tryLoadOrStore(value)
|
||||
m.missLocked()
|
||||
} else {
|
||||
if !read.amended {
|
||||
// We're adding the first new key to the dirty map.
|
||||
// Make sure it is allocated and mark the read-only map as incomplete.
|
||||
m.dirtyLocked()
|
||||
m.read.Store(readOnly{m: read.m, amended: true})
|
||||
}
|
||||
m.dirty[key] = newEntry(value)
|
||||
actual, loaded = value, false
|
||||
}
|
||||
m.mu.Unlock()
|
||||
|
||||
return actual, loaded
|
||||
}
|
||||
|
||||
// tryLoadOrStore atomically loads or stores a value if the entry is not
|
||||
// expunged.
|
||||
//
|
||||
// If the entry is expunged, tryLoadOrStore leaves the entry unchanged and
|
||||
// returns with ok==false.
|
||||
func (e *entry) tryLoadOrStore(i interface{}) (actual interface{}, loaded, ok bool) {
|
||||
p := atomic.LoadPointer(&e.p)
|
||||
if p == expunged {
|
||||
return nil, false, false
|
||||
}
|
||||
if p != nil {
|
||||
return *(*interface{})(p), true, true
|
||||
}
|
||||
|
||||
// Copy the interface after the first load to make this method more amenable
|
||||
// to escape analysis: if we hit the "load" path or the entry is expunged, we
|
||||
// shouldn't bother heap-allocating.
|
||||
ic := i
|
||||
for {
|
||||
if atomic.CompareAndSwapPointer(&e.p, nil, unsafe.Pointer(&ic)) {
|
||||
return i, false, true
|
||||
}
|
||||
p = atomic.LoadPointer(&e.p)
|
||||
if p == expunged {
|
||||
return nil, false, false
|
||||
}
|
||||
if p != nil {
|
||||
return *(*interface{})(p), true, true
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
### Delete && LoadAndDelete
|
||||
- 查询数据的逻辑同Load
|
||||
- 主要调用LoadAndDelete 方法
|
||||
- 返回val,和一个bool
|
||||
|
||||
```go
|
||||
// LoadAndDelete deletes the value for a key, returning the previous value if any.
|
||||
// The loaded result reports whether the key was present.
|
||||
func (m *Map) LoadAndDelete(key interface{}) (value interface{}, loaded bool) {
|
||||
read, _ := m.read.Load().(readOnly)
|
||||
e, ok := read.m[key]
|
||||
if !ok && read.amended {
|
||||
m.mu.Lock()
|
||||
read, _ = m.read.Load().(readOnly)
|
||||
e, ok = read.m[key]
|
||||
if !ok && read.amended {
|
||||
e, ok = m.dirty[key]
|
||||
delete(m.dirty, key)
|
||||
// Regardless of whether the entry was present, record a miss: this key
|
||||
// will take the slow path until the dirty map is promoted to the read
|
||||
// map.
|
||||
m.missLocked()
|
||||
}
|
||||
m.mu.Unlock()
|
||||
}
|
||||
if ok {
|
||||
return e.delete()
|
||||
}
|
||||
return nil, false
|
||||
}
|
||||
|
||||
// 直接标记成nil
|
||||
func (e *entry) delete() (value interface{}, ok bool) {
|
||||
for {
|
||||
p := atomic.LoadPointer(&e.p)
|
||||
if p == nil || p == expunged {
|
||||
return nil, false
|
||||
}
|
||||
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
|
||||
return *(*interface{})(p), true
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Range
|
||||
- 函数传参一个`func(key, value interface{}) bool`
|
||||
- 函数返回false,结束循环
|
||||
- 如果dirty中存在read中没有的key,加锁将dirty升级为read
|
||||
- 然后循环遍历read
|
||||
|
||||
```go
|
||||
/ Range calls f sequentially for each key and value present in the map.
|
||||
// If f returns false, range stops the iteration.
|
||||
//
|
||||
// Range does not necessarily correspond to any consistent snapshot of the Map's
|
||||
// contents: no key will be visited more than once, but if the value for any key
|
||||
// is stored or deleted concurrently, Range may reflect any mapping for that key
|
||||
// from any point during the Range call.
|
||||
//
|
||||
// Range may be O(N) with the number of elements in the map even if f returns
|
||||
// false after a constant number of calls.
|
||||
func (m *Map) Range(f func(key, value interface{}) bool) {
|
||||
// We need to be able to iterate over all of the keys that were already
|
||||
// present at the start of the call to Range.
|
||||
// If read.amended is false, then read.m satisfies that property without
|
||||
// requiring us to hold m.mu for a long time.
|
||||
read, _ := m.read.Load().(readOnly)
|
||||
if read.amended {
|
||||
// m.dirty contains keys not in read.m. Fortunately, Range is already O(N)
|
||||
// (assuming the caller does not break out early), so a call to Range
|
||||
// amortizes an entire copy of the map: we can promote the dirty copy
|
||||
// immediately!
|
||||
m.mu.Lock()
|
||||
read, _ = m.read.Load().(readOnly)
|
||||
if read.amended {
|
||||
read = readOnly{m: m.dirty}
|
||||
m.read.Store(read)
|
||||
m.dirty = nil
|
||||
m.misses = 0
|
||||
}
|
||||
m.mu.Unlock()
|
||||
}
|
||||
|
||||
for k, e := range read.m {
|
||||
v, ok := e.load()
|
||||
if !ok {
|
||||
continue
|
||||
}
|
||||
if !f(k, v) {
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
77
note/Go/sync包.md
Normal file
77
note/Go/sync包.md
Normal file
@ -0,0 +1,77 @@
|
||||
### sync 包低级同步原语使用场景
|
||||
- 高性能的临界区(critical section)同步机制场景
|
||||
- 不想转移结构体对象所有权,但又要保证结构体内部状态数据的同步访问的场景
|
||||
|
||||
### sync包原语使用注意事项
|
||||
- 不要将原语复制后使用
|
||||
- 用闭包或者传递原语变量的地址(指针)
|
||||
|
||||
### mutex 互斥锁
|
||||
- 零值可用,不用初始化
|
||||
- Lock,Unlock
|
||||
- lock状态下任何goroutine加锁都会阻塞
|
||||
|
||||
### RWMutex 读写锁
|
||||
- 零值可用,不用初始化
|
||||
- RLock,RUnlock 加读锁,解读锁
|
||||
- Lock,Unlock 加写锁,解写锁
|
||||
- 加读锁状态下,不会阻塞加读锁,会阻塞加写锁
|
||||
- 加写锁状态下,会阻塞加读锁与写锁的goroutine
|
||||
|
||||
### sync.Cond 条件变量
|
||||
- sync.Cond是传统的条件变量原语概念在 Go 语言中的实现
|
||||
- 可以把一个条件变量理解为一个容器,这个容器中存放着一个或一组等待着某个条件成立的 Goroutine
|
||||
- 当条件成立后,处于等待状态的 Goroutine 将得到通知,并被唤醒继续进行后续的工作
|
||||
```go
|
||||
type signal struct{}
|
||||
|
||||
var ready bool
|
||||
|
||||
func worker(i int) {
|
||||
fmt.Printf("worker %d: is working...\n", i)
|
||||
time.Sleep(1 * time.Second)
|
||||
fmt.Printf("worker %d: works done\n", i)
|
||||
}
|
||||
|
||||
func spawnGroup(f func(i int), num int, groupSignal *sync.Cond) <-chan signal {
|
||||
c := make(chan signal)
|
||||
var wg sync.WaitGroup
|
||||
|
||||
for i := 0; i < num; i++ {
|
||||
wg.Add(1)
|
||||
go func(i int) {
|
||||
groupSignal.L.Lock()
|
||||
for !ready {
|
||||
groupSignal.Wait()
|
||||
}
|
||||
groupSignal.L.Unlock()
|
||||
fmt.Printf("worker %d: start to work...\n", i)
|
||||
f(i)
|
||||
wg.Done()
|
||||
}(i + 1)
|
||||
}
|
||||
|
||||
go func() {
|
||||
wg.Wait()
|
||||
c <- signal(struct{}{})
|
||||
}()
|
||||
return c
|
||||
}
|
||||
|
||||
func main() {
|
||||
fmt.Println("start a group of workers...")
|
||||
groupSignal := sync.NewCond(&sync.Mutex{})
|
||||
c := spawnGroup(worker, 5, groupSignal)
|
||||
|
||||
time.Sleep(5 * time.Second) // 模拟ready前的准备工作
|
||||
fmt.Println("the group of workers start to work...")
|
||||
|
||||
groupSignal.L.Lock()
|
||||
ready = true
|
||||
groupSignal.Broadcast()
|
||||
groupSignal.L.Unlock()
|
||||
|
||||
<-c
|
||||
fmt.Println("the group of workers work done!")
|
||||
}
|
||||
```
|
||||
23
note/Go/system_command.md
Normal file
23
note/Go/system_command.md
Normal file
@ -0,0 +1,23 @@
|
||||
### 运行系统命令,获取结果,错误信息
|
||||
|
||||
```go
|
||||
func RunCommand(path, name string, arg ...string) (string, string, error) {
|
||||
var err error
|
||||
var msg string
|
||||
cmd := exec.Command(name, arg...)
|
||||
var out bytes.Buffer
|
||||
var stderr bytes.Buffer
|
||||
cmd.Stdout = &out
|
||||
cmd.Stderr = &stderr
|
||||
cmd.Dir = path
|
||||
err = cmd.Run()
|
||||
log.Println(cmd.Args)
|
||||
if err != nil {
|
||||
msg = fmt.Sprint(err) + ": " + stderr.String()
|
||||
err = errors.New(msg)
|
||||
log.Println("err", err.Error(), "cmd", cmd.Args)
|
||||
}
|
||||
log.Println(out.String())
|
||||
return msg, out.String(), nil
|
||||
}
|
||||
```
|
||||
5
note/Go/uintptr_int_unsafe_pointer.md
Normal file
5
note/Go/uintptr_int_unsafe_pointer.md
Normal file
@ -0,0 +1,5 @@
|
||||
### uintptr
|
||||
|
||||
### int
|
||||
|
||||
### unsafe.Pointer
|
||||
51
note/Go/zaxiang.md
Normal file
51
note/Go/zaxiang.md
Normal file
@ -0,0 +1,51 @@
|
||||
### 微信文章待整理
|
||||
- Go 依赖注入 https://mp.weixin.qq.com/s/Do-kTTbyKT4rsAGD3ujKwQ
|
||||
- 结构体多字段原子操作 https://mp.weixin.qq.com/s/Wa1l4M5P89rQ2pyB_KnMxg
|
||||
- 函数调用相关 https://mp.weixin.qq.com/s/Ekx9JpclqLaa4baB6V5rLw https://mp.weixin.qq.com/s/QGp1H6-__pus1Kbb7U8CHw
|
||||
- 泛型 https://mp.weixin.qq.com/s/s9SITQB2xQb4tqmoLaJUpw
|
||||
### 各种nil判断
|
||||
- 切片定义但不初始化,则为nil
|
||||
```go
|
||||
func main() {
|
||||
var s []int
|
||||
fmt.Println(s == nil)
|
||||
}
|
||||
```
|
||||
|
||||
- map定义但是不进行初始化,则为nil
|
||||
```go
|
||||
func main() {
|
||||
var m map[string]int
|
||||
fmt.Println(m == nil)
|
||||
}
|
||||
```
|
||||
|
||||
- 接口变量定义但是不赋初值
|
||||
```go
|
||||
type MyInterface interface {
|
||||
M1(string)
|
||||
}
|
||||
|
||||
func main() {
|
||||
var m MyInterface
|
||||
fmt.Println(m == nil)
|
||||
}
|
||||
```
|
||||
|
||||
- channel定义但是不初始化
|
||||
```go
|
||||
func main() {
|
||||
var ch chan int
|
||||
fmt.Println(ch == nil)
|
||||
}
|
||||
```
|
||||
|
||||
- 指针类型变量没有被显式赋予初值
|
||||
```go
|
||||
type Book struct{}
|
||||
|
||||
func main() {
|
||||
var b *Book
|
||||
fmt.Println(b == nil)
|
||||
}
|
||||
```
|
||||
30
note/Go/代码块.md
Normal file
30
note/Go/代码块.md
Normal file
@ -0,0 +1,30 @@
|
||||
### 代码块
|
||||
- 包裹在一对大括号内部的声明和语句序列
|
||||
- 如果大括号内没有声明和语句序列,则称为`空代码块`
|
||||
- 代码块支持嵌套,可以在一个代码块中嵌入多个层次的代码块
|
||||
|
||||
```go
|
||||
|
||||
func foo() { //代码块1
|
||||
{ // 代码块2
|
||||
{ // 代码块3
|
||||
{ // 代码块4
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 显示代码块
|
||||
- 肉眼可见的大括号包裹
|
||||
|
||||
#### 隐式代码块
|
||||
- 无法通过大括号来识别
|
||||
|
||||

|
||||
|
||||
### 作用域
|
||||
- 针对标识符的,不局限于变量
|
||||
- 一个标识符的作用域就是指这个标识符在被声明后可以被有效使用的源码区域
|
||||
- 作用域是一个编译期的概念,编译器在编译过程中会对每个标识符的作用域进行检查,对于在标识符作用域外使用该标识符的行为会给出编译错误的报错
|
||||
125
note/Go/内存分配.md
Normal file
125
note/Go/内存分配.md
Normal file
@ -0,0 +1,125 @@
|
||||
## 设计原理
|
||||
|
||||
### 内存分配方式
|
||||
|
||||
- 线性分配
|
||||
- 空闲链表分配
|
||||
|
||||
#### 线性分配方式
|
||||
|
||||
- 线性分配(Bump Allocator)是一种高效的内存分配方法。只需要在内存中维护一个指向内存特定位置的指针,如果用户程序向分配器申请内存,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置,即移动下图中的指针:
|
||||
|
||||
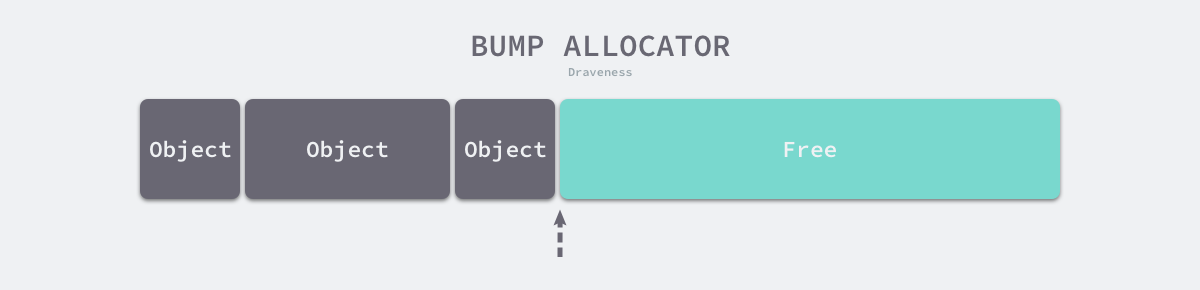
|
||||
|
||||
- 线性分配器实现带来较快的执行速度以及较低的实现复杂度,但是线性分配器无法在内存被释放时重用内存。如下图所示,如果已经分配的内存被回收,线性分配器无法重新利用红色的内存:
|
||||
|
||||
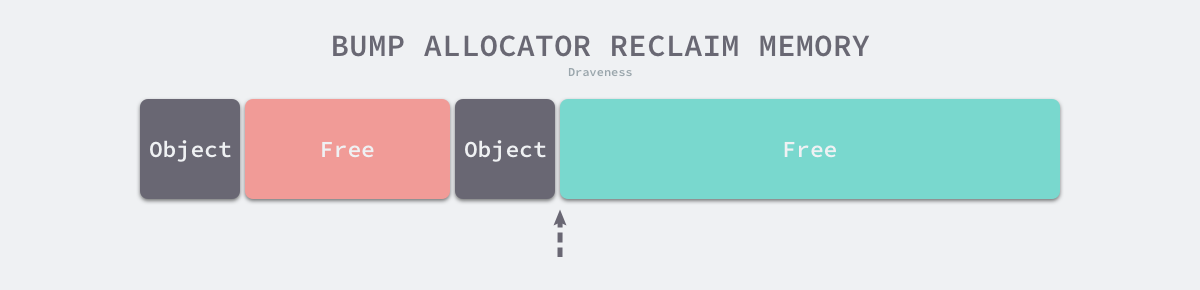
|
||||
|
||||
- 需要与垃圾分配算法配合使用,例如:标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等算法,它们可以通过拷贝的方式整理存活对象的碎片,将空闲内存定期合并,就能利用线性分配器的效率提升内存分配器的性能
|
||||
|
||||
|
||||
|
||||
#### 空闲链表分配方式
|
||||
|
||||
- 空闲链表分配器(Free-List Allocator)可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表:
|
||||
|
||||
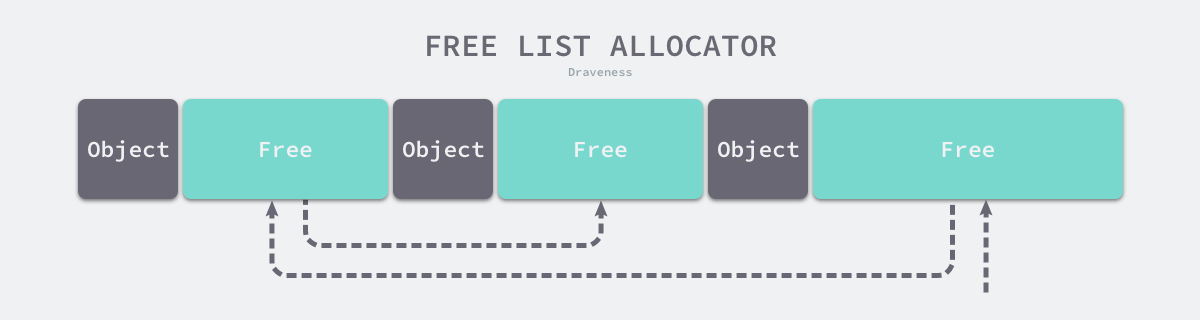
|
||||
|
||||
- 不同的内存块通过指针构成了链表,使用这种方式的分配器可以重新利用回收的资源,分配内存时需要遍历链表,所以它的时间复杂度是 𝑂(𝑛)。空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见的是以下四种:
|
||||
|
||||
- 首次适应(First-Fit)— 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
|
||||
|
||||
- 循环首次适应(Next-Fit)— 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块;
|
||||
|
||||
- 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块;
|
||||
|
||||
- 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块;隔离适应策略如下
|
||||
|
||||
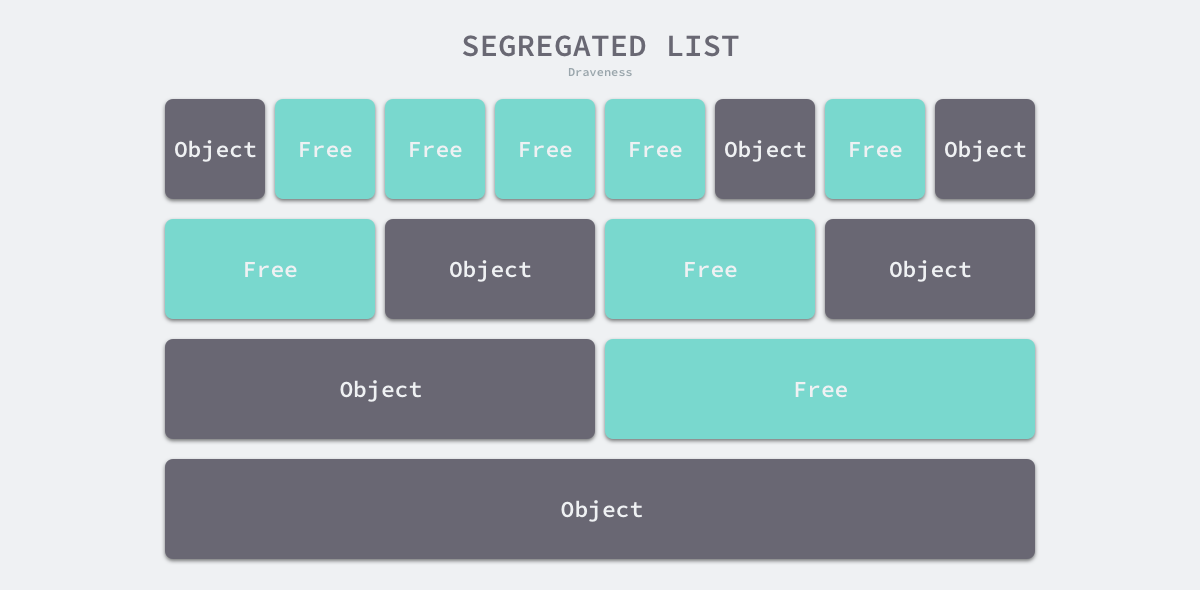
|
||||
|
||||
- 隔离适应策略会将内存分割成由 4、8、16、32 字节的内存块组成的链表,当我们向内存分配器申请 8 字节的内存时,它会在上图中找到满足条件的空闲内存块并返回。隔离适应的分配策略减少了需要遍历的内存块数量,提高了内存分配的效率。
|
||||
|
||||
### 分级分配
|
||||
|
||||
- Go 语言的内存分配器就借鉴了 TCMalloc 的设计实现高速的内存分配,它的核心理念是使用多级缓存将对象根据大小分类,并按照类别实施不同的分配策略
|
||||
|
||||
##### 对象大小
|
||||
|
||||
- Go 语言的内存分配器会根据申请分配的内存大小选择不同的处理逻辑,运行时根据对象的大小将对象分成微对象、小对象和大对象三种:
|
||||
|
||||
| 类别 | 大小 |
|
||||
| :----: | :-----------: |
|
||||
| 微对象 | `(0, 16B)` |
|
||||
| 小对象 | `[16B, 32KB]` |
|
||||
| 大对象 | `(32KB, +∞)` |
|
||||
|
||||
##### 多级缓存
|
||||
|
||||
- 内存分配器不仅会区别对待大小不同的对象,还会将内存分成不同的级别分别管理,TCMalloc 和 Go 运行时分配器都会引入线程缓存(Thread Cache)、中心缓存(Central Cache)和页堆(Page Heap)三个组件分级管理内存:
|
||||
|
||||
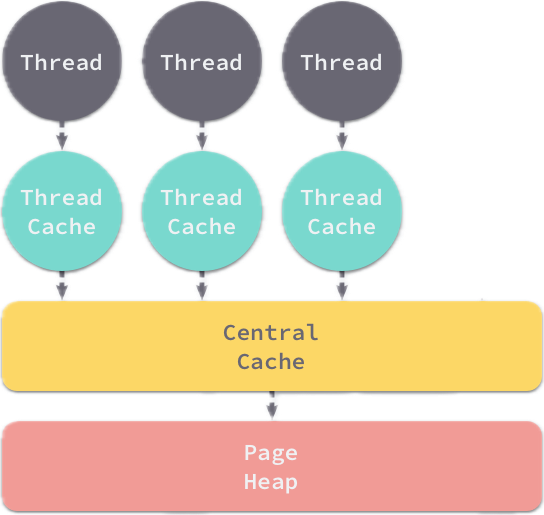
|
||||
|
||||
|
||||
|
||||
#### 虚拟内存布局
|
||||
|
||||
##### Go 1.10及以前连续分配
|
||||
|
||||
- 启动时会初始化整片虚拟内存区域,如下所示的三个区域 `spans`、`bitmap` 和 `arena` 分别预留了 512MB、16GB 以及 512GB 的内存空间,这些内存并不是真正存在的物理内存,而是虚拟内存:
|
||||
|
||||
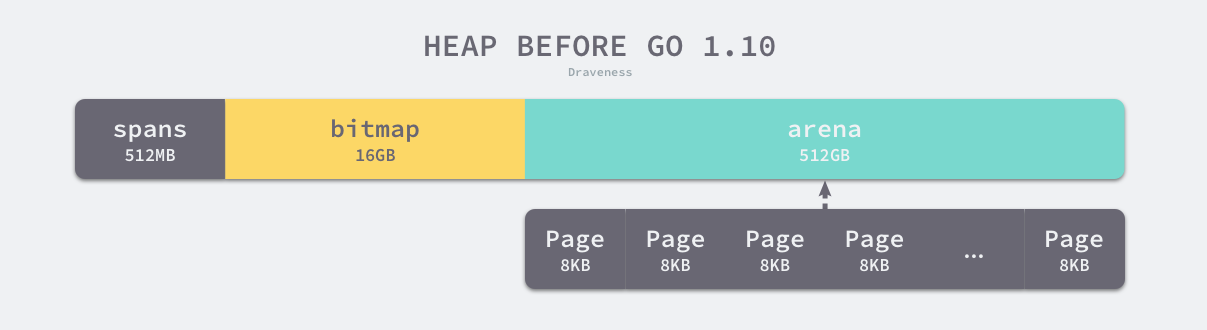
|
||||
|
||||
- `spans` 区域存储了指向内存管理单元 [`runtime.mspan`](https://draveness.me/golang/tree/runtime.mspan) 的指针,每个内存单元会管理几页的内存空间,每页大小为 8KB;
|
||||
- `bitmap` 用于标识 `arena` 区域中的那些地址保存了对象,位图中的每个字节都会表示堆区中的 32 字节是否空闲;
|
||||
- `arena` 区域是真正的堆区,运行时会将 8KB 看做一页,这些内存页中存储了所有在堆上初始化的对象;
|
||||
|
||||
- 对于任意一个地址,都可以根据 `arena` 的基地址计算该地址所在的页数并通过 `spans` 数组获得管理该片内存的管理单元 [`runtime.mspan`](https://draveness.me/golang/tree/runtime.mspan),`spans` 数组中多个连续的位置可能对应同一个 [`runtime.mspan`](https://draveness.me/golang/tree/runtime.mspan) 结构。
|
||||
|
||||
##### Go 1.11以后稀疏分配
|
||||
|
||||
- 稀疏的内存布局能移除堆大小的上限
|
||||
|
||||
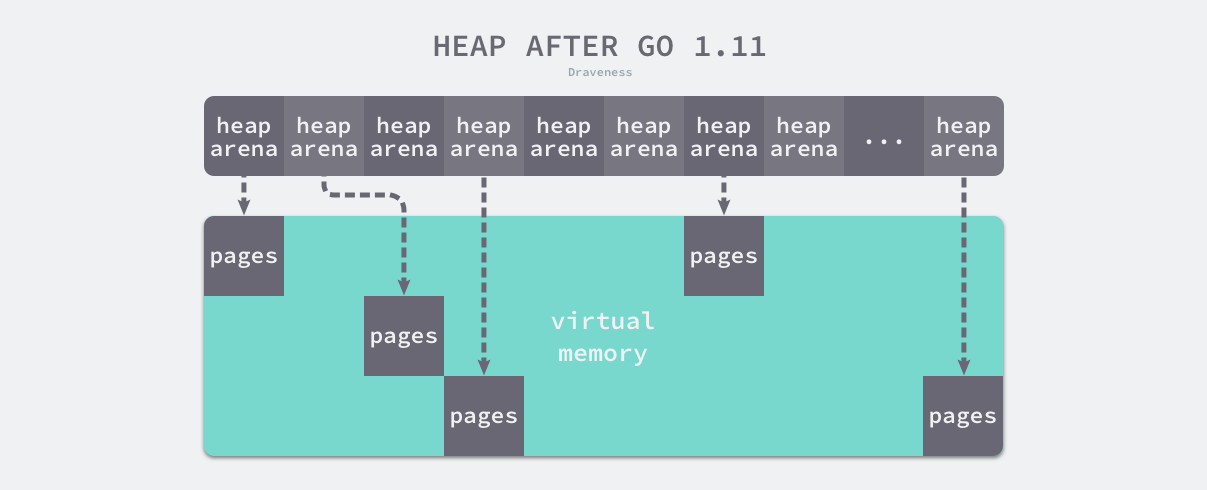
|
||||
|
||||
### 地址空间
|
||||
|
||||
- Go 语言的运行时构建了操作系统的内存管理抽象层,该抽象层将运行时管理的地址空间分成以下四种状态[8](https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/#fn:8):
|
||||
|
||||
| 状态 | 解释 |
|
||||
| :--------: | :----------------------------------------------------------: |
|
||||
| `None` | 内存没有被保留或者映射,是地址空间的默认状态 |
|
||||
| `Reserved` | 运行时持有该地址空间,但是访问该内存会导致错误 |
|
||||
| `Prepared` | 内存被保留,一般没有对应的物理内存访问,该片内存的行为是未定义的可以快速转换到 `Ready` 状态 |
|
||||
| `Ready` | 可以被安全访问 |
|
||||
|
||||
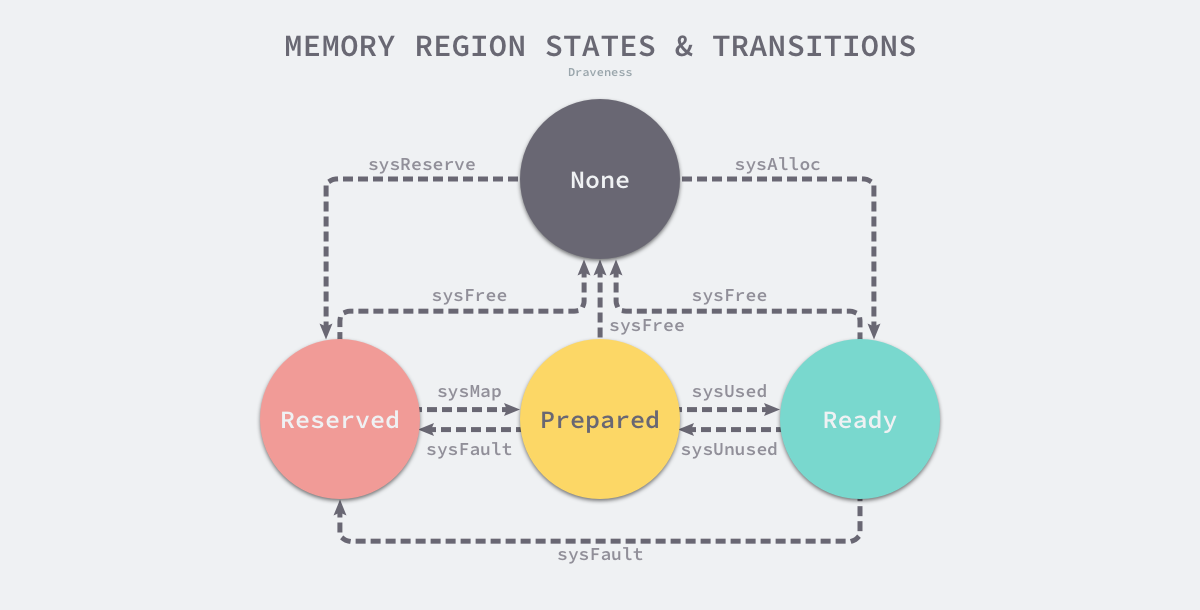
|
||||
|
||||
运行时中包含多个操作系统实现的状态转换方法,所有的实现都包含在以 `mem_` 开头的文件中,本节将介绍 Linux 操作系统对上图中方法的实现:
|
||||
|
||||
- [`runtime.sysAlloc`](https://draveness.me/golang/tree/runtime.sysAlloc) 会从操作系统中获取一大块可用的内存空间,可能为几百 KB 或者几 MB;
|
||||
- [`runtime.sysFree`](https://draveness.me/golang/tree/runtime.sysFree) 会在程序发生内存不足(Out-of Memory,OOM)时调用并无条件地返回内存;
|
||||
- [`runtime.sysReserve`](https://draveness.me/golang/tree/runtime.sysReserve) 会保留操作系统中的一片内存区域,访问这片内存会触发异常;
|
||||
- [`runtime.sysMap`](https://draveness.me/golang/tree/runtime.sysMap) 保证内存区域可以快速转换至就绪状态;
|
||||
- [`runtime.sysUsed`](https://draveness.me/golang/tree/runtime.sysUsed) 通知操作系统应用程序需要使用该内存区域,保证内存区域可以安全访问;
|
||||
- [`runtime.sysUnused`](https://draveness.me/golang/tree/runtime.sysUnused) 通知操作系统虚拟内存对应的物理内存已经不再需要,可以重用物理内存;
|
||||
- [`runtime.sysFault`](https://draveness.me/golang/tree/runtime.sysFault) 将内存区域转换成保留状态,主要用于运行时的调试;
|
||||
|
||||
运行时使用 Linux 提供的 `mmap`、`munmap` 和 `madvise` 等系统调用实现了操作系统的内存管理抽象层,抹平了不同操作系统的差异,为运行时提供了更加方便的接口,除了 Linux 之外,运行时还实现了 BSD、Darwin、Plan9 以及 Windows 等平台上抽象层
|
||||
|
||||
|
||||
|
||||
## 内存管理组件
|
||||
|
||||
- 内存管理单元 runtime.mspan
|
||||
- 线程缓存 runtime.mcache
|
||||
- 中心缓存 runtime.mcentral
|
||||
- 页堆 runtime.mheap
|
||||
|
||||
### Go内存布局
|
||||
|
||||
|
||||
|
||||
- 每一个处理器都会分配一个线程缓存 [`runtime.mcache`](https://draveness.me/golang/tree/runtime.mcache) 用于处理微对象和小对象的分配,它们会持有内存管理单元 [`runtime.mspan`](https://draveness.me/golang/tree/runtime.mspan)
|
||||
|
||||
- 每个类型的内存管理单元都会管理特定大小的对象,当内存管理单元中不存在空闲对象时,它们会从 [`runtime.mheap`](https://draveness.me/golang/tree/runtime.mheap) 持有的 134 个中心缓存 [`runtime.mcentral`](https://draveness.me/golang/tree/runtime.mcentral) 中获取新的内存单元,中心缓存属于全局的堆结构体 [`runtime.mheap`](https://draveness.me/golang/tree/runtime.mheap),它会从操作系统中申请内存
|
||||
- 在 amd64 的 Linux 操作系统上,[`runtime.mheap`](https://draveness.me/golang/tree/runtime.mheap) 会持有 4,194,304 [`runtime.heapArena`](https://draveness.me/golang/tree/runtime.heapArena),每个 [`runtime.heapArena`](https://draveness.me/golang/tree/runtime.heapArena) 都会管理 64MB 的内存,单个 Go 语言程序的内存上限也就是 256TB。
|
||||
57
note/Go/函数.md
Normal file
57
note/Go/函数.md
Normal file
@ -0,0 +1,57 @@
|
||||
### 函数参数
|
||||
- 实际参数:函数实际调用时传入的参数
|
||||
- 形式参数:把参数列表中的参数
|
||||

|
||||
|
||||
### 传参
|
||||
- 函数参数传递采用是值传递的方式
|
||||
- 所谓“值传递”,就是将实际参数在内存中的表示逐位拷贝(Bitwise Copy)到形式参数中
|
||||
- 对于像整型、数组、结构体这类类型,它们的内存表示就是它们自身的数据内容,因此当这些类型作为实参类型时,值传递拷贝的就是它们自身,传递的开销也与它们自身的大小成正比
|
||||
- 像 string、切片、map 这些类型它们的内存表示对应的是它们数据内容的“描述符”。当这些类型作为实参类型时,值传递拷贝的也是它们数据内容的“描述符”,不包括数据内容本身,所以这些类型传递的开销是固定的,与数据内容大小无关
|
||||
|
||||
### 函数传参例外
|
||||
- 对于类型为接口类型的形参,Go 编译器会把传递的实参赋值给对应的接口类型形参
|
||||
- 对于为变长参数的形参,Go 编译器会将零个或多个实参按一定形式转换为对应的变长形参
|
||||
- 变长参数实际上是通过切片来实现
|
||||
|
||||
### Go函数特征
|
||||
- 多个可以命名的返回值
|
||||
- 函数可以存储在变量中
|
||||
- 支持在函数内创建并通过返回值返回
|
||||
- 可以作为参数传入函数
|
||||
- 拥有自己的类型`type HandlerFunc func(ResponseWriter, *Request)`
|
||||
|
||||
### 函数健壮性原则
|
||||
- 不要相信任何外部输入的参数
|
||||
- 不要忽略任何一个错误
|
||||
- 不要假定异常不会发生
|
||||
|
||||
### defer 获取调用函数方法名
|
||||
- runtime.Caller,参数为0时,返回调用者本身的信息(Trace的信息),为1是返回调用调用者的信息(调用Trace的信息)
|
||||
- Caller 函数有四个返回值:
|
||||
- 第一个返回值代表的是程序计数(pc)
|
||||
- 第二个和第三个参数代表对应函数所在的源文件名以及所在行数
|
||||
- 最后一个参数代表是否能成功获取这些信息
|
||||
- runtime.FuncForPC 函数和程序计数器(PC)得到被跟踪函数的函数信息
|
||||
```go
|
||||
|
||||
// trace1/trace.go
|
||||
|
||||
func Trace() func() {
|
||||
pc, _, _, ok := runtime.Caller(1)
|
||||
if !ok {
|
||||
panic("not found caller")
|
||||
}
|
||||
|
||||
fn := runtime.FuncForPC(pc)
|
||||
name := fn.Name()
|
||||
|
||||
println("enter:", name)
|
||||
return func() { println("exit:", name) }
|
||||
}
|
||||
|
||||
func main() {
|
||||
defer Trace()()
|
||||
foo()
|
||||
}
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user